我痛恨 Git 的 10 个理由
| 2012-03-13 12:50 分享: 1
Git 是一个源代码版本控制系统,正在迅速成为开源项目的标准。它有一个强大的分布式模型,允许高级用户用分支来处理各种棘手的问题和改写历史记录。但是,要学习 Git 是需要付出更多的努力,让人不爽的命令行接口以及 Git 是如此的忽视它的使用者。
下面是我为什么如此痛恨 Git 的 10 个理由:
1. 复杂的信息模型
Git 的信息模型是很复杂的,而且你必须对他们都很了解。在这个方面上你看看 Subversion:有文件、工作目录、资源库、版本、分支和标签。你需要了解的就是这些东西,实际上,分支、标签和文件你已经了解,但如果使用 Git ,你拥有更多的概念需要了解:文件、工作树、索引、本地资源库、远程资源库、远程、提交、treeishes、分支和 stash。你需要了解比 Subversion 更多得多的知识点。
2. 让人抓狂的命令行语法
Git 的命令行语法完全是随意的而且不一致,例如 git pull 基本上跟 git merge 和 git fetch 一样,git branch 和 git checkout 合并就变成 git checkout -b,git reset 命令的不同参数做的事情完全不一样,指定文件名后命令的语义完全不同等等。
而最为壮观的就是 git am 命令了,据我所知,这是因为 Linus 在当年某个晚上为了解决通过电子邮件阅读补丁而使用的不同的补丁语法,特别是在邮件的标题上。
3. 蹩脚、让人费解的文档
说起 Git 的这个文档,我唯一想说的就是“操”。他们是为计算机科学家在写文档,而不是用户。在这里举个例子:
git-push – Update remote refs along with associated objects
如果是针对用户而言,应该描述为:
git-push – Upload changes from your local repository into a remote repository
另外一个例子:
git-rebase – Forward-port local commits to the updated upstream head
翻译: git-rebase – Sequentially regenerate a series of commits so they can be applied directly to the head node
4. 信息模型的扩散
刚才我在第一点提到的 Git 的信息模型是非常复杂的,而且还想癌细胞一样一直在扩散,当然一直在使用 Git ,就会不断的冒出各种新的概念,例如 refs, tags, the reflog, fast-forward commits, detached head state (!), remote branches, tracking, namespaces 之类的。
5. 漏洞百出的抽象
Git 包含太多不是抽象的抽象,在定义用户接口和实现上经常没有任何区别,这是可以理解的,对一个高级用户来说他需要了解一些功能的具体实现,以掌握各个命令的 微妙之处。但大量的内部细节对初学者来说简直是噩梦。有这么一个说法,关于水暖器材和瓷器,但你必须成为一个水暖工才能知道器材如何安装在瓷器上。
很多人对我的抱怨予以回应说:你无需使用所有的命令,你可以向 Subversion 一样来使用 Git。这是狡辩,就好比是告诉一个老奶奶说高速公路并不可怕,她可以在高速路上靠左边的快车道上以时速 20 公里爬行,一样的道理。Git 并没有提供任何有用的子集,每个命令都会连带着对其他命令的要求,很简单的动作经常需要很复杂的动作来撤销或者改进。
下面是一个 Github 项目维护者的一些善意的建议:
- 在分支和 master 上寻找合并的基准: ‘git merge-base master yourbranch’
- 假设你已经提交了更改记录,从对你的提交重新基准化到合并准,然后创建一个新分支
- git rebase –onto HEAD~1 HEAD
- git checkout -b my-new-branch
- 检出你的 ruggedisation 分支,然后移除提交: ‘git reset –hard HEAD~1′
- 合并新的分支到 ruggedisation: ‘git merge my-new-branch’
- 检出 master (‘git checkout master’), 合并新分支 (‘git merge my-new-branch’), 然后检查合并后的情况,接着移除合并 (‘git reset –hard HEAD~1′).
- 提交新的分支 (‘git push origin my-new-branch’) 并记录 pull 请求
翻译:“奶奶,在高速公路上开车很容易的。松开离合器,让转速超过 6000 转使车轮打滑,然后进入第一个弯道并上高速公路,看路牌到出口前,使用手刹漂移转向出口。
6. 维护简单,但是提交麻烦
Git 很强大的一点就是代码基准库的维护,你必须合并来自大量不同源的提交,非常适合大规模并行开发。但是这些都不是为大多数 Git 的用户设计的,他们只是需要编写代码,可能好几个月都在同一个分支上,对他们来说 Git 是带有 4 个手柄的双锅的咖啡机,但用户只想立即喝到咖啡。
有趣的是,我并不认为这是 Git 在设计中做的权衡。它完全是忽视了真正的用户需求、混淆架构和接口。如果你是一个架构师,那么 Git 是很棒的。但对用户来说它很糟糕,已经有不少人在为 Git 编写一些简化的接口,例如 easygit。
7. 不安全的版本控制
作为一个版本控制系统而言,它必须承诺的就是:一旦代码提交到系统,那么我将保证代码的安全,你做的任何改动你都可以找回。而 Git 食言了,有很多方法可以让整个资料库完全崩溃而且不可恢复:
- git add . / … / git push -f origin master
- git push origin +master
- git rebase -i / git push
8. 将版本控制库维护者的责任移给贡献者
在传统的开源项目中,只需要一个人负责处理分支和合并这样复杂的操作,那就是维护者。而其他人只需要简单的更新提交、更新提交、不断的更新提交。而现在 Git 让每个用户都需要了解作为维护者才需要知道的各种操作,烦不胜烦。而维护者呢,无所事事,翘起二郎腿喝咖啡。
9. Git 的历史是一堆谎言
开发工作主要的产出就是源代码,一个维护良好的代码历史就对一个产品来说非常的重要,关于重新基准化有很多的争论,多数是依赖于对凌乱合并和不可读 的日子的审美判断。而重新基准化为开发者提供一个“干净整洁”的却毫无用途历史记录,而实际上正确的解决方法是更好的日志输出以及对不想要的合并进行过 滤。
10. 简单任务也要诸多命令
如果你在开发一个开源项目,你做了一些改变,然后想与其他人分享,你只需要:
- 修改代码
- 执行 svn commit
如果你增加了一些新文件:
- 添加文件
- svn add
- svn commit
如果你的项目托管在 Github 类的网站中,那么你需要:
- Make some changes
- git add [not to be confused with svn add]
- git commit
- git push
- 到此为止,你的更改只完成了一半,接下来你需要登录到 Github,查找你的提交,然后发布一个 “pull request” ,这样其他人才可以获取你的改动
在现实中,Github 的维护者希望你的改动是功能方面的分支,他们会要求你这样操作:
- git checkout master [to make sure each new feature starts from the baseline]
- git checkout -b newfeature
- Make some changes
- git add [not to be confused with svn add]
- git commit
- git push
- 然后登录到 Github,切换到你的新特性分支,发布 “pull request”
下面是一个流程图向你展示一个典型的开发者在 Subversion 上要做的工作:
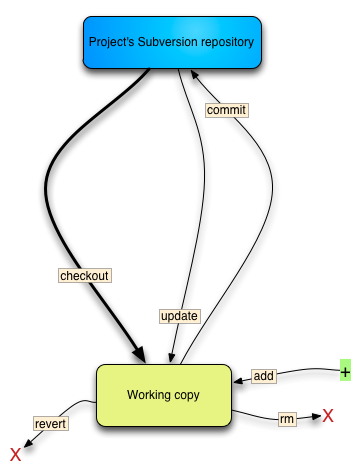
"Bread and butter" 是与远程 SVN 资料库操作的命令和概念。
然后我们再来看看如果你的项目托管在 Github 上会是怎样的:

如果 Git 的强大之处是分支和合并,那么它的弱点就是让简单的任务变得非常复杂。
文章出处:我痛恨 Git 的 10 个理由

 );){kind=link}