配置高可用的Hadoop平台
1.概述
在Hadoop2.x之后的版本,提出了解决单点问题的方案--HA(High Available 高可用)。这篇博客阐述如何搭建高可用的HDFS和YARN,执行步骤如下:
- 创建hadoop用户
- 安装JDK
- 配置hosts
- 安装SSH
- 关闭防火墙
- 修改时区
- ZK(安装,启动,验证)
- HDFS+HA的结构图
- 角色分配
- 环境变量配置
- 核心文件配置
- slave
- 启动命令(hdfs和yarn的相关命令)
- HA的切换
- 效果截图
下面我们给出下载包的链接地址:
注:若JDK无法下载,请到Oracle的官网下载JDK。
到这里安装包都准备好了,接下来我们开始搭建与配置。
2.搭建
2.1创建Hadoop用户
useradd hadoop passwd hadoop
然后根据提示,设置密码。接着我给hadoop用户设置面免密码权限,也可自行添加其他权限。
chmod +w /etc/sudoers hadoop ALL=(root)NOPASSWD:ALL chmod -w /etc/sudoers
2.2安装JDK
将下载好的安装包解压到 /usr/java/jdk1.7,然后设置环境变量,命令如下:
sudo vi /etc/profile
然后编辑配置,内容如下:
export JAVA_HOME=/usr/java/jdk1.7 export PATH=$PATH:$JAVA_HOME/bin
然后使环境变量立即生效,命令如下:
source /etc/profile
然后验证JDK是否配置成功,命令如下:
java -version
若显示对应版本号,即表示JDK配置成功。否则,配置无效!
2.3配置hosts
集群中所有机器的hosts配置要要相同(推荐)。可以避免不必要的麻烦,用域名取代IP,方便配置。配置信息如下:
10.211.55.12 nna # NameNode Active 10.211.55.13 nns # NameNode Standby 10.211.55.14 dn1 # DataNode1 10.211.55.15 dn2 # DataNode2 10.211.55.16 dn3 # DataNode3
然后用scp命令,将hosts配置分发到各个节点。命令如下:
# 这里以NNS节点为例子 scp /etc/hosts hadoop@nns:/etc/
2.4安装SSH
输入如下命令:
ssh-keygen –t rsa
然后一路按回车键,最后在将id_rsa.pub写到authorized_keys,命令如下:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
在hadoop用户下,需要给authorized_keys赋予600的权限,不然免密码登陆无效。在其他节点只需要使用 ssh-keygen –t rsa 命令,生产对应的公钥,然后将各个节点的id_rsa.pub追加到nna节点的authorized_keys中。最后,将nna节点下的authorized_keys文件通过scp命令,分发到各个节点的 ~/.ssh/ 目录下。目录如下:
# 这里以NNS节点为例子 scp ~/.ssh/authorized_keys hadoop@nns:~/.ssh/
然后使用ssh命令相互登录,看是否实现了免密码登录,登录命令如下:
# 这里以nns节点为例子 ssh nns
若登录过程中木有提示需要输入密码,即表示密码配置成功。
2.5关闭防火墙
由于hadoop的节点之间需要通信(RPC机制),这样一来就需要监听对应的端口,这里我就直接将防火墙关闭了,命令如下:
chkconfig iptables off
注:如果用于生产环境,直接关闭防火墙是存在安全隐患的,我们可以通过配置防火墙的过滤规则,即将hadoop需要监听的那些端口配置到防火墙接受规则中。关于防火墙的规则配置参见“linux防火墙配置”,或者通知公司的运维去帮忙配置管理。
同时,也需要关闭SELinux,可修改 /etc/selinux/config 文件,将其中的 SELINUX=enforcing 改为 SELINUX=disabled即可。
2.6修改时区
各个节点的时间如果不同步,会出现启动异常,或其他原因。这里将时间统一设置为Shanghai时区。命令如下:
# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime cp: overwrite `/etc/localtime'? yes 修改为中国的东八区 # vi /etc/sysconfig/clock ZONE="Asia/Shanghai" UTC=false ARC=false
2.7ZK(安装,启动,验证)
2.7.1安装
将下载好的安装包,解压到指定位置,这里为直接解压到当前位置,命令如下:
tar -zxvf zk-{version}.tar.gz
修改zk配置,将zk安装目录下conf/zoo_sample.cfg重命名zoo.cfg,修改其中的内容:
# The number of milliseconds of each tick # 服务器与客户端之间交互的基本时间单元(ms) tickTime=2000 # The number of ticks that the initial # synchronization phase can take # zookeeper所能接受的客户端数量 initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement # 服务器和客户端之间请求和应答之间的时间间隔 syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # 保存zookeeper数据,日志的路径 dataDir=/home/hadoop/data/zookeeper # the port at which the clients will connect # 客户端与zookeeper相互交互的端口 clientPort=2181 server.1= dn1:2888:3888 server.2= dn2:2888:3888 server.3= dn3:2888:3888 #server.A=B:C:D
#其中A是一个数字,代表这是第几号服务器;B是服务器的IP地址;
#C表示服务器与群集中的“领导者”交换信息的端口;当领导者失效后,D表示用来执行选举时服务器相互通信的端口。
接下来,在配置的dataDir目录下创建一个myid文件,里面写入一个0-255之间的一个随意数字,每个zk上这个文件的数字要是不一样的,这些数字应该是从1开始,依次写每个服务器。文件中序号要与dn节点下的zk配置序号一直,如:server.1=dn1:2888:3888,那么dn1节点下的myid配置文件应该写上1。
2.7.2启动
分别在各个dn节点启动zk进程,命令如下:
bin/zkServer.sh start
然后,在各个节点输入jps命令,会出现如下进程:
QuorumPeerMain
2.7.3验证
上面说的输入jps命令,若显示对应的进程,即表示启动成功,同样我们也可以输入zk的状态命令查看,命令如下:
bin/zkServer.sh status
会出现一个leader和两个follower。
2.8HDFS+HA的结构图
HDFS配置HA的结构图如下所示:
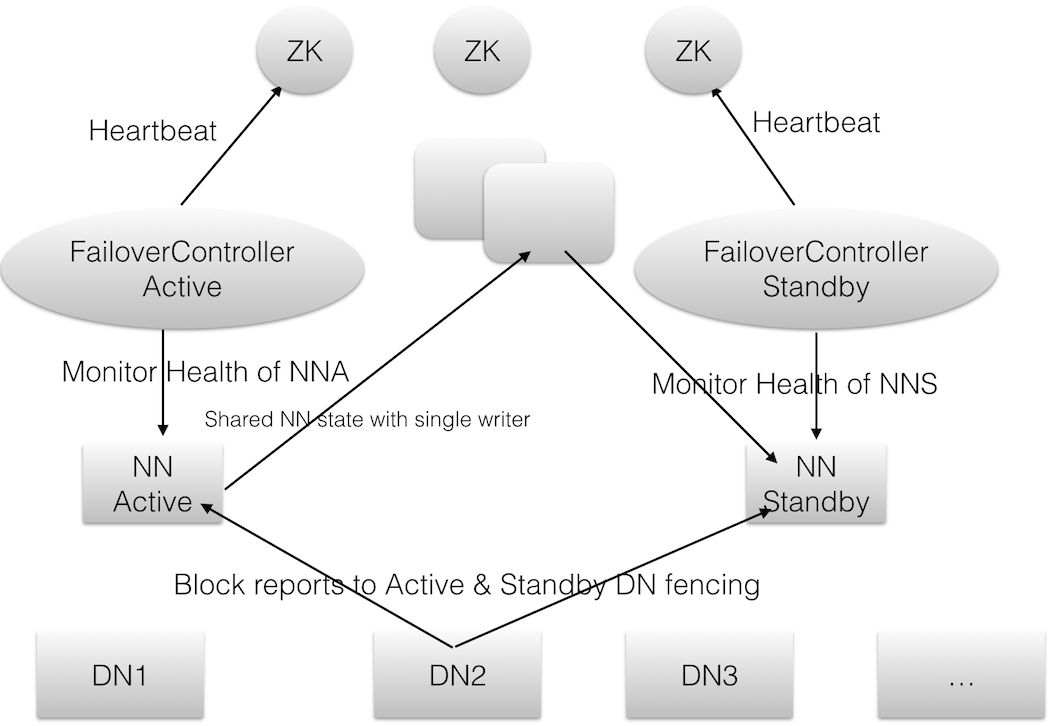
上图大致架构包括:
1. 利用共享存储来在两个NN间同步edits信息。以前的HDFS是share nothing but NN,现在NN又share storage,这样其实是转移了单点故障的位置,但中高端的存储设备内部都有各种RAID以及冗余硬件,包括电源以及网卡等,比服务器的可靠性还是略有 提高。通过NN内部每次元数据变动后的flush操作,加上NFS的close-to-open,数据的一致性得到了保证。
2. DN同时向两个NN汇报块信息。这是让Standby NN保持集群的最新状态的必须步骤。
3. 用于监视和控制NN进程的FailoverController进程。显然,我们不能在NN进程内部进行心跳等信息同步,最简单的原因,一次FullGC 就可以让NN挂起十几分钟,所以,必须要有一个独立的短小精悍的watchdog来专门负责监控。这也是一个松耦合的设计,便于扩展或更改,目前版本里是 用ZooKeeper(简称ZK)来做同步锁,但用户可以方便的把这个Zookeeper FailoverController(简称ZKFC)替换为其他的HA方案或leader选举方案。
4. 隔离(Fencing),防止脑裂,就是保证在任何时候只有一个主NN,包括三个方面:
共享存储fencing,确保只有一个NN可以写入edits。
客户端fencing,确保只有一个NN可以响应客户端的请求。
DN fencing,确保只有一个NN向DN下发命令,譬如删除块,复制块等等。
2.9角色分配
|
名称 |
Host |
职责 |
|
NNA |
10.211.55.12 |
zkfc |
|
NNS |
10.211.55.13 |
zkfc |
|
DN1 |
10.211.55.14 |
zookeeper |
|
DN2 |
10.211.55.15 |
zookeeper |
|
DN3 |
10.211.55.16 |
zookeeper |
2.10环境变量配置
这里列出了所有的配置,后面配置其他组件,可以参考这里的配置。 配置完成后,输入:. /etc/profile(或source /etc/profile)使之立即生效。严重是否环境变量配置成功与否,输入:echo $HADOOP_HOME,若输出对应的配置路径,即可认定配置成功。
注:hadoop2.x以后的版本conf文件夹改为etc文件夹了
配置内容如下所示:
export JAVA_HOME=/usr/java/jdk1.7 export HADOOP_HOME=/home/hadoop/hadoop-2.6.0 export ZK_HOME=/home/hadoop/zookeeper-3.4.6 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOM
2.11核心文件配置
注:这里特别提醒,配置文件中的路径在启动集群之前,得存在(若不存在,请事先创建)。下面为给出本篇文章需要创建的路径脚本,命令如下:
mkdir -p /home/hadoop/tmp mkdir -p /home/hadoop/data/tmp/journal mkdir -p /home/hadoop/data/dfs/name mkdir -p /home/hadoop/data/dfs/data mkdir -p /home/hadoop/data/yarn/local mkdir -p /home/hadoop/log/yarn
- core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
- hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nna,nns</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nna</name>
<value>nna:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nns</name>
<value>nns:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nna</name>
<value>nna:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nns</name>
<value>nns:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dn1:8485;dn2:8485;dn3:8485/cluster1</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/tmp/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
- map-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nna:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nna:19888</value>
</property>
</configuration>
- yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nna</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nns</value>
</property>
<!--在namenode1上配置rm1,在namenode2上配置rm2,注意:一般都喜欢把配置好的文件远程复制到其它机器上,但这个在YARN的另一个机器上一定要修改 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!--开启自动恢复功能 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置与zookeeper的连接地址 -->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1-yarn</value>
</property>
<!--schelduler失联等待连接时间 -->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nna:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nna:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nna:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>nna:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nna:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>nna:23142</value>
</property>
<!--配置rm2 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nns:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nns:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nns:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nns:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nns:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>nns:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/log/yarn</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--故障处理类 -->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
</configuration>
- hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/usr/java/jdk1.7
- yarn-env.sh
# some Java parameters export JAVA_HOME=/usr/java/jdk1.7
- 2.12slave
修改hadoop安装目录下的slave文件:
dn1 dn2 dn3
2.13启动命令(hdfs和yarn的相关命令)
由于我们配置了QJM,所以我们需要先启动QJM的服务,启动顺序如下所示:
- 进入到DN节点,启动zk的服务:zkServer.sh start,之后可以输入zkServer.sh status查看启动状态,本次我们配置了三个DN节点,会出现一个leader和两个follower。输入jps,会显示启动进程:QuorumPeerMain
- 在NN节点上(选一台即可,这里我选择的是一台预NNA节点),然后启动journalnode服务,命令如下:hadoop-daemons.sh start journalnode。或者单独进入到每个DN输入启动命令:hadoop-daemon.sh start journalnode。输入jps显示启动进程:JournalNode。
- 接着若是配置后,我们首次启动,需要格式化HDFS,命令如下:hadoop namenode –format。
- 之后我们需要格式化ZK,命令如下:hdfs zkfc –formatZK。
- 接着我们启动hdfs和yarn,命令如下:start-dfs.sh和start-yarn.sh,我们在nna输入jps查看进程,显示如下:DFSZKFailoverController,NameNode,ResourceManager。
- 接着我们在NNS输入jps查看,发现只有DFSZKFailoverController进程,这里我们需要手动启动NNS上的namenode和ResourceManager进程,命令如下:hadoop-daemon.sh start namenode和yarn-daemon.sh start resourcemanager。需要注意的是,在NNS上的yarn-site.xml中,需要配置指向NNS,属性配置为rm2,在NNA中配置的是rm1。
- 最后我们需要同步NNA节点的元数据,命令如下:hdfs namenode –bootstrapStandby,若执行正常,日志最后显示如下信息:
15/02/21 10:30:59 INFO common.Storage: Storage directory /home/hadoop/data/dfs/name has been successfully formatted. 15/02/21 10:30:59 WARN common.Util: Path /home/hadoop/data/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration. 15/02/21 10:30:59 WARN common.Util: Path /home/hadoop/data/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration. 15/02/21 10:31:00 INFO namenode.TransferFsImage: Opening connection to http://nna:50070/imagetransfer?getimage=1&txid=0&storageInfo=-60:1079068934:0:CID-1dd0c11e-b27e-4651-aad6-73bc7dd820bd 15/02/21 10:31:01 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds 15/02/21 10:31:01 INFO namenode.TransferFsImage: Transfer took 0.01s at 0.00 KB/s 15/02/21 10:31:01 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 353 bytes. 15/02/21 10:31:01 INFO util.ExitUtil: Exiting with status 0 15/02/21 10:31:01 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at nns/10.211.55.13 ************************************************************/
2.14HA的切换
由于我配置的是自动切换,若NNA节点宕掉,NNS节点会立即由standby状态切换为active状态。若是配置的手动状态,可以输入如下命令进行人工切换:
hdfs haadmin -failover --forcefence --forceactive nna nns
这条命令的意思是,将nna变成standby,nns变成active。而且手动状态下需要重启服务。
2.15效果截图
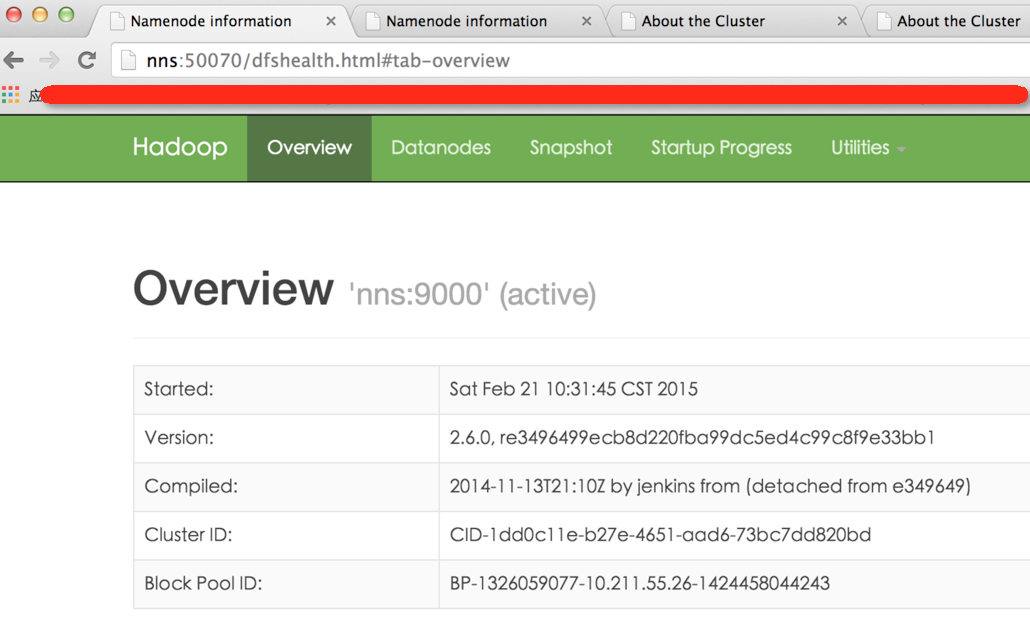
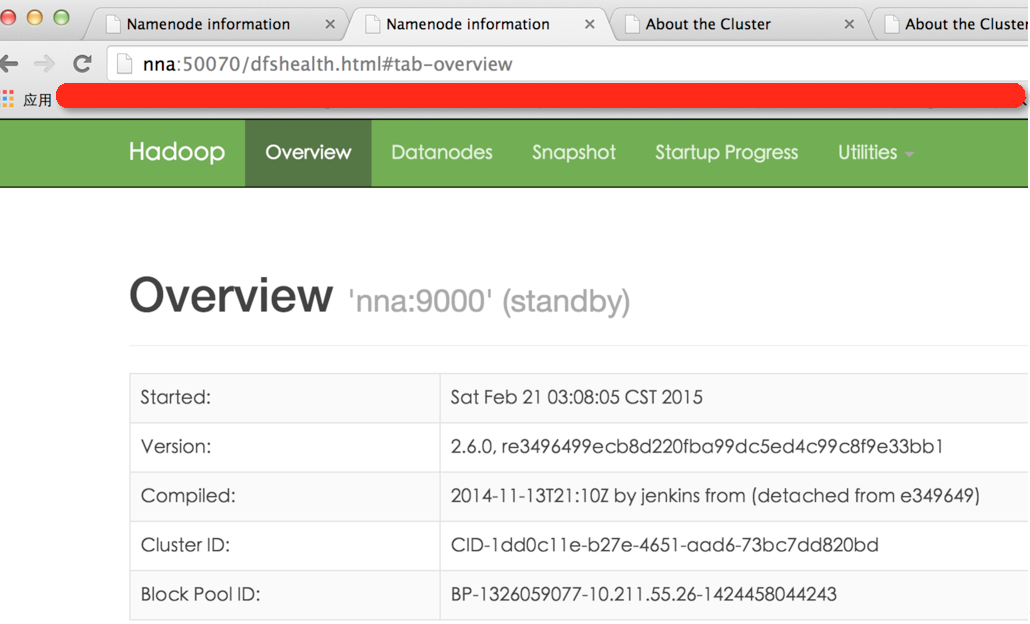

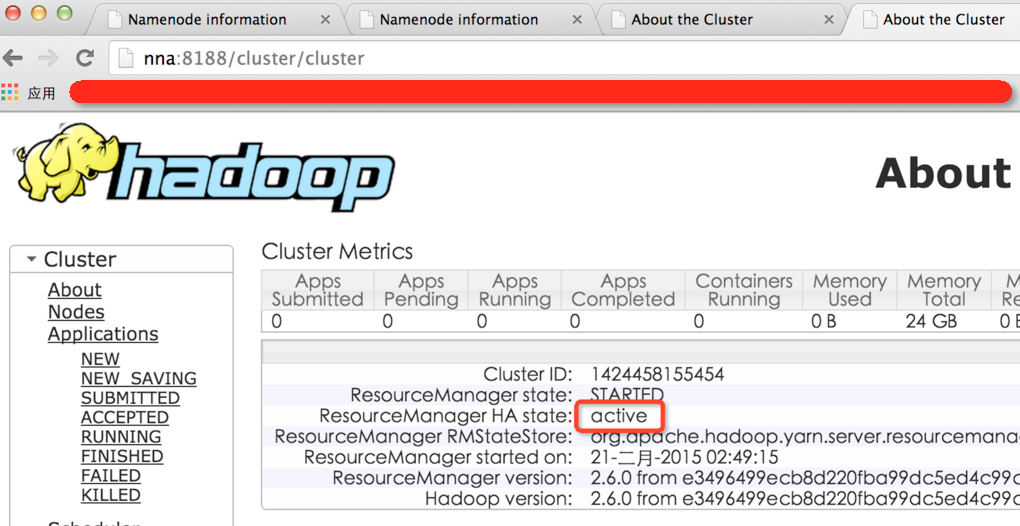
3.总结
这篇文章就赘述到这里,若在配置过程中有什么疑问或问题,可以加入QQ群讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!

 );){kind=link}