图形数据库和NOSQL
| 2014-05-24 12:29 评论: 2 收藏: 4 分享: 2
简介
在众多不同的数据模型里,关系数据模型自80年代就处于统治地位,而且有不少实现,如Oracle、MySQL和MSSQL,它们也被称为关系数据库管理系统(RDBMS)。然而,最近随着关系数据库使用案例的不断增加,一些问题也暴露了出来,这主要是因为两个原因:数据建模中的一些缺陷和问题,以及在大数据量和多服务器之上进行水平伸缩的限制。两个趋势让这些问题引起了全球软件社区的重视:
- 用户、系统和传感器产生的数据量呈指数增长,其增长速度因大部分数据量集中在象Amazon、Google和其他云服务这样的分布式系统上而进一步加快。
- 数据内部依赖和复杂度的增加,这一问题因互联网、Web2.0、社交网络,以及对大量不同系统的数据源开放和标准化的访问而加剧。
在应对这些趋势时,关系数据库产生了更多的问题。这导致大量解决这些问题某些特定方面的不同技术的出现,它们可以与现有RDBMS相互配合或代替它们 - 亦被称为混合持久化(Polyglot Persistence)。数据库替代品并不是新鲜事物,它们已经以对象数据库(OODBMS)、层次数据库(如LDAP)等形式存在很长时间了。但是,过去几年间,出现了大量新项目,它们被统称为NOSQL数据库(NOSQL-databases)
本文旨在介绍图形数据库(Graph Database)在NOSQL运动里的地位,第二部分则是对Neo4j(一种基于Java的图形数据库)的简介。
NOSQL环境
NOSQL(Not Only SQL,不限于SQL)是一类范围非常广泛的持久化解决方案,它们不遵循关系数据库模型,也不使用SQL作为查询语言。
简单地讲,NOSQL数据库可以按照它们的数据模型分成4类:
- 键-值存储库(Key-Value-stores)
- BigTable实现(BigTable-implementations)
- 文档库(Document-stores)
- 图形数据库(Graph Database)
就Voldemort或Tokyo Cabinet这类键/值系统而言,最小的建模单元是键-值对。对BigTable的克隆品来讲,最小建模单元则是包含不同个数属性的元组,至于象CouchDB和MongoDB这样的文档库,最小单元是文档。图形数据库则干脆把整个数据集建模成一个大型稠密的网络结构。
在此,让我们深入检阅NOSQL数据库的两个有意思的方面:伸缩性和复杂度。
1. 伸缩性
CAP: ACID vs. BASE
为了保证数据完整性,大多数经典数据库系统都是以事务为基础的。这全方位保证了数据管理中数据的一致性。这些事务特性也被称为ACID(A代表原子性、C表示一致性、I是隔离性、D则为持久性)。然而,ACID兼容系统的向外扩展已经表现为一个问题。在分布式系统中,高可用性不同方面之间产生的冲突没有完全得到解决 - 亦称CAP法则:
- 强一致性(C):所有客户端看到的数据是同一个版本,即使是数据集发生了更新 - 如利用两阶段提交协议(XA事务),和ACID,
- 高可用性(A):所有客户端总能找到所请求数据的至少一个版本,即使集群中某些机器已经宕机,
- 分区容忍性(P):整个系统保持自己的特征,即使是被部署到不同服务器上的时候,这对客户端来讲是透明的。
CAP法则假定向外扩展的3个不同方面中只有两个可以同时完全实现。
为了能处理大型分布式系统,让我们深入了解所采用的不同CAP特征。
很多NOSQL数据库首先已经放宽了对于一致性(C)的要求,以期得到更好的可用性(A)和分区容忍性(P)。这产生了被称为BASE(基本(B)可用性(A)、软状态(S)、最终一致性(E))的系统。它们没有经典意义上的事务,并且在数据模型上引入了约束,以支持更好的分区模式(如Dynamo系统等)。关于CAP、ACID和BASE的更深入讨论可以在这篇介绍里找到。
2. 复杂度

蛋白质同源网络(Protein Homology Network),感谢Alex Adai:细胞和分子生物学院 - 德州大学
数据和系统的互联性增加产生了一种无法用简单明了或领域无关(domain-independent)方式进行伸缩和自动分区的稠密数据集,甚至连Todd Hoff也提到了这一问题。关于大型复杂数据集的可视化内容可以访问可视化复杂度(Visual Complexity)。
关系模型
在把关系数据模型扔进故纸堆之前,我们不应该忘记关系数据库系统成功的一个原因是遵照E.F. Codd的想法,关系数据模型通过规范化的手段原则上能够建模任何数据结构且没有信息冗余和丢失。建模完成之后,就可以使用SQL以一种非常强大的方式插入、修改和查询数据。甚至有些数据库,为了插入速度或针对不同使用情况(如OLTP、OLAP、Web应用或报表)的多维查询(星形模式),对模式实现了优化。
这只是理论。然而在实践中,RDBM遇到了前面提到的CAP问题的限制,以及由高性能查询实现而产生的问题:联结大量表、深度嵌套的SQL查询。其他问题包括伸缩性、随时间的模式演变,树形结构的建模,半结构化数据,层级和网络等。
关系模型也很难适应当前软件开发的方法,如面向对象和动态语言,这被称为对象-关系阻抗失配。由此,象Java的Hibernate这样的ORM层被开发了出来,而且被应用到这种混合环境里。它们固然简化了把对象模型映射到关系数据模型的任务,但是没有优化查询的性能。尤其是半结构化数据往往被建模成具有许多列的大型表,其中很多行的许多列是空的(稀疏表),这导致了拙劣的性能。甚至作为替代方法,把这些结构建模成大量的联结表,也有问题。因为RDBMS中的联结是一种非常昂贵的集合操作。
图形是关系规范化的一种替代技术
看看领域模型在数据结构上的方案,有两个主流学派 - RDBMS采用的关系方法和图 - 即网络结构,如语义网用到的。
尽管图结构在理论上甚至可以用RDBMS规范化,但由于关系数据库的实现特点,对于象文件树这样的递归结构和象社交图这样的网络结构有严重的查询性能影响。网络关系上的每次操作都会导致RDBMS上的一次"联结"操作,以两个表的主键集合间的集合操作来实现 ,这种操作不仅缓慢并且无法随着这些表中元组数量的增加而伸缩。
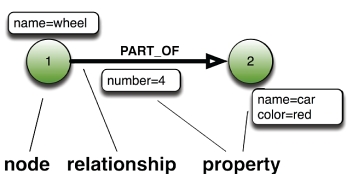
属性图形(Property Graph)的基本术语
在图的领域,并没有一套被广泛接受的术语,存在着很多不同类型的图模型。但是,有人致力于创建一种属性图形模型(Property Graph Model),以期统一大多数不同的图实现。按照该模型,属性图里信息的建模使用3种构造单元:
- 节点(即顶点)
- 关系(即边) - 具有方向和类型(标记和标向)
- 节点和关系上面的属性(即特性)
更特殊的是,这个模型是一个被标记和标向的属性多重图(multigraph)。被标记的图每条边都有一个标签,它被用来作为那条边的类型。有向图允许边有一个固定的方向,从末或源节点到首或目标节点。属性图允许每个节点和边有一组可变的属性列表,其中的属性是关联某个名字的值,简化了图形结构。多重图允许两个节点之间存在多条边。这意味着两个节点可以由不同边连接多次,即使两条边有相同的尾、头和标记。
下图显示了一个被标记的小型属性图。
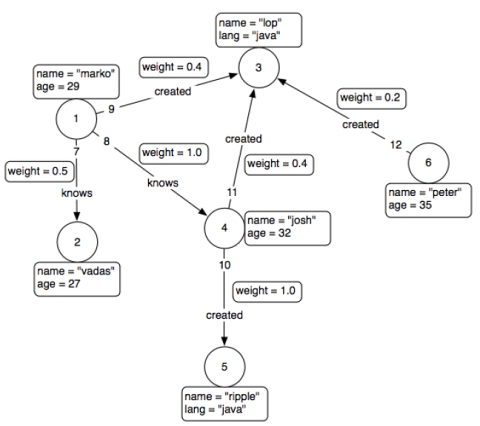
TinkerPop有关的小型人员图
图论的巨大用途被得到了认可,它跟不同领域的很多问题都有关联。最常用的图论算法包括各种类型的最短路径计算、测地线(Geodesic Path)、集中度测量(如PageRank、特征向量集中度、亲密度、关系度、HITS等)。然而,在很多情况下,这些算法的应用仅限制于研究,因为实际中没有任何可用于产品环境下的高性能图形数据库实现。幸运的是,近些年情况有所改观。有几个项目已经被开发出来,而且目标直指24/7的产品环境:
- Neo4j - 开源的Java属性图形模型
- AllegroGraph,闭源,RDF-QuadStore
- Sones - 闭源,关注于.NET
- Virtuoso - 闭源,关注于RDF
- HyergraphDB - 开源的Java超图模型
- Others like InfoGrid、Filament、FlockDB等。
下图展示了在复杂度和伸缩性方面背景下的主要NOSQL分类的位置。
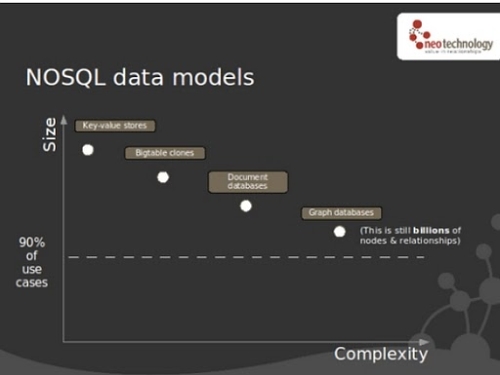
关于“规模扩展和复杂度扩展的比较”的更多内容,请阅读Emil Eifrem的博文。

 );){kind=link}