如何收集 NGINX 指标(第二篇)
译自:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
作者: K Young
原创:LCTT https://linux.cn/article-5985-1.html
译者: struggling

如何获取你所需要的 NGINX 指标
如何获取需要的指标取决于你正在使用的 NGINX 版本以及你希望看到哪些指标。(参见 如何监控 NGINX(第一篇) 来深入了解NGINX指标。)自由开源的 NGINX 和商业版的 NGINX Plus 都有可以报告指标度量的状态模块,NGINX 也可以在其日志中配置输出特定指标:
指标可用性
| 指标 | NGINX (开源) | NGINX Plus | NGINX 日志 |
|---|---|---|---|
| accepts(接受) / accepted(已接受) | x | x | |
| handled(已处理) | x | x | |
| dropped(已丢弃) | x | x | |
| active(活跃) | x | x | |
| requests (请求数)/ total(全部请求数) | x | x | |
| 4xx 代码 | x | x | |
| 5xx 代码 | x | x | |
| request time(请求处理时间) | x |
指标收集:NGINX(开源版)
开源版的 NGINX 会在一个简单的状态页面上显示几个与服务器状态有关的基本指标,它们由你启用的 HTTP stub status module 所提供。要检查该模块是否已启用,运行以下命令:
nginx -V 2>&1 | grep -o with-http_stub_status_module
如果你看到终端输出了 httpstubstatus_module,说明该状态模块已启用。
如果该命令没有输出,你需要启用该状态模块。你可以在从源代码构建 NGINX 时使用 --with-http_stub_status_module 配置参数:
./configure \
… \
--with-http_stub_status_module
make
sudo make install
在验证该模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件,来给状态页面设置一个本地可访问的 URL(例如: /nginx_status):
server {
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
}
注:nginx 配置中的 server 块通常并不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置会加载的辅助配置文件中。要找到主配置文件,首先运行以下命令:
nginx -t
打开列出的主配置文件,在以 http 块结尾的附近查找以 include 开头的行,如:
include /etc/nginx/conf.d/*.conf;
在其中一个包含的配置文件中,你应该会找到主 server 块,你可以如上所示配置 NGINX 的指标输出。更改任何配置后,通过执行以下命令重新加载配置文件:
nginx -s reload
现在,你可以浏览状态页看到你的指标:
Active connections: 24
server accepts handled requests
1156958 1156958 4491319
Reading: 0 Writing: 18 Waiting : 6
请注意,如果你希望从远程计算机访问该状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中的白名单仅有 127.0.0.1。
NGINX 的状态页面是一种快速查看指标状况的简单方法,但当连续监测时,你需要按照标准间隔自动记录该数据。监控工具箱 Nagios 或者 Datadog,以及收集统计信息的服务 collectD 已经可以解析 NGINX 的状态信息了。
指标收集: NGINX Plus
商业版的 NGINX Plus 通过它的 ngxhttpstatus_module 提供了比开源版 NGINX 更多的指标。NGINX Plus 以字节流的方式提供这些额外的指标,提供了关于上游系统和高速缓存的信息。NGINX Plus 也会报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个 NGINX Plus 状态报告例子可在此查看:
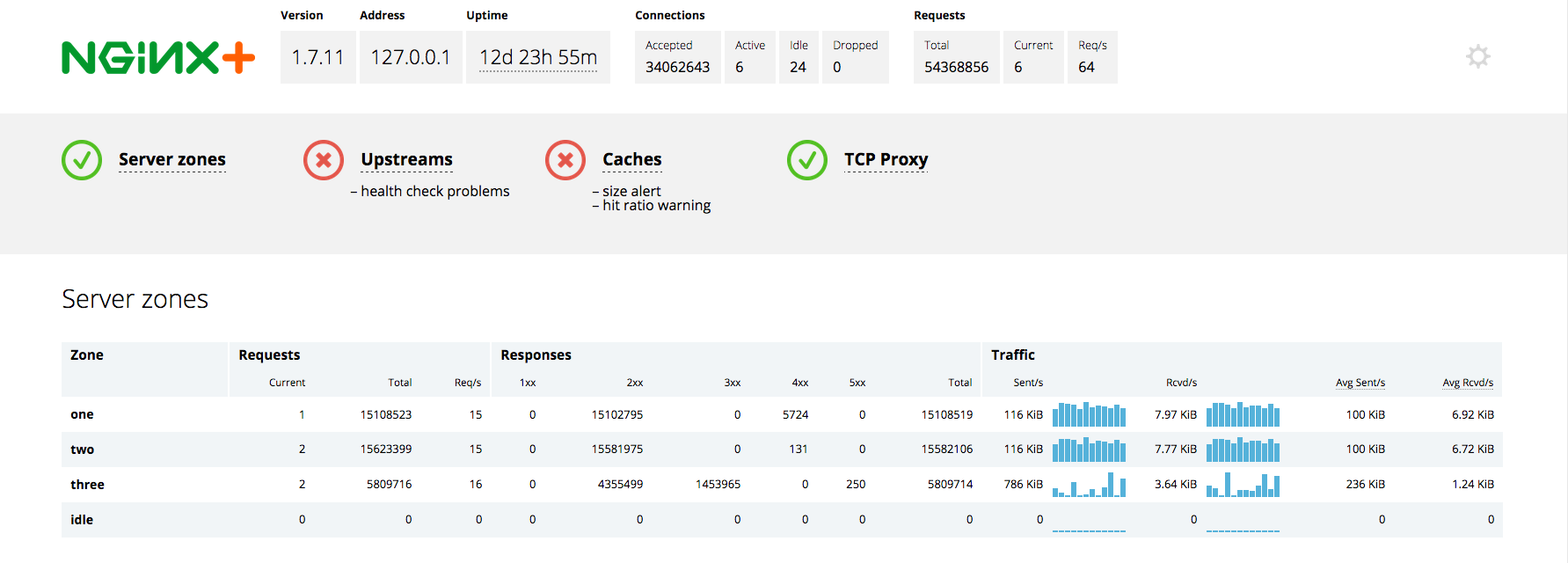
注:NGINX Plus 在状态仪表盘中的“Active”连接的定义和开源 NGINX 通过 stubstatusmodule 收集的“Active”连接指标略有不同。在 NGINX Plus 指标中,“Active”连接不包括Waiting状态的连接(即“Idle”连接)。
NGINX Plus 也可以输出 JSON 格式的指标,可以用于集成到其他监控系统。在 NGINX Plus 中,你可以看到 给定的上游服务器组的指标和健康状况,或者简单地从上游服务器的单个服务器得到响应代码的计数:
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
要启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 (参见上一节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。)例如,要设置一个状态仪表盘 (http://your.ip.address:8080/status.html)和一个 JSON 接口(http://your.ip.address:8080/status),可以添加以下 server 块来设定:
server {
listen 8080;
root /usr/share/nginx/html;
location /status {
status;
}
location = /status.html {
}
}
当你重新加载 NGINX 配置后,状态页就可以用了:
nginx -s reload
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 详细介绍 。
指标收集:NGINX 日志
NGINX 的 日志模块 会把可自定义的访问日志写到你配置的指定位置。你可以通过添加或移除变量来自定义日志的格式和包含的数据。要存储详细的日志,最简单的方法是添加下面一行在你配置文件的 server 块中(参见上上节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。):
access_log logs/host.access.log combined;
更改 NGINX 配置文件后,执行如下命令重新加载配置文件:
nginx -s reload
默认包含的 “combined” 的日志格式,会包括一系列关键的数据,如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了请求 /index.html 时的 200(成功)状态码和访问不存在的请求文件 /fail 的 404(未找到)错误。
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
你可以通过在 NGINX 配置文件中的 http 块添加一个新的日志格式来记录请求处理时间:
log_format nginx '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent $request_time '
'"$http_referer" "$http_user_agent"';
并修改配置文件中 server 块的 access_log 行:
access_log logs/host.access.log nginx;
重新加载配置文件后(运行 nginx -s reload),你的访问日志将包括响应时间,如下所示。单位为秒,精度到毫秒。在这个例子中,服务器接收到一个对 /big.pdf 的请求时,发送 33973115 字节后返回 206(成功)状态码。处理请求用时 0.202 秒(202毫秒):
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
你可以使用各种工具和服务来解析和分析 NGINX 日志。例如,rsyslog 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用自由开源工具,比如 logstash 来收集和分析日志;或者你可以使用一个统一日志记录层,如 Fluentd 来收集和解析你的 NGINX 日志。
结论
监视 NGINX 的哪一项指标将取决于你可用的工具,以及监控指标所提供的信息是否满足你们的需要。举例来说,错误率的收集是否足够重要到需要你们购买 NGINX Plus ,还是架设一个可以捕获和分析日志的系统就够了?
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。在本文中了解如何用 NGINX Datadog 来监控 ,并开始 Datadog 的免费试用吧。
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
作者:K Young 译者:strugglingyouth 校对:wxy