从 0 到 1:如何快速地将设计稿生成代码
| 2020-09-10 09:37
文末有惊喜,不要忘了去文末看哦~
什么是 imgCook?
imgcook 可以使用 Sketch、PSD、静态图片等形式作为输入,通过智能化技术一键生成可维护的前端代码,包含视图代码、数据字段绑定、组件代码、部分业务逻辑代码等。
Img Cook 期望能够利用智能化手段,让自己成为一位前端工程师,在对设计稿轻约束的前提下实现高度还原,释放前端生产力,助力前端与设计师高效协作,让工程师们专注于更具挑战性的工作!
设计稿生成代码的难点
视图代码研发,一般是根据视觉稿编写 HTML 和 CSS 代码。如何提效,当面对 UI 视图开发重复性的工作时,自然想到组件化、模块化等封装复用物料的解决方案,基于此解决方案会有各种 UI 库的沉淀,甚至是可视化拼装搭建的更高阶的产品化封装,但复用的物料不能解决所有场景问题。个性化业务、个性化视图遍地开花,直面问题本身,直接生成可用的 HTML 和 CSS 代码是否可行?
这是业界一直在不断尝试的命题,通过设计工具的开发插件可以导出图层的基本信息,但这里的主要难点还是对设计稿的要求高、生成代码可维护性差,这是核心问题,我们来继续拆解。
设计稿要求高
对设计稿的要求高,会导致设计师的成本加大,相当于前端的工作量转嫁给了设计师,导致推广难度会非常大。一种可行的办法是采用 CV(ComputerVision, 计算机视觉) 结合导出图层信息的方式,以去除设计稿的约束,当然对设计稿的要求最好是直接导出一张图片,那样对设计师没有任何要求,也是我们梦寐以求的方案,我们也一直在尝试从静态图片中分离出各个适合的图层,但目前在生产环境可用度不够(小目标识别精准度问题、复杂背景提取问题仍待解决),毕竟设计稿自带的元信息,比一张图片提取处理的元信息要更多更精准。
代码可维护性
生成的代码结构一般都会面临可维护性方面的挑战:
- 合理布局嵌套:包括绝对定位转相对定位、冗余节点删除、合理分组、循环判断等方面;
- 元素自适应:元素本身扩展性、元素间对齐关系、元素最大宽高容错性;
- 语义化:类名的多级语义化;
- 样式 CSS 表达:背景色、圆角、线条等能用 CV 等方式分析提取样式,尽可能用 CSS 表达样式代替使用图片;
问题如何解决?
基于上述的概述和问题分解后,我们对现有的 D2C(Design 2 Code) 智能化技术体系做了能力概述分层,主要分为以下三部分:
- 识别能力:即对设计稿的识别能力。智能从设计稿分析出包含的图层、基础组件、业务组件、布局、语义化、数据字段、业务逻辑等多维度的信息。如果智能识别不准,就可视化人工干预补充纠正,一方面是为了可视化低成本干预生成高可用代码,另一方面这些干预后的数据就是标注样本,反哺提升智能识别的准确率。
- 表达能力:主要做数据输出以及对工程部分接入:a)通过 DSL 适配将标准的结构化描述做 Schema2Code;b)通过 IDE 插件能力做工程接入。
- 算法工程:为了更好的支撑 D2C 需要的智能化能力,将高频能力服务化,主要包含数据生成处理、模型服务部分:
- 样本生成:主要处理各渠道来源样本数据并生成样本
- 模型服务:主要提供模型 API 封装服务以及数据回流

(前端智能化 D2C 能力概要分层)
在整个方案里,我们用同一套**数据协议规范(D2C Schema)**来连接各层的能力,确保其中的识别能够映射到具体对应的字段上,在表达阶段也能正确地通过出码引擎等方案生成代码。
智能识别技术分层
在整个 D2C 项目中,最核心的是上述识别能力部分的机器智能识别部分,这层的具体再分解如下:
- 物料识别层:主要通过图像识别能力识别图像中的物料(模块识别、原子模块识别、基础组件识别、业务组件识别)。
- 图层处理层:主要将设计稿或者图像中图层进行分离处理,并结合上一层的识别结果,整理好图层元信息。
- 图层再加工层:对图层处理层的图层数据做进一步的规范化处理。
- 布局算法层:转换二维中的绝对定位图层布局为相对定位和 Flex 布局。
- 语义化层:通过图层的多维特征对图层在生成代码端做语义化表达。
- 字段绑定层:对图层里的静态数据结合数据接口做接口动态数据字段绑定映射。
- 业务逻辑层:对已配置的业务逻辑通过业务逻辑识别和表达器来生成业务逻辑代码协议。
- 出码引擎层:最后输出经过各层智能化处理好的代码协议,经过表达能力(协议转代码的引擎)输出各种 DSL 代码。
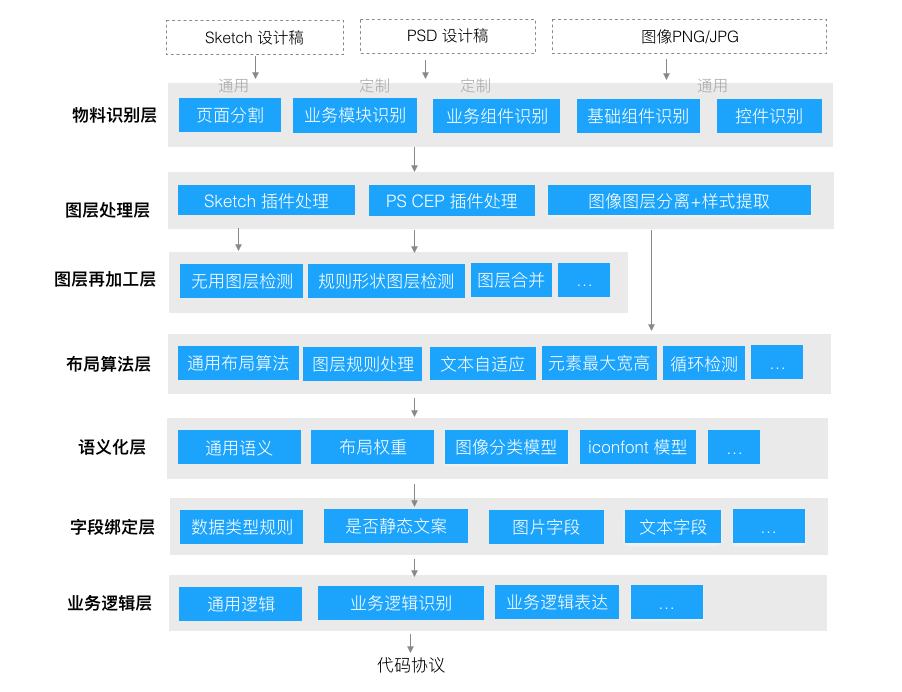
(D2C 识别能力技术分层)
技术痛点
当然,这其中的识别不全面、识别准确度不高一直是 D2C 老生常谈的话题,也是 imgcook 的核心技术痛点。我们尝试从这几个角度来分析引起这个问题的因素:
- 识别问题定义不准确:问题定义不准确是影响模型识别不准的首要因素,很多人认为样本和模型是主要因素,但在这之前,可能一开始的对问题的定义就出现了问题,我们需要判断我们的识别诉求模型是否合适做,如果合适那该怎么定义清楚这里面的规则等。
- 高质量的数据集样本缺乏:我们在识别层的各个机器智能识别能力需要依赖不同的样本,那我们的样本能覆盖多少前端开发场景,各个场景的样本数据质量怎么样,数据标准是否统一,特征工程处理是否统一,样本是否存在二义性,互通性如何,这是我们当下所面临的问题。
- 模型召回低、存在误判:我们往往会在样本里堆积许多不同场景下不同种类的样本作为训练,期望通过一个模型来解决所有的识别问题,但这却往往会让模型的部分分类召回率低,对于一些有二义性的分类也会存在误判。
如何使用 imgCook 将设计稿变为前端代码
在了解了 imgcook 大致思路之后,那么为什么会选择在云开发平台上集成 imgcook 呢?那就是 imgcook 和云开发平台通过彼此的打通,将能够为双方解决彼此的痛点,无论是为云上开发者,还是 imgcook 开发者都提供了全新的用户体验。
对于 imgcook 开发者来说,其中一个痛点就来自于对于设计稿的管理,以及前后端交互的逻辑,然而通过云开发平台,开发者不再需要在本地安装 Sketch,通过云开发平台直接上传设计稿即可开始生成代码,真正做到了0成本一键生成。
另外云开发平台上直接提供了 Midway Serverless 框架,我们通过云开发平台的插件定制化,可以让开发者直接选择某个页面所使用的函数(Function),这样就节省掉编写一些前后端交互的基础逻辑或请求代码。
对于云开发平台的开发者来说,最想得到的便是极速的上线体验和更加便捷的开发体验,imgcook 可以降低云开发平台的使用门槛,比如一位 FaaS 应用工程师不再需要学习如何切图,如何写 CSS,而只需要编写 FaaS 函数的逻辑即可,剩下的前端逻辑代码都可以通过 imgcook 插件在开发平台内即可完成,这是多么棒的体验啊!
那么,接下来就看看如何快速地从 0 到 1 生成代码吧。
首先需要先打开云开发平台创建应用,选择 imgcook 创建应用:
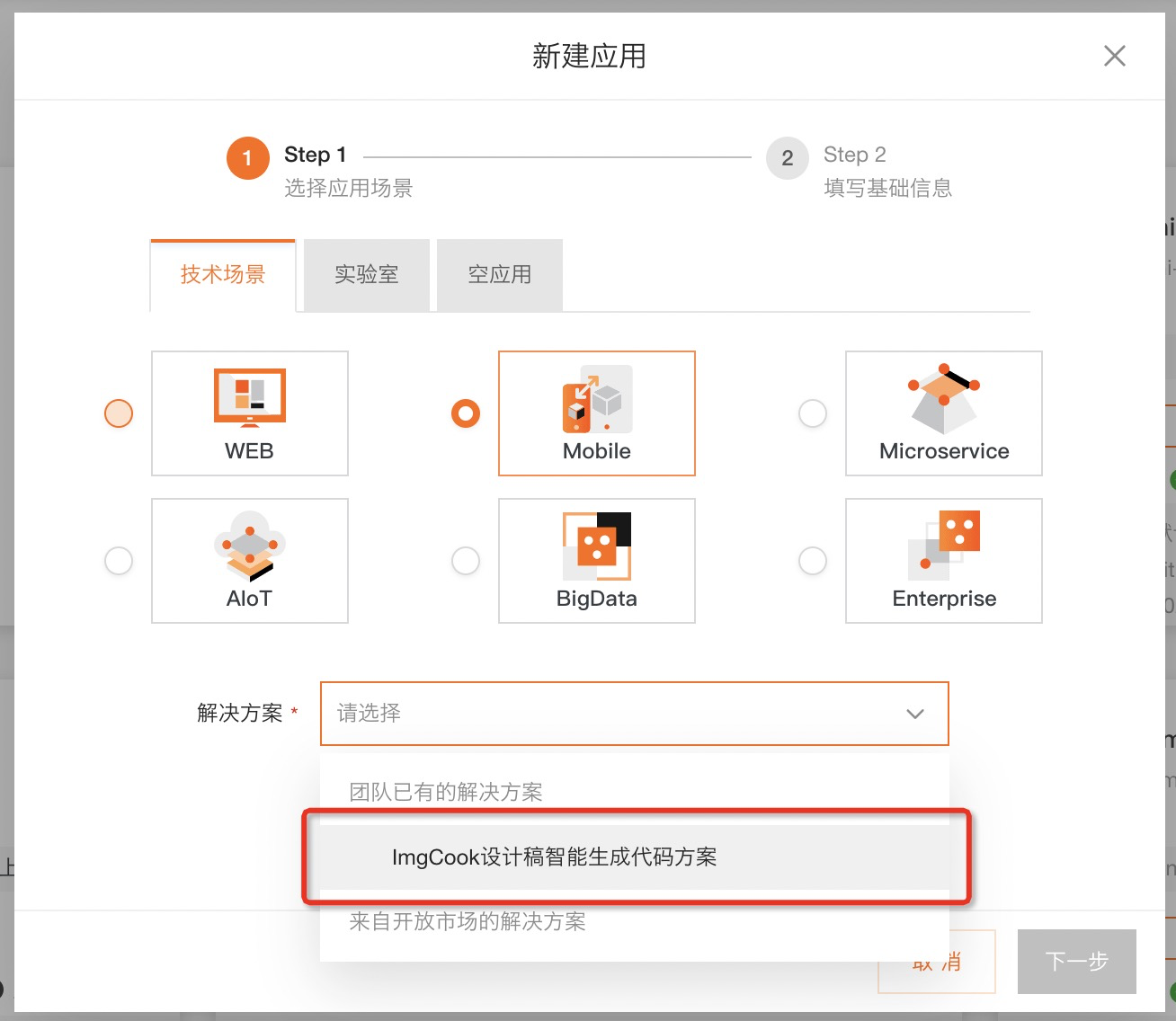
然后在应用的 WebIDE 中通过右键打开 imgcook 云插件,就可以正式开始使用了。
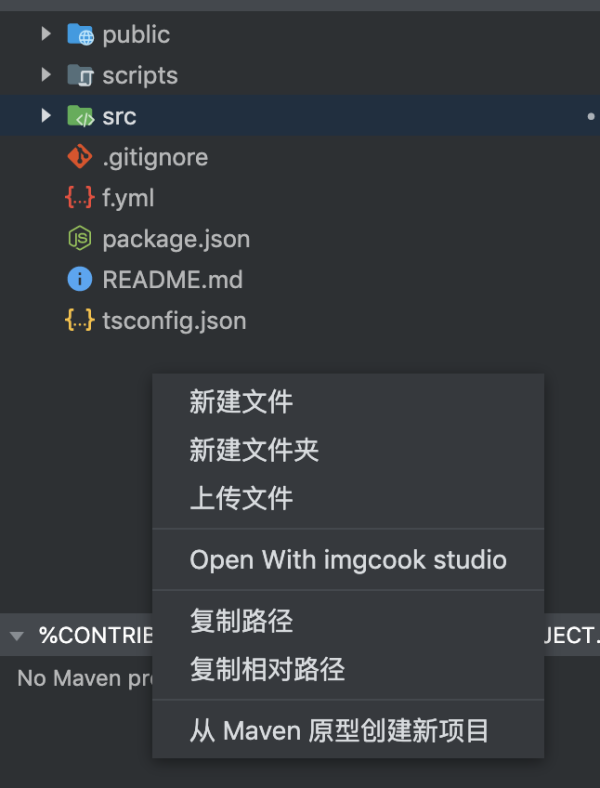
第一步,在插件中选择“导入”,打开上传设计稿界面:
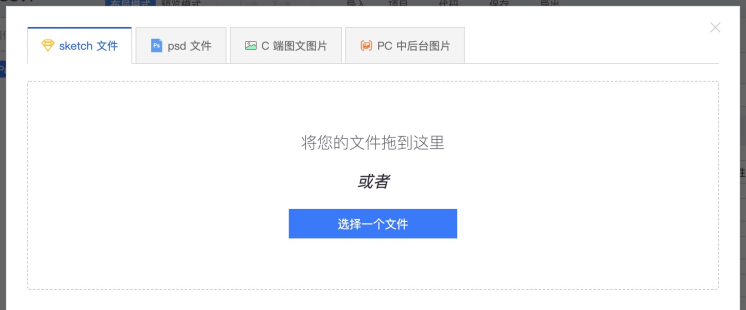
第二步,imgcook 可视化编辑器:
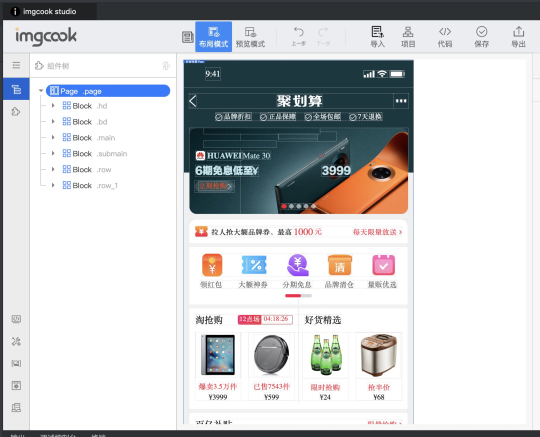
第三步,生成代码:
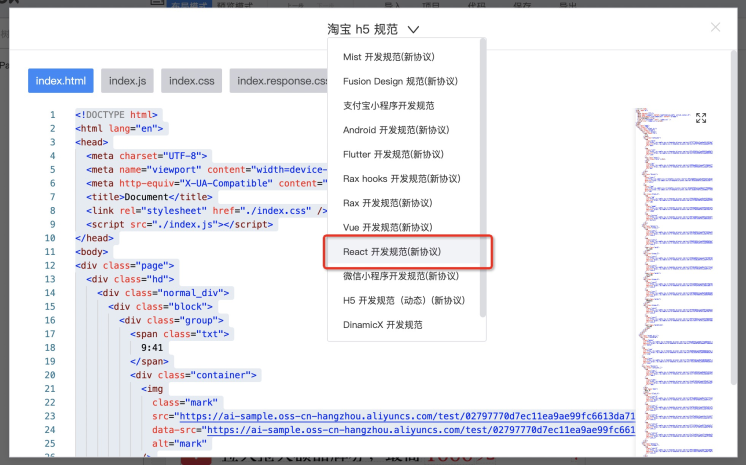
第四步,导出代码到应用:
第五步,上线应用:
$ npm install
$ npm run dev
正在启动,请稍后...
---------------------------------------
开发服务器已成功启动
请打开 >>> http://*****-3000.xide.aliyun.com/
---------------------------------------
感谢使用 Midway Serverless,欢迎 Star!
https://github.com/midwayjs/midway
---------------------------------------
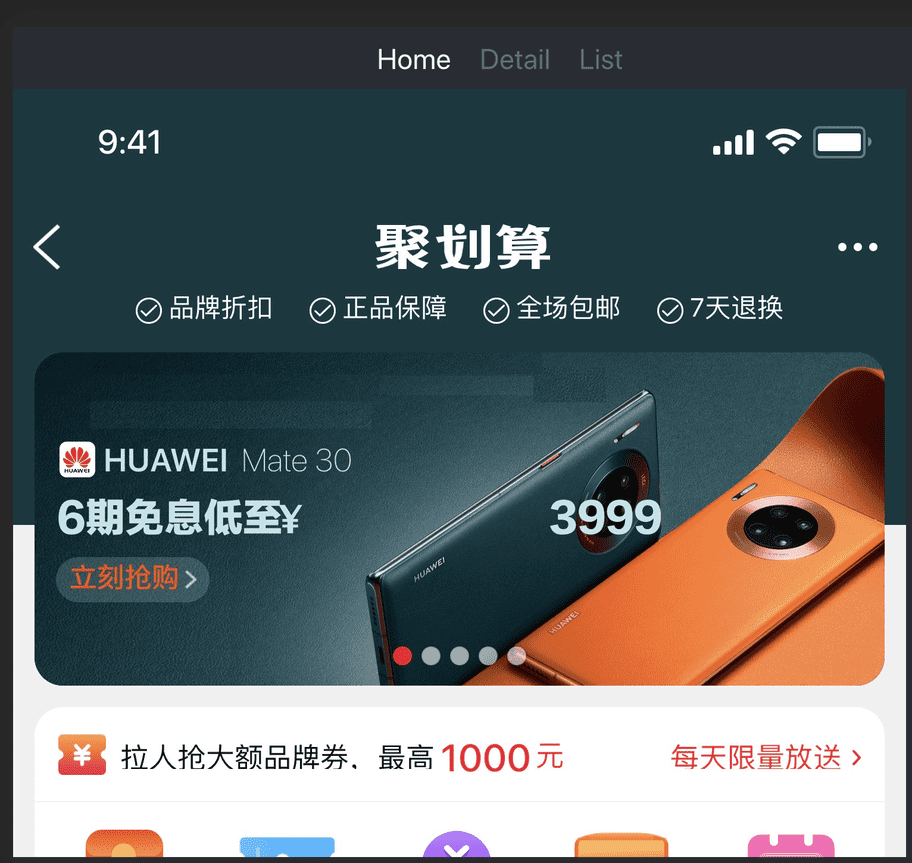
启动成功后通过命令行的地址打开页面效果如下,是不是很简单呢?
总结
本文通过介绍前端智能化的背景,imgcook 的问题定义以及技术方案,以及如何在云开发平台上使用 imgcook 开始智能开发,总的来说,还是希望让业内的前端工程师们从使用 imgcook 开始,将日常工作中的一些繁琐、耗时的工作交给 AI 来完成,这样能关注工程师本身更感兴趣,也更有价值的事情,也相信不久的将来,前端工程师将借助于 AI 能更加快乐与从容地工作!
一场脑洞实验
今年云栖大会期间,阿里云 Hands on Labs 动手实验室推出有奖体验活动,立即参加体验从设计稿自动生成 H5 应用的神奇。
同时,由 Hands-on Labs 发起的万人云上 Hello World 实验上线
- 这是一场脑洞实验,想邀请 10000 名开发者云上 Hello World。希望你愿意来见证这场实验;
- 每一位参与实验的开发者都会收到一张电子荣誉证书,不为别的,和另外 9999 人纪念一下可好?
- 每一位成功参与实验的开发者都有机会参与每天一次的锦鲤程序员抽奖活动,哪怕可能性只有万分之一,来都来了,参与一下呗;
- 感谢中国国内技术社区们的大力支持,有你们的情怀在,才有这场脑洞实验从发起到落地。


 );){kind=link}