如何在 Linux 系统中创建一个云端加密文件系统
Amazon S3 和 Google Cloud Storage 之类的商业云存储服务以能承受的价格提供了高可用性、可扩展、无限容量的对象存储服务。为了加速这些云产品的广泛采用,这些提供商为他们的产品通过明确的 API 和 SDK 培养了一个良好的开发者生态系统。而基于云的文件系统便是这些活跃的开发者社区中的典型产品,已经有了好几个开源的实现。
S3QL 便是最流行的开源云端文件系统之一。它是一个基于 FUSE 的文件系统,提供了好几个商业或开源的云存储后端,比如 Amazon S3、Google Cloud Storage、Rackspace CloudFiles,还有 OpenStack。作为一个功能完整的文件系统,S3QL 拥有不少强大的功能:最大 2T 的文件大小、压缩、UNIX 属性、加密、基于写入时复制的快照、不可变树、重复数据删除,以及软、硬链接支持等等。写入 S3QL 文件系统任何数据都将首先被本地压缩、加密,之后才会传输到云后端。当你试图从 S3QL 文件系统中取出内容的时候,如果它们不在本地缓存中,相应的对象会从云端下载回来,然后再即时地解密、解压缩。

需要明确的是,S3QL 的确也有它的限制。比如,你不能把同一个 S3FS 文件系统在几个不同的电脑上同时挂载,只能有一台电脑同时访问它。另外,ACL(访问控制列表)也并没有被支持。
在这篇教程中,我将会描述“如何基于 Amazon S3 用 S3QL 配置一个加密文件系统”。作为一个使用范例,我还会说明如何在挂载的 S3QL 文件系统上运行 rsync 备份工具。
准备工作
本教程首先需要你创建一个 Amazon AWS 帐号(注册是免费的,但是需要一张有效的信用卡)。
然后 创建一个 AWS access key(access key ID 和 secret access key),S3QL 使用这些信息来访问你的 AWS 帐号。
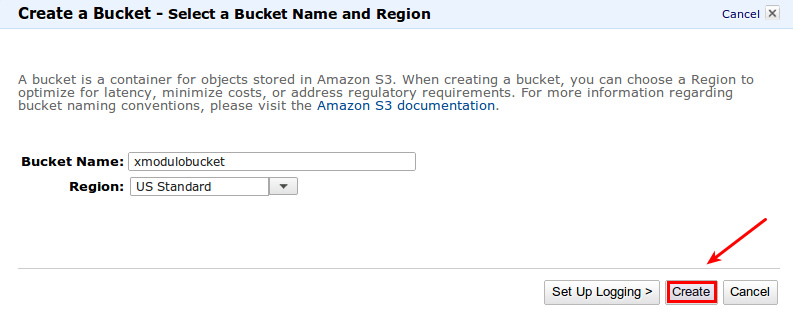
之后通过 AWS 管理面板访问 AWS S3,并为 S3QL 创建一个新的空 bucket。
为最佳性能考虑,请选择一个地理上距离你最近的区域。
在 Linux 上安装 S3QL
在大多数 Linux 发行版中都有预先编译好的 S3QL 软件包。
对于 Debian、Ubuntu 或 Linux Mint:
$ sudo apt-get install s3ql
对于 Fedora:
$ sudo yum install s3ql
对于 Arch Linux,使用 AUR。
首次配置 S3QL
在 ~/.s3ql 目录中创建 autoinfo2 文件,它是 S3QL 的一个默认的配置文件。这个文件里的信息包括必须的 AWS access key,S3 bucket 名,以及加密口令。这个加密口令将被用来加密一个随机生成的主密钥,而主密钥将被用来实际地加密 S3QL 文件系统数据。
$ mkdir ~/.s3ql $ vi ~/.s3ql/authinfo2
[s3] storage-url: s3://[bucket-name] backend-login: [your-access-key-id] backend-password: [your-secret-access-key] fs-passphrase: [your-encryption-passphrase]
指定的 AWS S3 bucket 需要预先通过 AWS 管理面板来创建。
为了安全起见,让 authinfo2 文件仅对你可访问。
$ chmod 600 ~/.s3ql/authinfo2
创建 S3QL 文件系统
现在你已经准备好可以在 AWS S3 上创建一个 S3QL 文件系统了。
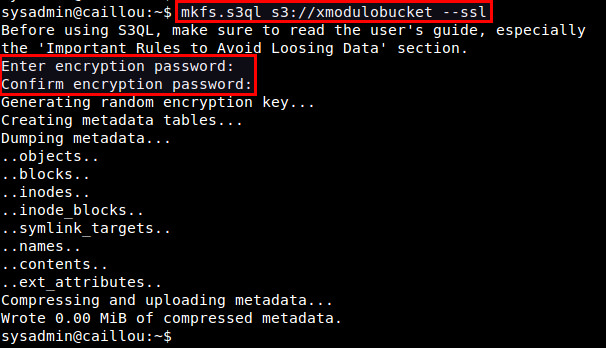
使用 mkfs.s3ql 工具来创建一个新的 S3QL 文件系统。这个命令中的 bucket 名应该与 authinfo2 文件中所指定的相符。使用“--ssl”参数将强制使用 SSL 连接到后端存储服务器。默认情况下,mkfs.s3ql 命令会在 S3QL 文件系统中启用压缩和加密。
$ mkfs.s3ql s3://[bucket-name] --ssl
你会被要求输入一个加密口令。请输入你在 ~/.s3ql/autoinfo2 中通过“fs-passphrase”指定的那个口令。
如果一个新文件系统被成功创建,你将会看到这样的输出:
挂载 S3QL 文件系统
当你创建了一个 S3QL 文件系统之后,下一步便是要挂载它。
首先创建一个本地的挂载点,然后使用 mount.s3ql 命令来挂载 S3QL 文件系统。
$ mkdir ~/mnt_s3ql $ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
挂载一个 S3QL 文件系统不需要特权用户,只要确定你对该挂载点有写权限即可。
视情况,你可以使用“--compress”参数来指定一个压缩算法(如 lzma、bzip2、zlib)。在不指定的情况下,lzma 将被默认使用。注意如果你指定了一个自定义的压缩算法,它将只会应用到新创建的数据对象上,并不会影响已经存在的数据对象。
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
因为性能原因,S3QL 文件系统维护了一份本地文件缓存,里面包括了最近访问的(部分或全部的)文件。你可以通过“--cachesize”和“--max-cache-entries”选项来自定义文件缓存的大小。
如果想要除你以外的用户访问一个已挂载的 S3QL 文件系统,请使用“--allow-other”选项。
如果你想通过 NFS 导出已挂载的 S3QL 文件系统到其他机器,请使用“--nfs”选项。
运行 mount.s3ql 之后,检查 S3QL 文件系统是否被成功挂载了:
$ df ~/mnt_s3ql $ mount | grep s3ql

卸载 S3QL 文件系统
想要安全地卸载一个(可能含有未提交数据的)S3QL 文件系统,请使用 umount.s3ql 命令。它将会等待所有数据(包括本地文件系统缓存中的部分)成功传输到后端服务器。取决于等待写的数据的多少,这个过程可能需要一些时间。
$ umount.s3ql ~/mnt_s3ql
查看 S3QL 文件系统统计信息及修复 S3QL 文件系统
若要查看 S3QL 文件系统统计信息,你可以使用 s3qlstat 命令,它将会显示诸如总的数据、元数据大小、重复文件删除率和压缩率等信息。
$ s3qlstat ~/mnt_s3ql

你可以使用 fsck.s3ql 命令来检查和修复 S3QL 文件系统。与 fsck 命令类似,待检查的文件系统必须首先被卸载。
$ fsck.s3ql s3://[bucket-name]
S3QL 使用案例:Rsync 备份
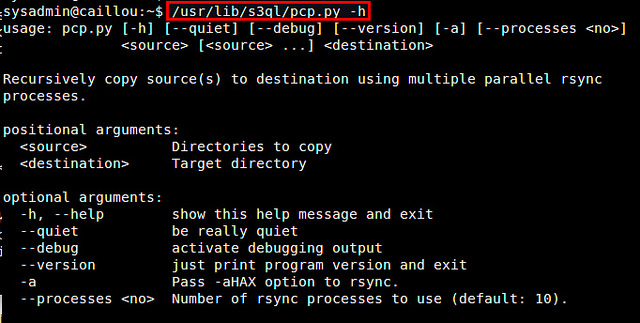
让我用一个流行的使用案例来结束这篇教程:本地文件系统备份。为此,我推荐使用 rsync 增量备份工具,特别是因为 S3QL 提供了一个 rsync 的封装脚本(/usr/lib/s3ql/pcp.py)。这个脚本允许你使用多个 rsync 进程递归地复制目录树到 S3QL 目标。
$ /usr/lib/s3ql/pcp.py -h
下面这个命令将会使用 4 个并发的 rsync 连接来备份 ~/Documents 里的所有内容到一个 S3QL 文件系统。
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
这些文件将首先被复制到本地文件缓存中,然后在后台再逐步地同步到后端服务器。
若想了解与 S3QL 有关的更多信息,如自动挂载、快照、不可变树,我强烈推荐阅读 官方用户指南。欢迎告诉我你对 S3QL 怎么看,以及你对任何其他工具的使用经验。
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
作者:Dan Nanni 译者:felixonmars 校对:wxy


 );){kind=link}