
引言
但凡是千禧年之前出生的国人,心里大体都有一个武侠情结,那是一个由金庸、古龙的一本本武侠小说以及港台武侠剧堆砌出来的武林世界。虽说现在的电影可以发达到让观众看到各种奇幻特效,但回味起来,似乎还不如金庸笔下一个令狐冲给江湖朝堂带来的翻覆动荡刺激。
侠骨文心笑看云霄飘一羽, 孤怀统揽曾经沧海慨平生,武侠的迷人在于一个个小人物不单单被分成正邪两派,每个人都有自己的独立意志,通过不懈努力,最终得以在江湖这个大舞台上各展身手,江山人才代出,各领风骚数年,刀光剑影间,让人大呼好不过瘾。
计算机技术领域,何尝又不是一个江湖。往具体了说,比如有 Windows 和 Linux 系统级别的缠斗;往抽象了说,有私有云和IOE的概念对垒等。虽说技术不像侠客论剑般交手那么直接,但是背后的暗潮涌动还是能让人嗅到一丝火花的气息。
今天我们要讨论的当然不是江湖,而是要掰扯掰扯“数据湖”。
数据湖下的两大派系
数据湖这一概念最早应该是在 2011 年由 CITO Research 网站的 CTO 和作家 Dan Woods 提出。简单来说,数据湖是一个信息系统,并且符合下面两个特征:
- 一个可以存储大数据的并行系统
- 可以在不需要另外移动数据的情况下进行数据计算
在我的理解中,目前的数据湖形态大体分为以下三种:
计算存储一家亲

计算资源和存储资源整合在一起,以一个集群来应对不同业务需求。可以想象,如果后期公司体量增大,不同的业务线对数据湖有不同的计算需求,业务之前会存在对计算资源的争抢;同时,后期扩容时,计算和存储得相应地一同扩展,也不是那么的方便。
计算存储一家亲 Pro
为了应对上述方案中的资源争抢问题,一般的解决方案就是为每个业务线分配一个数据湖,集群的隔离能够让每个业务线有自己的计算资源,可以保证很好的业务隔离性。但是随之而来的问题也是显而易见的:数据孤岛。试想几个业务线可能需要同一个数据集来完成各自的分析,但是由于存储集群也被一个个分开,那么势必需要将这个数据集挨个复制到各个集群中去。如此,数据的冗余就太大了,存储开销太大。同时,计算和存储的扩容问题也仍然存在。
计算存储分家
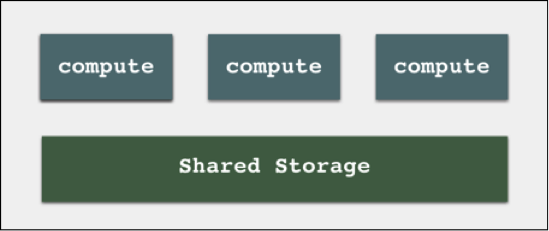
俗话说的好,距离产生美。在这个模式中,计算和存储被分隔开来。每个业务线可以有自己的计算集群,来满足其业务需求。而后台都指向同一个共享存储池,由此解决了第二个方案中的数据冗余问题。并且由于计算、存储分离,在后期扩容时,也可以各自分别扩容。这一分离性也符合弹性计算的特征,让按需分配成为可能。
我们将方案一和方案二可以归为“计算存储融合”这一派系,目前最有代表的应该就是 Hadoop 的 HDFS,这套大数据默认的存储后台有着高容错、易扩展等优点,十分适合部署在廉价设备上;而方案三可以单独拿出来,归为“计算存储分离”派系,最有代表的是 Amazon EMR。EMR 借助 AWS 得天独厚的云计算能力,并且辅以 S3 对象存储支持,让大数据分析变得十分简单、便宜。
在私有云场景中,我们一般会采用虚拟化技术来创建一个个计算集群,来支持上层大数据应用的计算需求。存储这边一般采用 Ceph 的对象存储服务来提供数据湖的共享存储后台,然后通过S3A来提供两者之间的连接,能够让Hadoop的应用能够无缝访问 Ceph 对象存储服务。

综上所述,我们可以看到在“数据湖”这一概念下,其实隐约已经分成了两个派系:“计算存储融合”, “计算存储分离”。下面,让我们谈谈这两个派系的优缺点。
青梅煮酒
在这一节,我们会把“计算存储融合”和“计算存储分离”这两个框架摆上台面,来讨论一下他们各自的优缺点。
计算存储融合 – HDFS
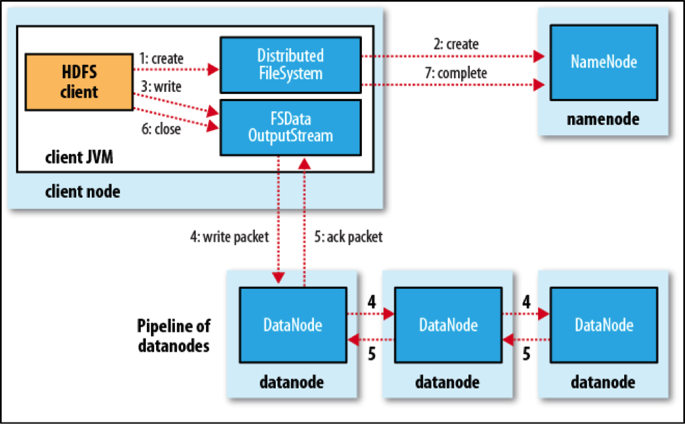
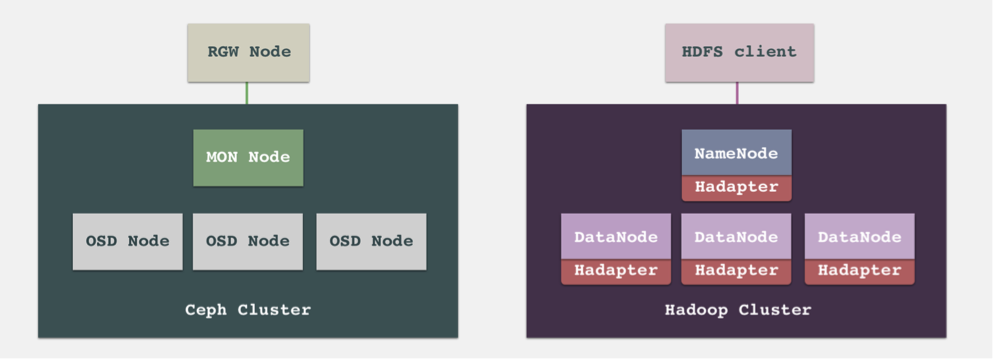
HDFS 客户端往 HDFS 写入数据时,一般分为以下几个简要步骤:
- HDFS 客户端向 NameNode 发送一条创建文件的请求
- NameNode 遍历查看后,验证该文件为新文件,随后响应客户端准许上传
- HDFS 客户端根据默认 block size 和要上传文件的大小,来对文件做切分。比如 default block size 是 128M, 而上传文件是 300M,那么文件就会被分割成 3 个 block。
- 客户端请求上传 block,NameNode 通过分析集群情况,返回该 block 需要上传的 DataNode。由于默认 HDFS 的冗余策略是三副本,那么就会返回 3 个 DataNode 地址。
- 客户端通过建立 pipeline,向对应的 DataNode 上传 block 数据。
- 当一个 block 上传到 3 个 DataNode 后,客户端准备发送第二个 block,由此往复,直到文件传输完毕。
HDFS 读取数据步骤不在此赘述。对于 HDFS 写入数据的步骤,我认为重要比较重要的有以下几点:
- 创建文件、上传 block 时需要先访问 NameNode
- NameNode 上存放了文件对应的元数据、block 信息
- HDFS 客户端在上传、读取时直接与 DataNode 交互
作为“计算存储融合”的代表 HDFS,其中心思想是通过d ata locality 这一概念来实现的,也就是说,Hadoop 在运行 Mapper 任务时,会尽量让计算任务落在更接近对应的数据节点,由此来减少数据在网络间的传输,达到很大的读取性能。而正是由于 data locality 这一特性,那么就需要让 block 足够大(默认 128M),如果太小的话,那么 data locality 的效果就会大打折扣。
但是大的 block 也会带来 2 个弊端:
- 数据平衡性不好
- 单个 block 上传时只调用了 3 个 DataNode 的存储资源,没有充分利用整个集群的存储上限
计算存储分离 – S3A
我们在前文中已经介绍过,在私有云部署中,数据湖的计算存储分离框架一般由 Ceph 的对象存储来提供共享存储。而 Ceph 的对象存储服务是由 RGW 提供的,RGW 提供了 S3 接口,可以让大数据应用通过 S3A 来访问 Ceph 对象存储。由于存储与计算分离,那么文件的 block 信息不再需要存放到 NameNode 上,NameNode 在 S3A 中不再需要,其性能瓶颈也不复存在。
Ceph 的对象存储服务为数据的管理提供了极大的便利。比如 cloudsync 模块可以让 Ceph 对象存储中的数据十分方便地上传到其他公有云;LCM 特性也使得数据冷热分析、迁移成为可能等等。另外,RGW 支持纠删码来做数据冗余,并且已经是比较成熟的方案了。虽然 HDFS 也在最近支持了纠删码,但是其成熟些有待考证,一般 HDFS 客户也很少会去使用纠删码,更多地还是采用多副本冗余。
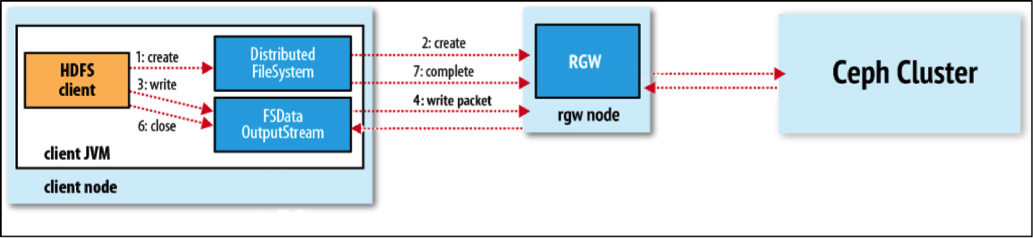
我们通过这张图来简单分析一下 S3A 上传数据的步骤: HDFS 客户端在上传数据时,需要通过调用 S3A 把请求封装成 HTTP 然后发送给 RGW,然后由 RGW 拆解后转为 rados 请求发送给 Ceph 集群,从而达到数据上传的目的。
由于所有的数据都需要先经过 RGW,然后再由 RGW 把请求递交给 OSD,RGW 显然很容易成为性能瓶颈。当然我们可以通过部署多个 RGW 来把负载均摊,但是在请求 IO 路径上,请求无法直接从客户端发送到 OSD,在结构上永远多了 RGW 这一跳。
另外,由于对象存储的先天特性,List Objects 和 Rename 的代价比较大,相对来说会比 HDFS 慢。并且在社区版本中,RGW 无法支持追加上传,而追加上传在某些大数据场景下还是需要的。
由此,我们罗列一下 HDFS 和 S3A 的优缺点:
| 优势 | 劣势 | |
| HDFS | 1.data locality特性让数据读取效率很高
2.客户端写入、读取数据时直接与DataNode交互 |
1.NameNode存放大小元数据、block信息,可能会成为性能瓶颈
2.计算存储没有分离,后期扩展性不好,没有弹性 3.由于block大,数据落盘时的均衡性不好,写入带宽也不够大。 |
|
S3A |
1.存储于计算分离,方便后期各自扩展
2.RGW能够更方便地管理数据 3.成熟的纠删码方案,让存储利用率更高 |
1.所有请求都需要先发往RGW再发往OSD
2.社区版不支持追加上传 3.List Object和rename代价大,比较慢 |
显然,S3A 消除了计算和存储必须一起扩展的问题,并且在存储管理上有着更大的优势,但是所有请求必须先通过 RGW,然后再交由 OSD,不像 HDFS 那般,可以直接让 HDFS 客户端与 DataNode 直接传输数据。显然到了这里,我们可以看到“计算存储融合”与“计算存储分离”两大阵营都尤其独特的优势,也有不足之处。
那么,有没有可能将两者优点结合在一起?也就是说,保留对象存储的优良特性,同时又能让客户端不再需要 RGW 来完成对Ceph 对象存储的访问?
柳暗花明
聊到 UMStor Hadapter 之前,我们还是需要先说一下 NFS-Ganesha 这款软件,因为我们正是由它而获取到了灵感。NFS-Ganesha 是一款由红帽主导的开源的用户态 NFS 服务器软件,相比较 NFSD,NFS-Ganesha 有着更为灵活的内存分配、更强的可移植性、更便捷的访问控制管理等优点。
NFS-Ganesha 能支持许多后台存储系统,其中就包括 Ceph 的对象存储服务。

上图是使用 NFS-Ganesha 来共享一个 Ceph 对象存储下的 bucket1 的使用示例,可以看到 NFS-Ganesha 使用了 librgw 来实现对 Ceph 对象存储的访问。librgw 是一个由 Ceph 提供的函数库,其主要目的是为了可以让用户端通过函数调用来直接访问 Ceph 的对象存储服务。librgw 可以将客户端请求直接转化成 librados 请求,然后通过 socket 与 OSD 通信,也就是说,我们不再需要发送 HTTP 请求发送给 RGW,然后让 RGW 与 OSD 通信来完成一次访问了。
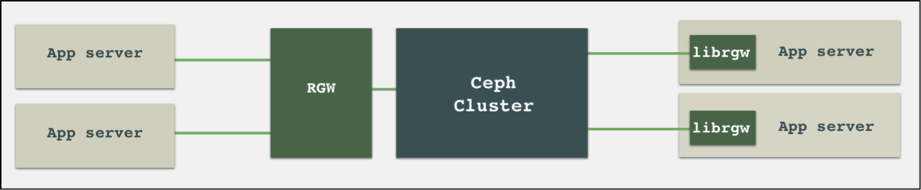
从上图可得知,App over librgw 在结构上是优于 App over RGW 的,请求在 IO 调用链上少了一跳,因此从理论上来说,使用 librgw 可以获得更好的读写性能。
这不正是我们所寻求的方案吗?如果说“计算存储融合”与“计算存储分离”两者的不可调和是一把锁,那么 librgw 就是开这一把锁的钥匙。
UMStor Hadapter
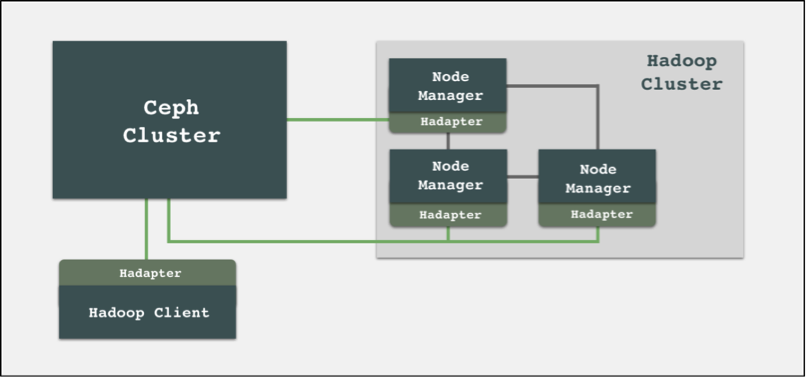
基于 librgw 这个内核,我们打造了一款新的 Hadoop 存储插件 – Hadapter。libuds 是整个 Hadapter 的核心函数库,它封装 librgw。当 Hadoop 客户端发送以 uds:// 为前缀的请求时,Hadoop 集群就会将请求下发给 Hadapter,然后由 libuds 调用 librgw 的函数,让 librgw 直接调用 librados 函数库来请求 OSD,由此完成一个请求的完成处理。
Hadapter 本身只是一个 jar 包,只要将这个 jar 包放到对应大数据节点就可以直接使用,因此部署起来也十分便捷。同时我们还对 librgw 做了一些二次开发,比如,让 librgw 能够支持追加上传,弥补了 S3A 在追加上传上的短板。
我们对 HDFS、S3A、Hadapter 做了大量的性能对比测试,虽然不同的测试集有其独特的 IO 特性,不过我们在大多数测试中都获取到了类似的结果:HDFS > Hadapter > S3A。我们在这里用一个比较典型的 MapReduce 测试: word count 10GB dataset 来看一下三者表现。
为了控制变量,所有的节点都采用相同的配置,同时 Ceph 这边的冗余策略也和 HDFS 保持一致,都采用三副本。Ceph 的版本为 12.2.3,而 Hadoop 则采用了 2.7.3 版本。所有计算节点均部署了 Hadapter。在该测试下,我们最终获取到的结果为:
|
HDFS |
S3A |
Hadapter |
|
|
Time Cost |
3min 2.410s |
6min 10.698s |
3min 35.843s |
可以看到,HDFS 凭借其 data locality 特性而获取的读性能,还是取得了最好的成绩;而 Hadapter 这边虽然比 HDFS 慢,但不至于太差,只落后了 35s;而 S3A 这边则差出了一个量级,最终耗时为 HDFS 的两倍。我们之前所说的的,理论上 librgw 比 RGW 会取得更好的读写性能,在这次测试中得到了印证。
客户案例
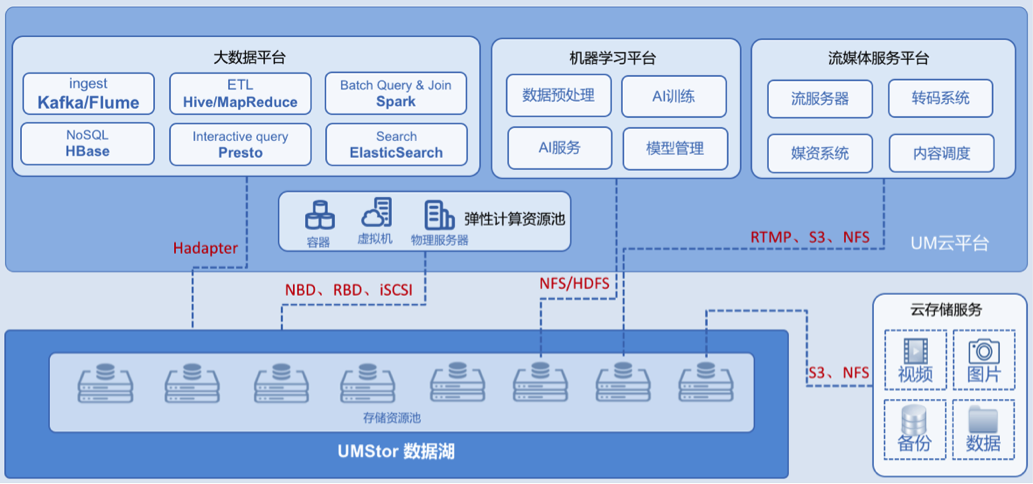
Hadapter 在去年迎来了一位重量级客人。该客户是一家运营商专业视频公司,我们为它搭建了一套结合了大数据、机器学习、流媒体服务以及弹性计算资源池的存储后台解决方案。集群规模达到 35PB 左右。
Hadapter 在这套大数据平台下,主要为 Hbase、Hive、 Spark、 Flume、 Yarn 等应用提供后台支持,目前已经上线。
结语
好了,现在我们把 HDFS、S3A、Hadapter 都拿出来比较一下:
|
优势 |
劣势 |
|
|
HDFS |
1.data locality特性让数据读取效率很高
2.客户端写入、读取数据时直接与DataNode交互 |
1.NameNode存放大小元数据、block信息,可能会成为性能瓶颈
2.计算存储没有分离,后期扩展性不好,没有弹性 3.由于block大,数据落盘时的均衡性不好,写入带宽也不够大。 |
|
S3A |
1.存储于计算分离,方便后期各自扩展
2.RGW能够更方便地管理数据 3.成熟的纠删码方案,让存储利用率更高 |
1.所有请求都需要先发往RGW再发往OSD
2.社区版不支持追加上传 3.List Object和rename代价大,比较慢 |
|
Hadapter |
兼有RGW的优点
1.支持追加上传 2.允许Hadoop客户端直接与Ceph OSD通信,绕开了RGW,从而取得更好的读写性能 |
1.List Object和rename代价大,比较慢 |
虽然上述列举了不少 HDFS 的缺点,不过不得不承认,HDFS 仍旧是“计算存储融合”阵营的定海神针,甚至可以说,在大部分大数据玩家眼中,HDFS 才是正统。不过,我们也在 Hadapter 上看到了“计算存储分离”的新未来。目前 UMStor 团队正主力打造 Hadapter 2.0,希望能带来更好的兼容性以及更强的读写性能。
这场较量,或许才拉开序幕。