LFCS 系列第一讲:如何在 Linux 上使用 GNU sed 等命令来创建、编辑和操作文件
译自:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
作者: Gabriel Cánepa
原创:LCTT https://linux.cn/article-7161-1.html
译者: 漩涡
Linux 基金会宣布了一个全新的 LFCS(Linux 基金会认证系统管理员)认证计划。这一计划旨在帮助遍布全世界的人们获得其在处理 Linux 系统管理任务上能力的认证。这些能力包括支持运行的系统服务,以及第一手的故障诊断、分析,以及为工程师团队在升级时提供明智的决策。

Linux 基金会认证系统管理员——第一讲
请观看下面关于 Linux 基金会认证计划的演示:
该系列将命名为《LFCS 系列第一讲》至《LFCS 系列第十讲》并覆盖关于 Ubuntu、CentOS 以及 openSUSE 的下列话题。
- 第一讲:如何在 Linux 上使用 GNU sed 等命令来创建、编辑和操作文件
- 第二讲:如何安装和使用 vi/m 全功能文字编辑器
- 第三讲:归档文件/目录并在文件系统中寻找文件
- 第四讲:为存储设备分区,格式化文件系统和配置交换分区
- 第五讲:在 Linux 中挂载/卸载本地和网络(Samba & NFS)文件系统
- 第六讲:组合分区作为 RAID 设备——创建&管理系统备份
- 第七讲:管理系统启动进程和服务(使用 SysVinit, Systemd 和 Upstart)
- 第八讲:管理用户和组,文件权限和属性以及启用账户的 sudo 权限
- 第九讲:用 Yum,RPM,Apt,Dpkg,Aptitude,Zypper 进行 Linux 软件包管理
- 第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
重要提示:由于自 2016/2 开始 LFCS 认证要求有所变化,我们增加发布了下列必需的内容。要准备这个考试,推荐你也看看我们的 LFCE 系列。
- 第十一讲:怎样使用 vgcreate、lvcreate 和 lvextend 命令创建和管理 LVM
- 第十二讲:怎样安装帮助文档和工具来探索 Linux
- 第十三讲:怎样配置和排错 GRUB
本文是覆盖这个参加 LFCS 认证考试的所必需的范围和技能的十三个教程的第一讲。话说了那么多,快打开你的终端,让我们开始吧!
处理 Linux 中的文本流
Linux 将程序中的输入和输出当成字符流或者字符序列。在开始理解重定向和管道之前,我们必须先了解三种最重要的I/O(输入和输出)流,事实上,它们都是特殊的文件(根据 UNIX 和 Linux 中的约定,数据流和外围设备(设备文件)也被视为普通文件)。
在 > (重定向操作符) 和 | (管道操作符)之间的区别是:前者将命令与文件相连接,而后者将命令的输出和另一个命令相连接。
# command > file
# command1 | command2
由于重定向操作符会静默地创建或覆盖文件,我们必须特别小心谨慎地使用它,并且永远不要把它和管道混淆起来。在 Linux 和 UNIX 系统上管道的优势是:第一个命令的输出不会写入一个文件而是直接被第二个命令读取。
在下面的操作练习中,我们将会使用这首诗——《A happy child》(作者未知)
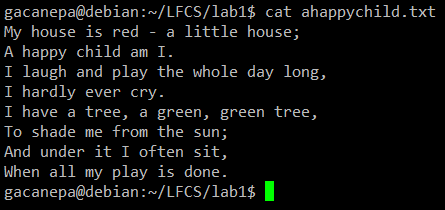
cat 命令样例
使用 sed
sed 是流编辑器的缩写。为那些不懂术语的人额外解释一下,流编辑器是用来在一个输入流(文件或者管道中的输入)执行基本的文本转换的工具。
sed 最基本的用法是字符替换。我们将通过把每个出现的小写 y 改写为大写 Y 并且将输出重定向到 ahappychild2.txt 开始。g 标志表示 sed 应该替换文件每一行中所有应当替换的实例。如果这个标志省略了,sed 将会只替换每一行中第一次出现的实例。
基本语法:
# sed 's/term/replacement/flag' file
我们的样例:
# sed 's/y/Y/g' ahappychild.txt > ahappychild2.txt
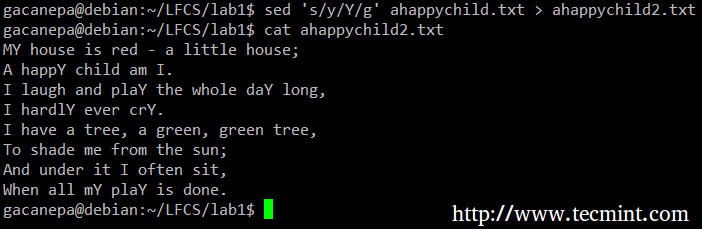
sed 命令样例
如果你要在替换文本中搜索或者替换特殊字符(如 /,\,&),你需要使用反斜杠对它进行转义。
例如,我们要用一个符号来替换一个文字,与此同时我们将把一行最开始出现的第一个 I 替换为 You。
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
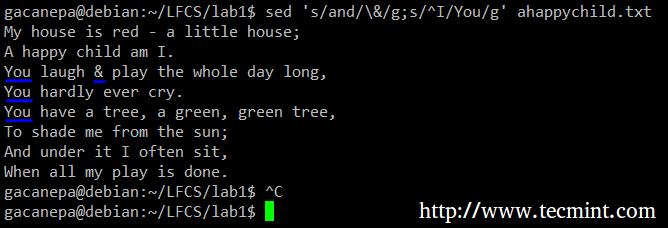
sed 替换字符串
在上面的命令中,众所周知 ^(插入符号)是正则表达式中用来表示一行开头的符号。
正如你所看到的,我们可以通过使用分号分隔以及用括号包裹来把两个或者更多的替换命令(并在它们中使用正则表达式)连接起来。
另一种 sed 的用法是显示或者删除文件中选中的一部分。在下面的样例中,将会显示 /var/log/messages 中从6月8日开始的头五行。
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
请注意,在默认的情况下,sed 会打印每一行。我们可以使用 -n 选项来覆盖这一行为并且告诉 sed 只需要打印(用 p来表示)文件(或管道)中匹配的部分(第一个命令中指定以“Jun 8” 开头的行,第二个命令中指定一到五行)。
最后,可能有用的技巧是当检查脚本或者配置文件的时候可以保留文件本身并且删除注释。下面的单行 sed 命令删除(d)空行或者是开头为#的行(| 字符对两个正则表达式进行布尔 OR 操作)。
# sed '/^#\|^$/d' apache2.conf
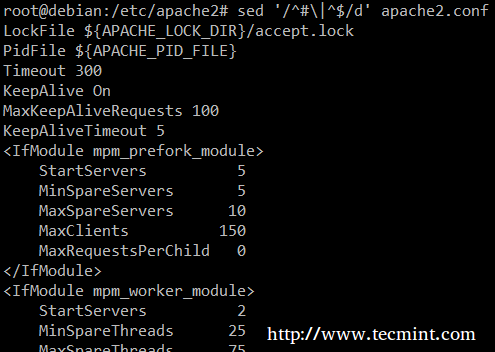
sed 匹配字符串
uniq 命令
uniq 命令允许我们返回或者删除文件中重复的行,默认写到标准输出。我们必须注意到,除非两个重复的行相邻,否则uniq 命令不会删除他们。因此,uniq 经常和一个前置的 sort 命令(一种用来对文本行进行排序的算法)搭配使用。默认情况下,sort 使用第一个字段(用空格分隔)作为关键字段。要指定一个不同的关键字段,我们需要使用 -k 选项。
样例
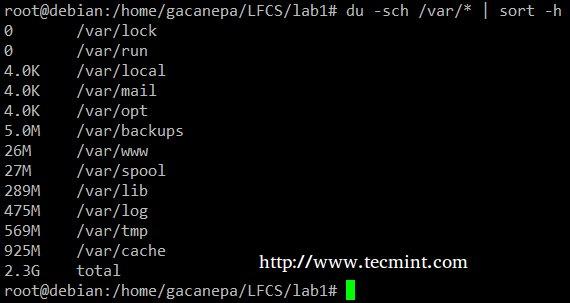
du –sch /path/to/directory/* 命令将会以人类可读的格式返回在指定目录下每一个子文件夹和文件的磁盘空间使用情况(也会显示每个目录总体的情况),而且不是按照大小输出,而是按照子文件夹和文件的名称。我们可以使用下面的命令来让它通过大小排序。
# du -sch /var/* | sort -h
sort 命令样例
你可以通过使用下面的命令告诉 uniq 比较每一行的前6个字符(-w 6)(这里是指定的日期)来统计日志事件的个数,而且在每一行的开头输出出现的次数(-c)。
# cat /var/log/mail.log | uniq -c -w 6

文件中的统计数字
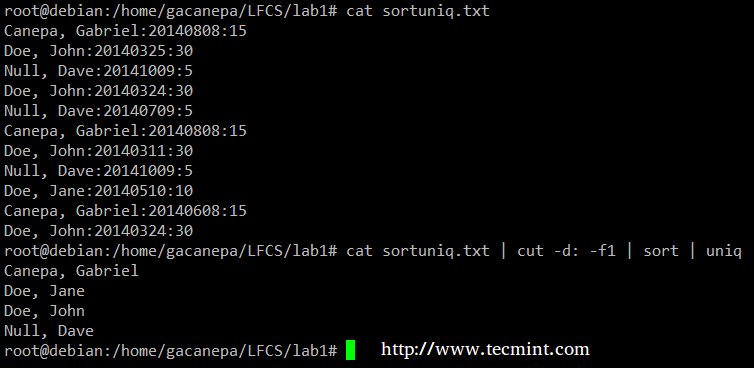
最后,你可以组合使用 sort 和 uniq 命令(通常如此)。看看下面文件中捐助者、捐助日期和金额的列表。假设我们想知道有多少个捐助者。我们可以使用下面的命令来分隔第一字段(字段由冒号分隔),按名称排序并且删除重复的行。
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
寻找文件中不重复的记录
- 也可阅读: 13个“cat”命令样例
grep 命令
grep 在文件(或命令输出)中搜索指定正则表达式,并且在标准输出中输出匹配的行。
样例
显示文件 /etc/passwd 中用户 gacanepa 的信息,忽略大小写。
# grep -i gacanepa /etc/passwd

grep 命令样例
显示 /etc 文件夹下所有 rc 开头并跟随任意数字的内容。
# ls -l /etc | grep rc[0-9]

使用 grep 列出内容
- 也可阅读: 12个“grep”命令样例
tr 命令使用技巧
tr 命令可以用来从标准输入中转换(改变)或者删除字符,并将结果写入到标准输出中。
样例
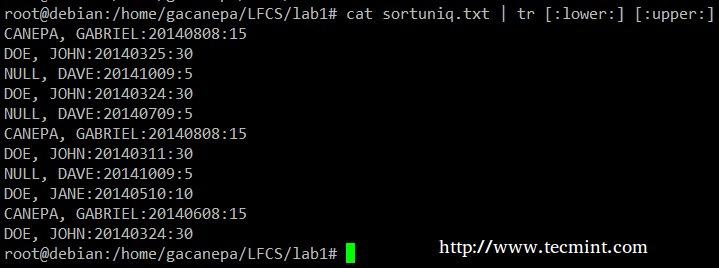
把 sortuniq.txt 文件中所有的小写改为大写。
# cat sortuniq.txt | tr [:lower:] [:upper:]
排序文件中的字符串
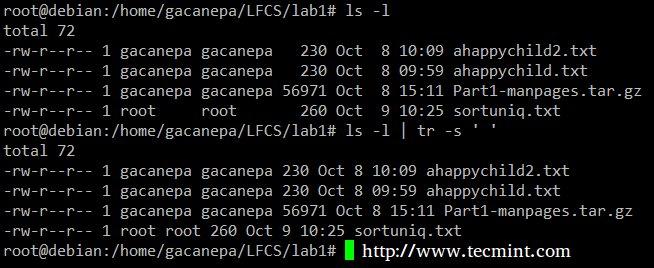
压缩ls –l输出中的分隔符为一个空格。
# ls -l | tr -s ' '
压缩分隔符
cut 命令使用方法
cut 命令可以基于字节(-b选项)、字符(-c)或者字段(-f)提取部分输入(从标准输入或者文件中)并且将结果输出到标准输出。在最后一种情况下(基于字段),默认的字段分隔符是一个制表符,但可以由 -d 选项来指定不同的分隔符。
样例
从 /etc/passwd 中提取用户账户和他们被分配的默认 shell(-d 选项允许我们指定分界符,-f 选项指定那些字段将被提取)。
# cat /etc/passwd | cut -d: -f1,7
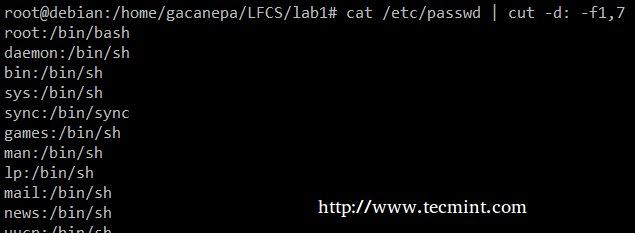
提取用户账户
将以上命令结合起来,我们将使用 last 命令的输出中第一和第三个非空文件创建一个文本流。我们将使用 grep 作为第一过滤器来检查用户 gacanepa 的会话,然后将分隔符压缩至一个空格(tr -s ' ')。下一步,我们将使用 cut 来提取第一和第三个字段,最后使用第二个字段(本样例中,指的是IP地址)来排序之后,再用 uniq 去重。
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
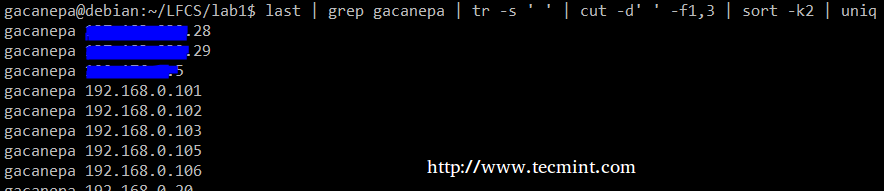
last 命令样例
上面的命令显示了如何将多个命令和管道结合起来,以便根据我们的要求得到过滤后的数据。你也可以逐步地使用它以帮助你理解输出是如何从一个命令传输到下一个命令的(顺便说一句,这是一个非常好的学习经验!)
总结
尽管这个例子(以及在当前教程中的其他实例)第一眼看上去可能不是非常有用,但是他们是体验在 Linux 命令行中创建、编辑和操作文件的一个非常好的开始。请随时留下你的问题和意见——不胜感激!
参考链接
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
作者:Gabriel Cánepa 译者:Xuanwo 校对:wxy