抵制数豆子:除提交次数外的开源影响力
| 2019-03-08 10:48
开源互动有何价值?
无论您是发布自己的代码还是为其他人的项目做贡献,评估开源互动的有效性都是一项相当模糊的任务。
评估“互动成功与否”的传统方法与可以轻松量化的事件密切相关。在体育运动中,可以通过比赛规则和身体表现来评估运动员,比如多快、多高和多少次。在销售中,可能通过客户转化率和销售额数据来衡量销售人员。
开源社区评估与有形的工件和成果的关系没那么密切。开源社区中的“成功”涉及到 3 个关键领域:
- 个人影响力(我做了多大贡献?)
- 组织影响力(您对社区有多重要?)
- 流行度(是否有人关心您在做什么?)
这非常类似于研发。在研发中,人们可能通过发表文章数来评估个人影响力,通过专利数和所开发产品的销量(间接销量)来评估组织影响力,并通过引用率和市场份额来评估流行度。
本文特别关注组织影响力,并建议使用提交次数作为启发方法来衡量组织与某个开源项目的互动水平。澄清一点,尽管收入是我们的经济和许多业务的推动因素,但本文的关注点不是收入。我们关注的是价值;收入是一种结果。
您如何衡量开源互动的价值?
开源社区度量指标的当前范式受到这些社区人员有限背景严重影响。具体来讲,在计算机科学和 IT 领域拥有狭隘背景的人获得的社会科学培训很少,而且认为系统度量指标足以衡量人类。在系统中,精确率对识别性能瓶颈、上线时间和容量规划很重要。
在传统上,基于“员工的价值就是员工产生的工作量”的假设,科技行业将上述狭隘的背景应用于人类度量指标(这里称为“人类-系统度量范式”)。因此,度量指标必须用非常高的精确率来衡量工作量,比如代码行数或解决的通知单数。此外,员工报酬和评级与报告的这些工作量直接挂钩。
事实上,量化的工作量度量指标只能告诉我们关于工作的价值或性质的部分信息,而不是全部。而且,在销售中引入竞争机制,并且衡量的工作量与切实奖励挂钩时,这些指标可能导致行为差错。
您是否改变过您的工作活动来“虚报”某个工作量度量指标?
人类无法用人类-系统度量指标来衡量,因为人太会糊弄了。度量指标应该由问题驱动(基于您的目标和价值以及您希望如何实现它们),而不是完全由数据驱动。事实上,如果没有适当的反省和思考如何衡量指标如何影响您的更大目标(以及它们是否相关),就不应该开始收集任何数据。
您如何摆脱人类-系统度量范式?
- 询问更好的开源互动问题
- 寻找能引发战略性讨论的有意义答案(而不只是仪表板)
GitHub:一个针对编码的社交网络平台
许多开源社区和组织通过 GitHub 托管其项目(不要与 git 混淆,git 是一个命令行工具,GitHub 提供了它的接口)。GitHub 是一个包含等待分析的公共活动的宝库,但 GitHub 本身无法在这一领域提供任何有意义的信息!每一年,GitHub 都会发布 The State of the Octoverse 报告,这是数据驱动的度量指标的典型例子。该报告包含丰富的漂亮图表和统计数据,但非常混乱和不连贯,无法讲述任何故事或分享任何有深度或有意义的信息。

每个存储库的页面都包含提交数和贡献者数量等基本统计数据。甚至还包含一个洞察页面,上面提供了更多(但不是特别有见地)的统计数据。我们无法使用这些类型的人类-系统度量指标来获得有意义的结论。
使用提交次数作为对影响力的度量
提交次数是一个被认为属于代码更改的历史记录。目前,“排名”影响力的流行度量方法是统计提交次数,并根据识别出的一组作者信息将它们分配给一位作者或一个公司。
常见问题:谁的提交次数最多?更好的问题:一个组织的影响力有多大?
识别组织关联
标识公司的最常见方法是通过作者用于提交的电子邮箱地址的域名,或者通过作者的 GitHub 个人资料中的公司字段来标识公司。公司字段是自由格式的文本,没有修改历史,而且无法实际验证。此外,只有少部分 GitHub 用户在实际使用它。
让用户使用其工作电子邮箱地址向存储库执行提交,这是标识组织关联的最可靠方法。但是,跨项目的准确性仍是一大挑战,因为作者并不总是使用相同的电子邮箱地址,而且一些作者从不使用他们的工作电子邮箱地址。
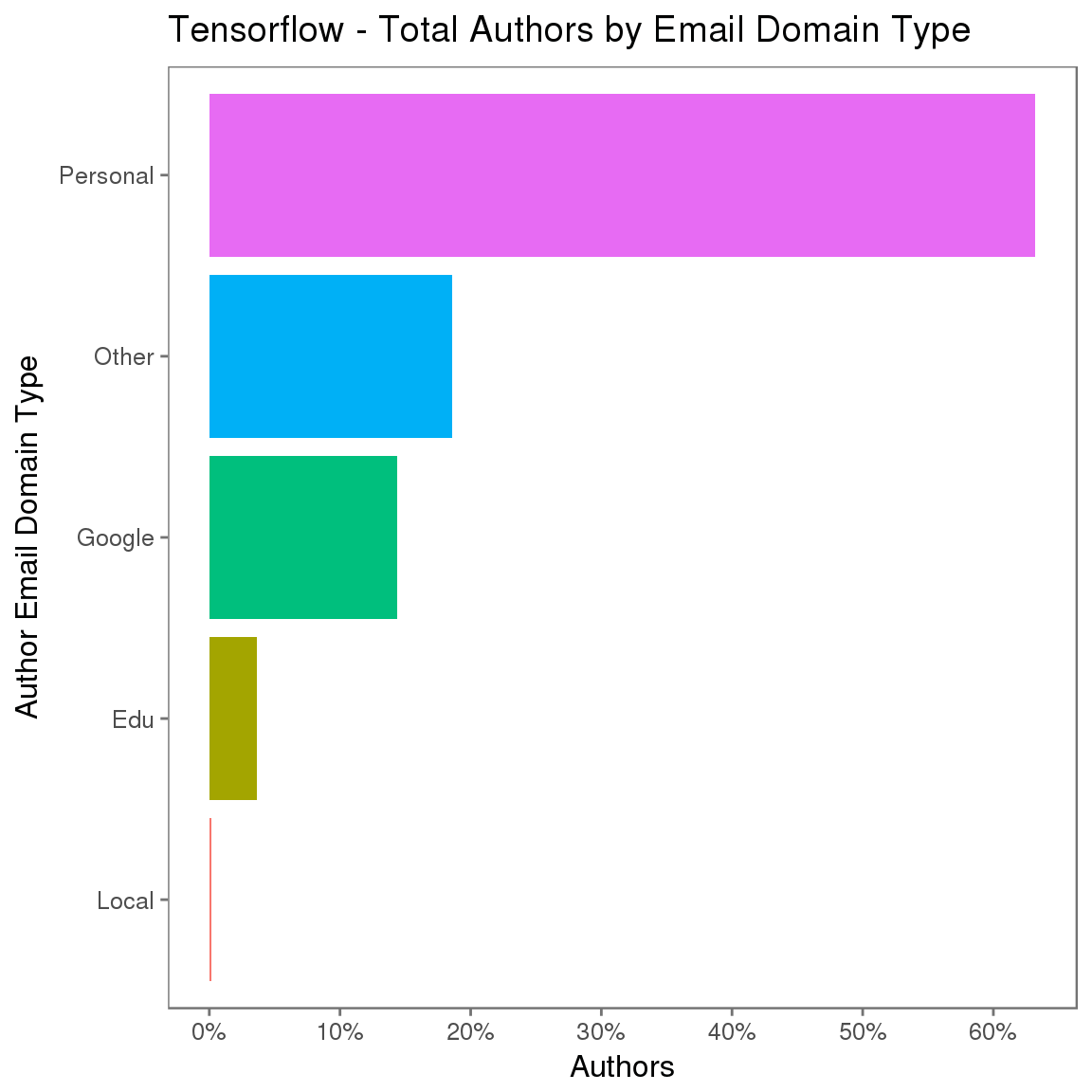
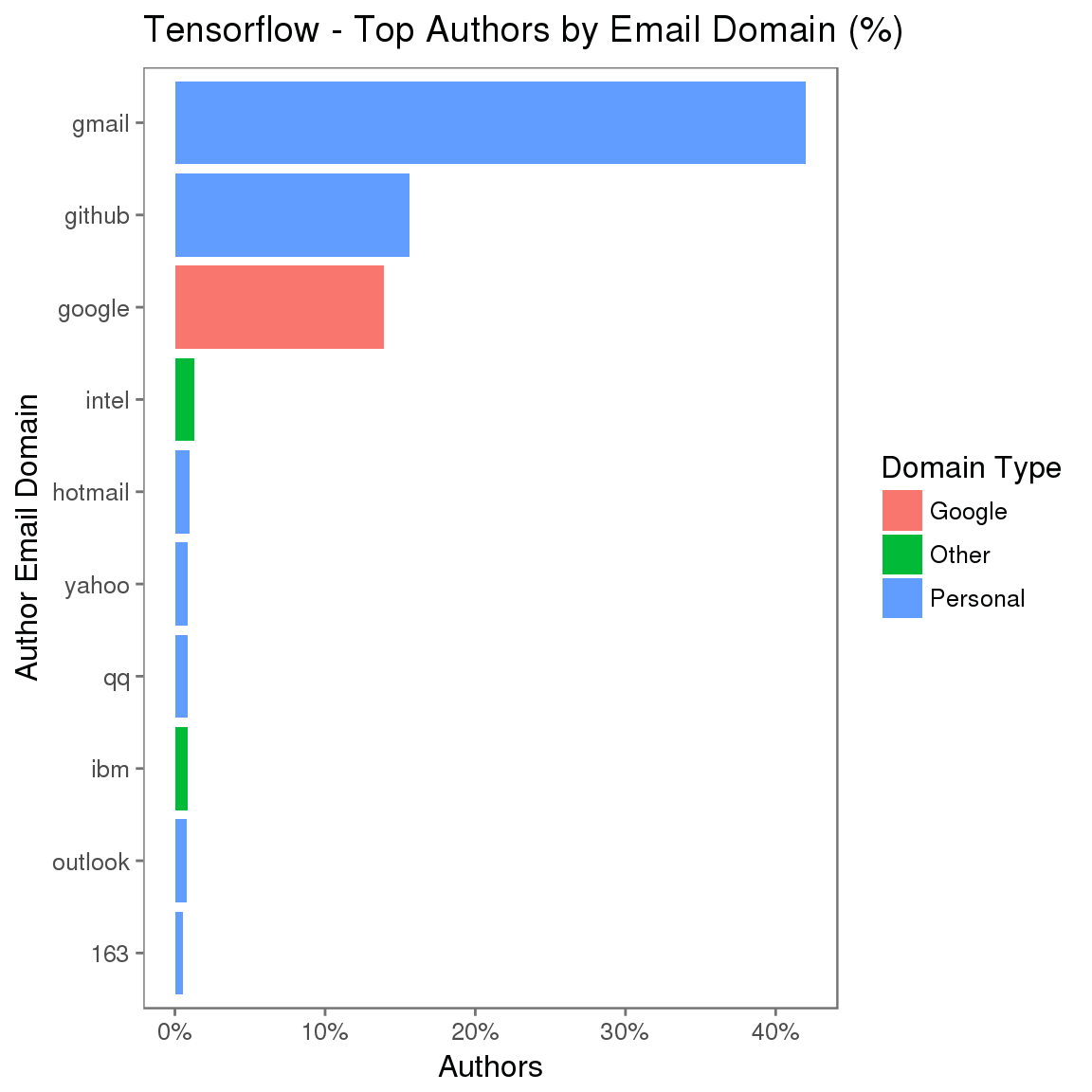
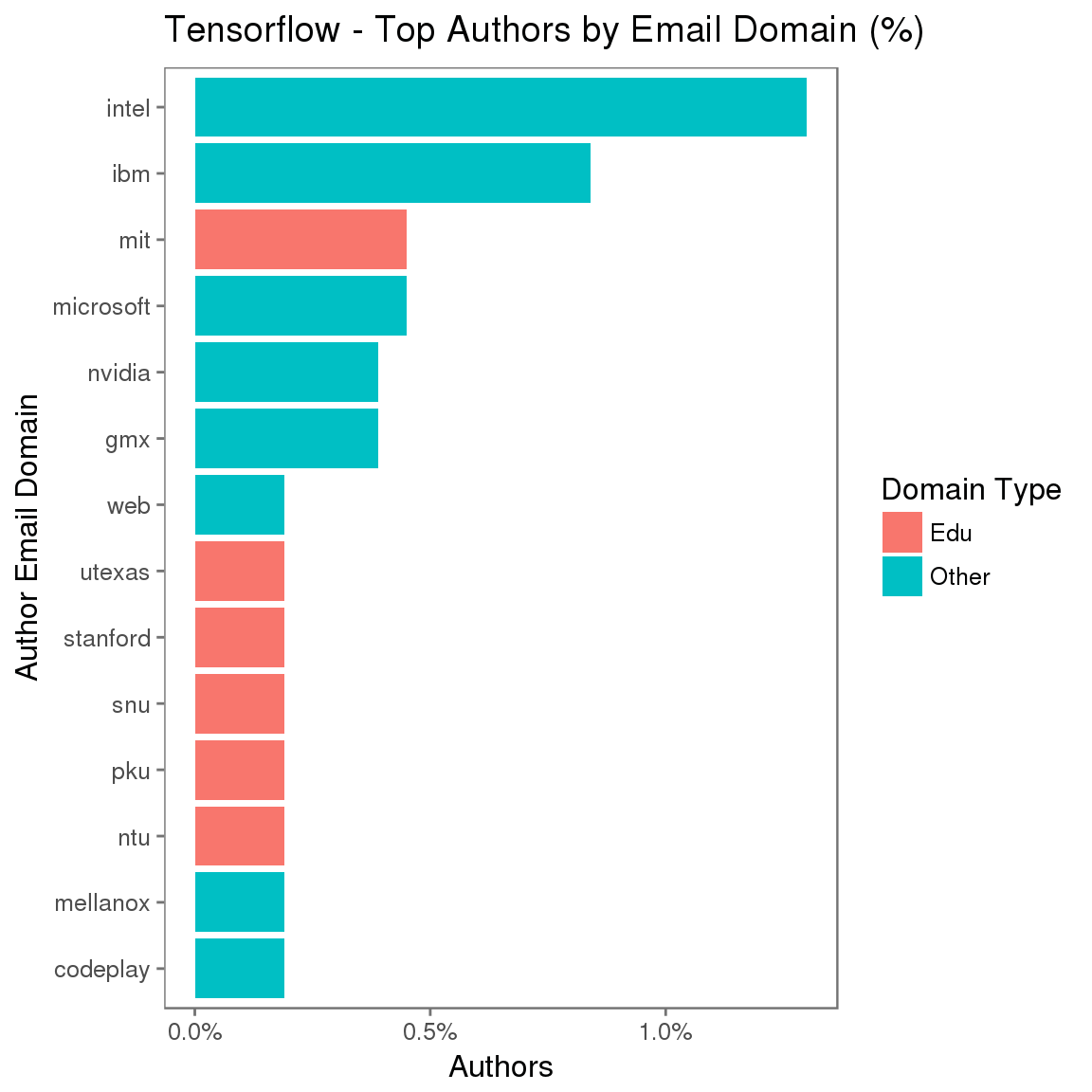
解决此问题的人类-系统度量方法是,开发一个复杂解决方案来标识作者关联,以便提高精确率,但这只能获得少量收益,而且复杂性和开销会明显增加。一个根据成熟的社会科学和统计方法构建的问题驱动的方法建议,您无需在意精确率,只要询问正确的问题就行了。


我知道您至少能够非常肯定地识别部分关联。因此,要考虑的启发方法是,如果一个组织互动积极,那么他们在给定时间间隔内将至少拥有 1 次包含关联的电子邮件域的提交。这种启发方法也可以预防“游戏化”,预防成员向项目执行大量错误提交来提升其排行榜位置,因为在给定时间间隔只进行一次计数。
警告:使用此启发方法可能无法识别频繁互动的组织。
采用提交模式而不是提交计数
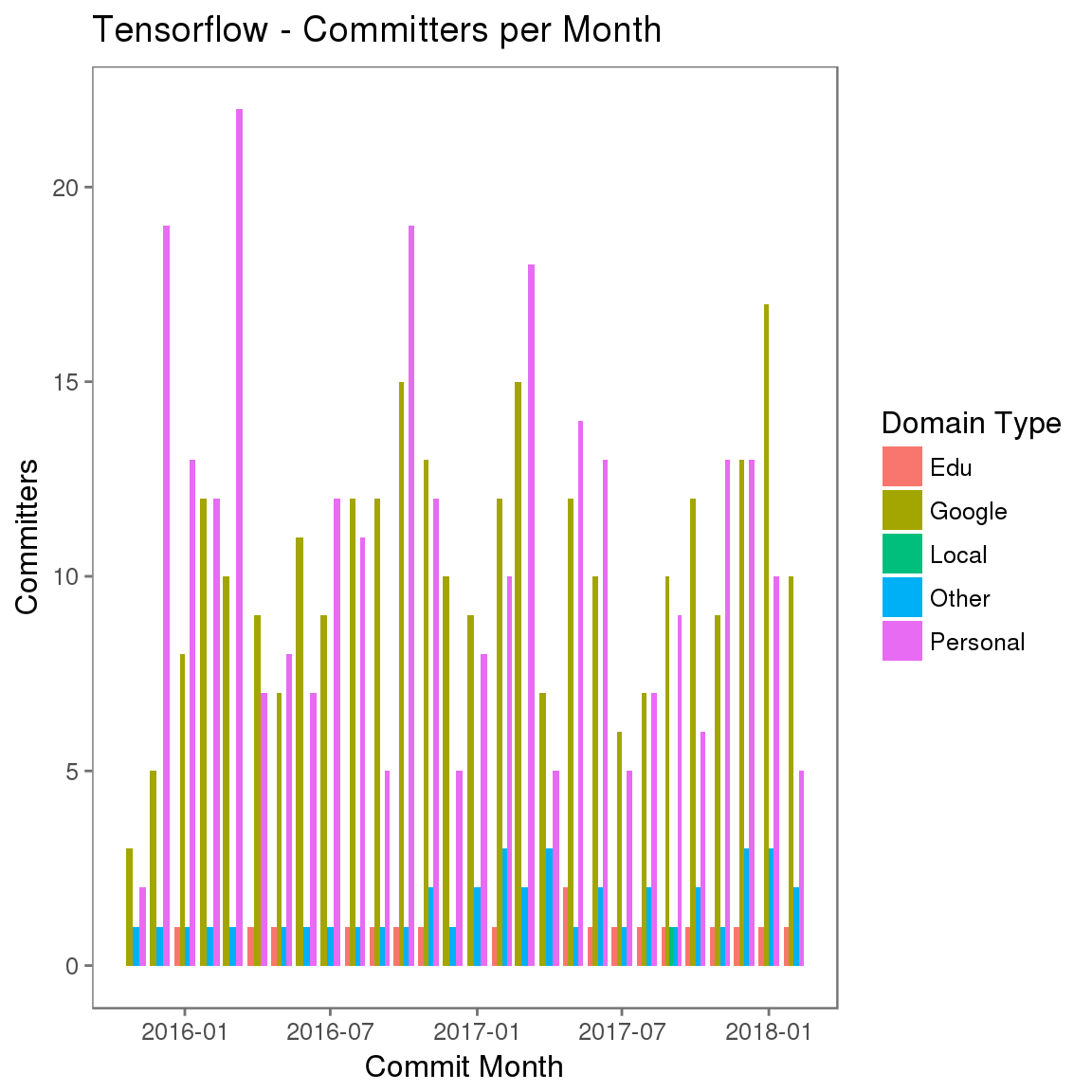
互动频率(提交间隔)
当您思考与人的关系时,与您关系最密切的人往往是您在较长时间内最常交流的人。使用此模型,您无需考虑提交计数,只需考虑您是否至少采用一致方式提交了一次,以及提交花了多长时间。这还展示了一个组织向一个项目提交了多长时间,这是单单一个提交计数所无法展现的。
具体来讲,这个指标度量包含至少一次提交的时间间隔频率(比如月),并回答了下面的问题:该组织参与互动已有多长时间?
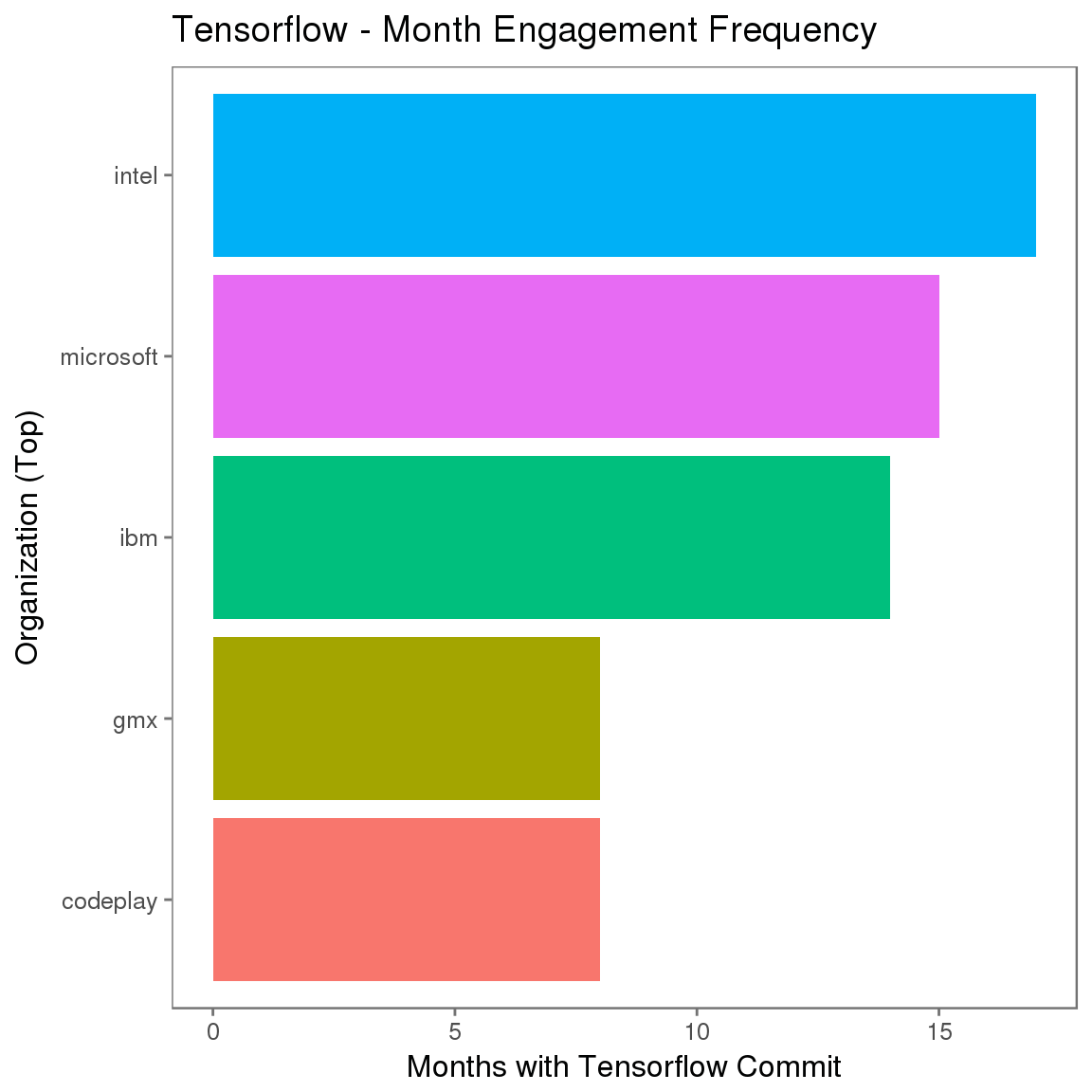

互动周期(提交间隔顺序)
描绘为时序时,上面演示的提交间隔也可以表明该组织参与互动的一致性。
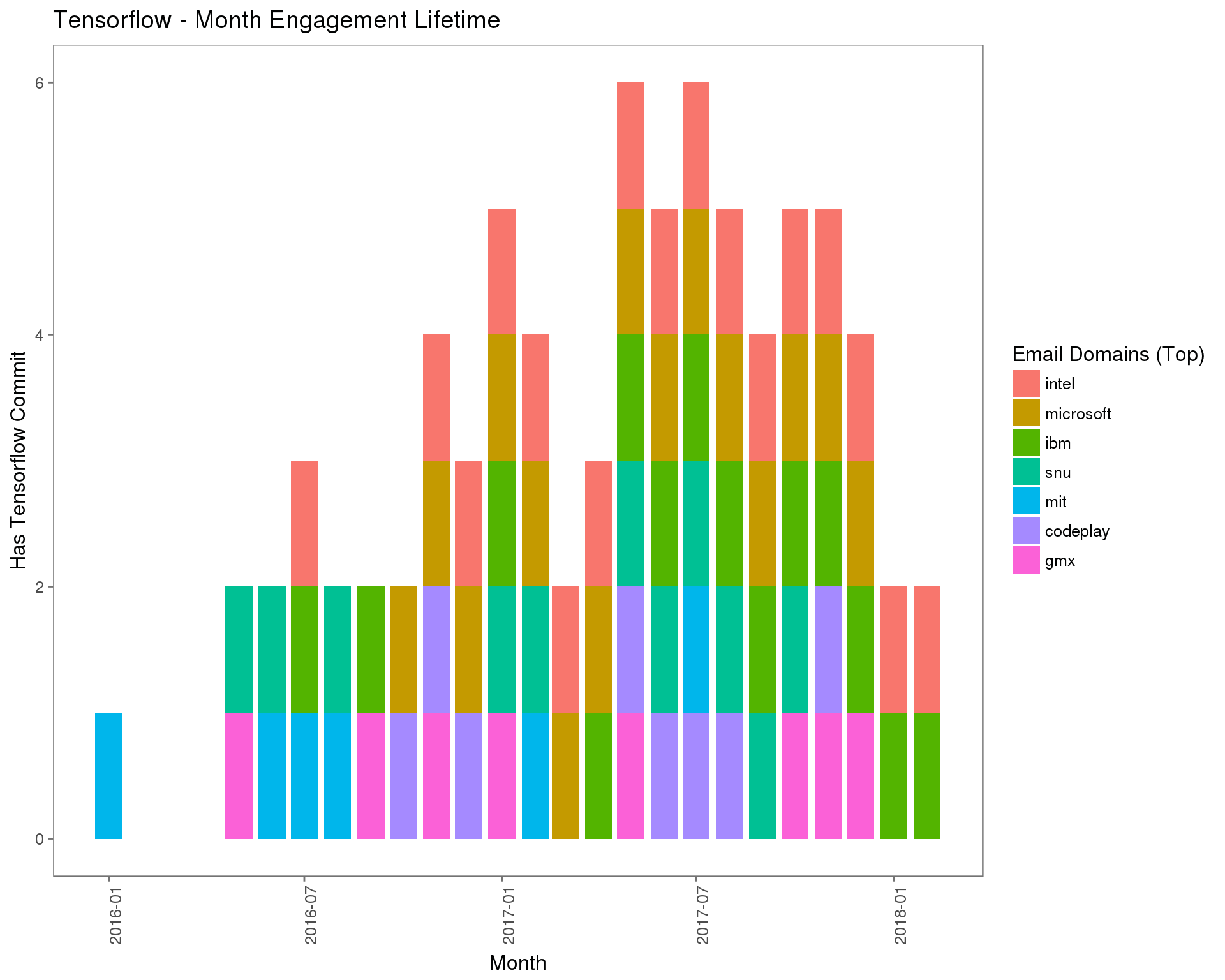
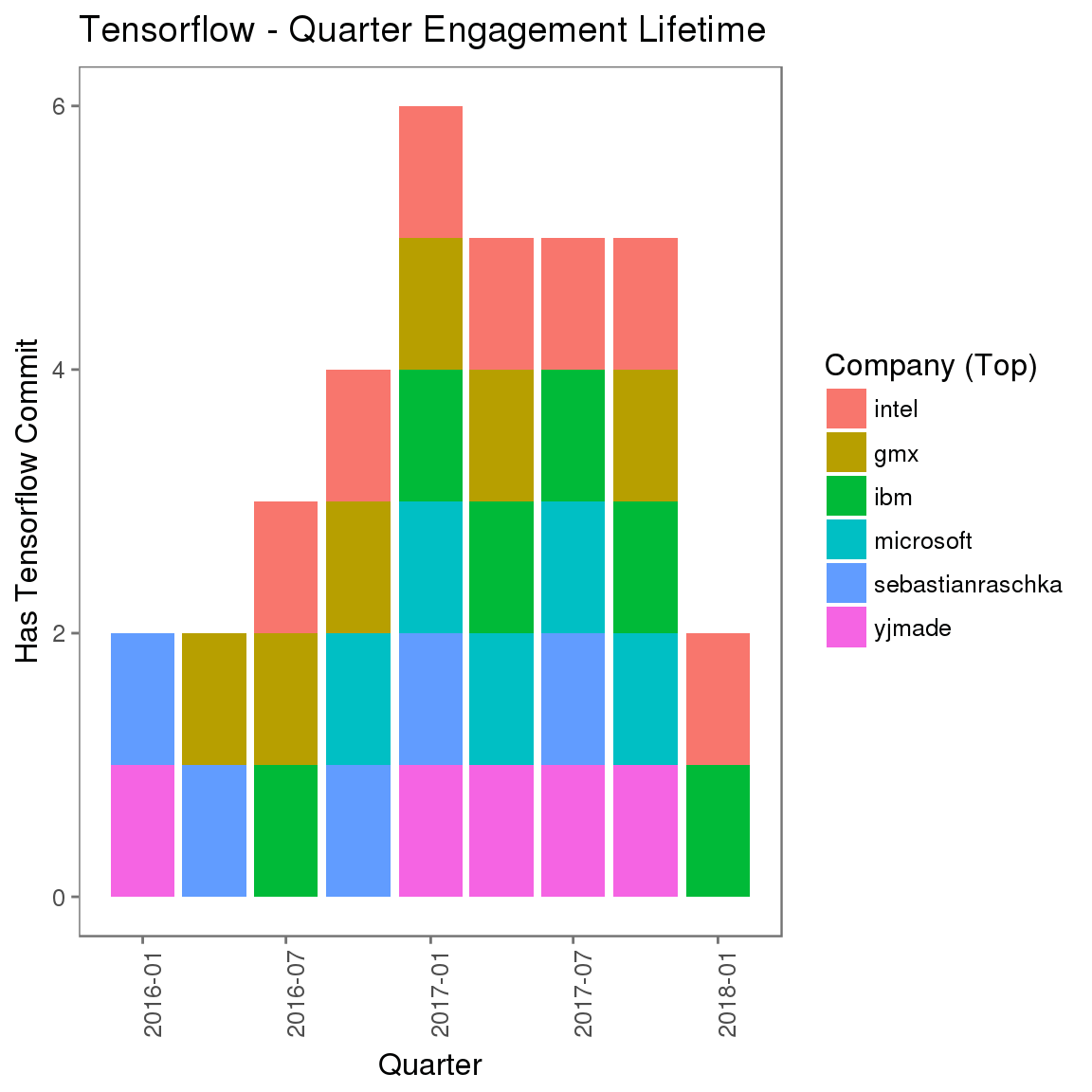
每个组织的提交计数何时才足够准确(且成本低)?
在开源领域,有两种基本的治理类型:封闭和开放。封闭治理意味着,项目领导角色由单个实体控制,提交者主要与该实体相关联。根据控制实体的目标,项目可能被转换为开放治理项目,这意味着任何社区成员都可以承担领导角色。在这些情况下,可以预料属于原组织的提交者中具有更高的识别率。
当识别率基本上为 X 和 ~X 时,提交者与属于每个小组的提交次数的比例应表明大部分提交是否与原组织相关。
提交者多样性
一个项目的开放治理水平如何?理想情况下,一个开放治理项目不应让大部分提交者代表一个组织。还可以使用这个度量指标来演示过去采用开放治理的项目上存在的问题,尤其是在确定存在某种已知的主要影响力时。
IBM Cognitive Open Technology 团队最近 在 Index 大会上举行了一次 Tensorflow 小组会议,有多位重要的 Tensorflow Google 员工参与了此会议。会议声明,Google 在努力通过增加非 Google 提交者让 Tensorflow 社区变得多样化。
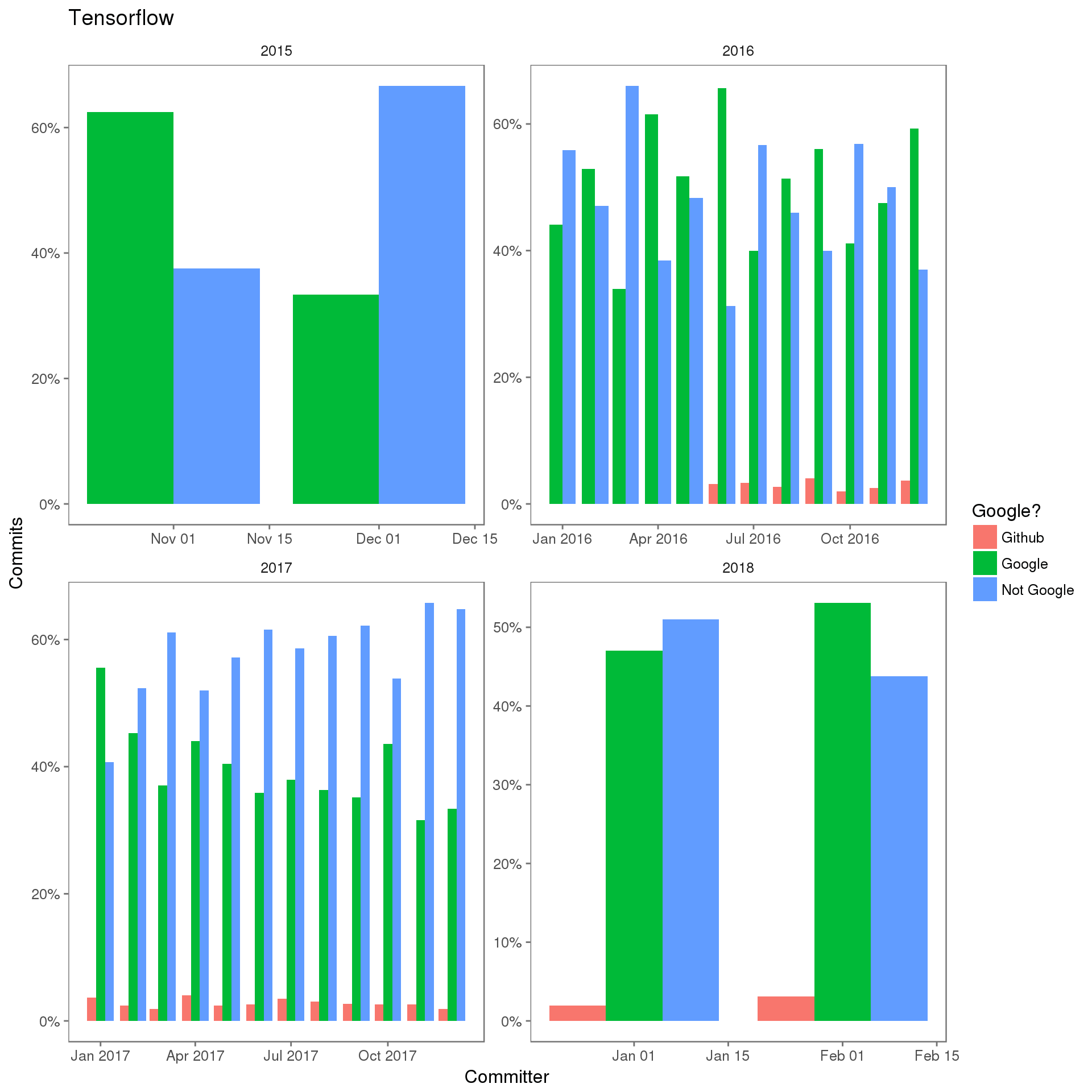
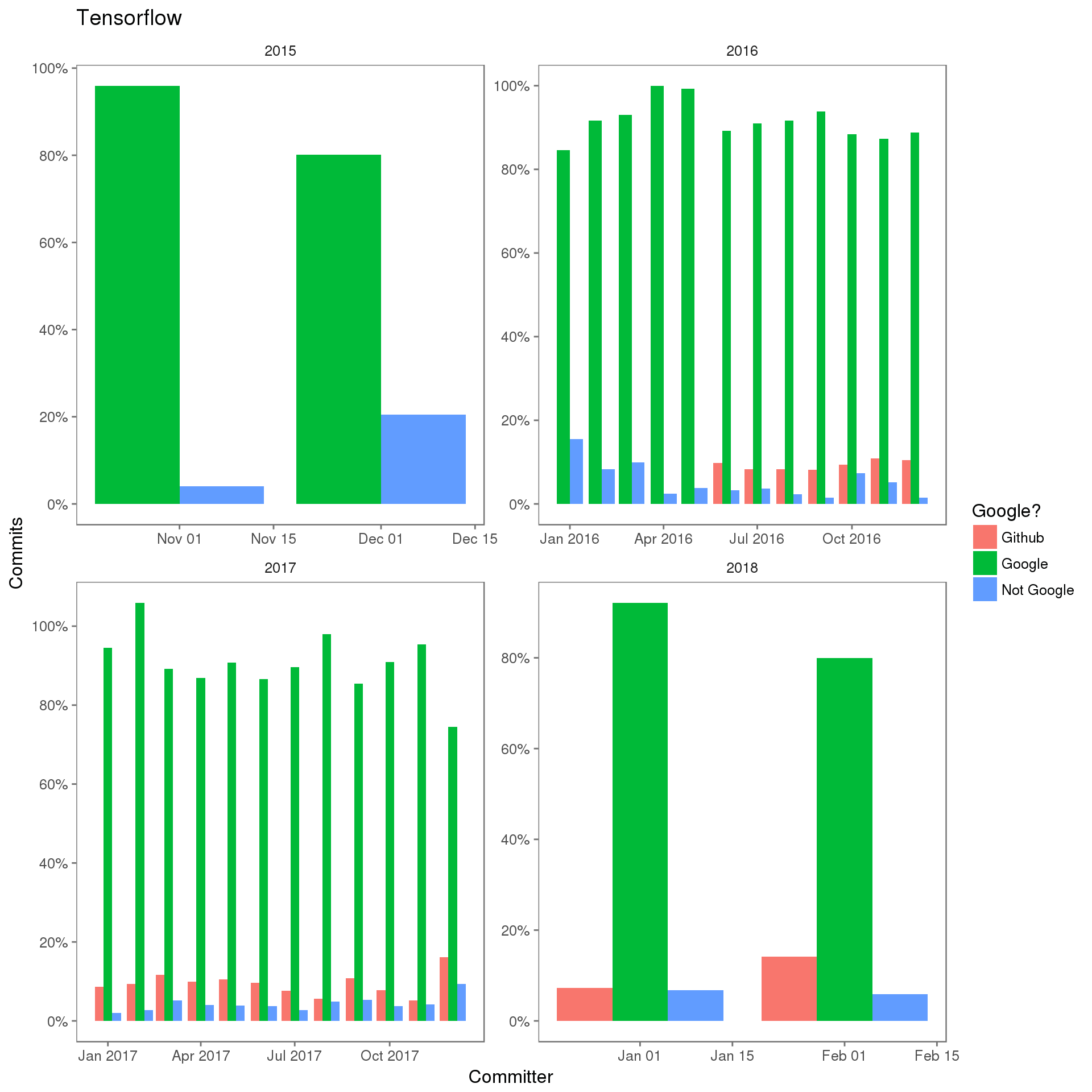
结束语
我演示了单看提交数和作者数不是特别具有洞察力。但是,随着不断地绘制图表,您可以获得组织与项目的关系性质的更多洞察。此外,因为您考虑的是可以更明确地识别哪些关联,而不是穷追您不能识别的关联,所以您可以衡量一个或多个组织是否主导着某个开源项目中的活动。
最后的思考:有关提交次数的注意事项
提交次数不是一种充分的互动度量。必须考虑其他活动才能开展有根据的战略讨论,更不用说提交次数本身的实际含义。此外,这里提出的指标仍处于探索阶段,有待严格验证。无论如何,这些指标应该提供了一个起点,启发您就自己的开源互动目标提出更好的问题并建立更好的交流。
其他资源

 );){kind=link}