CoreOS那些事之系统升级
前段时间在DockerOne回复了一个关于 CoreOS 升级的提问。仔细琢磨来,这个问题还有不少可深入之处,因此有了此文,供已经在国内使用 CoreOS 的玩家们参考。

具有CoreOS特色的系统升级
CoreOS的设计初衷之一就是“解决互联网上普遍存在的服务器系统及软件由于没有及时升级和应用补丁,造成已知漏洞被恶意利用导致的安全性问题”。因此,它的升级方式在各种Linux发型版中可以说是独树一帜的,特别是与主流的服务器端系统相比。
平滑升级
一方面来说,常用的服务器系统如RedHat、CentOS、Debian、Ubuntu甚至FreeBSD和Windows Server都存在明确的版本界限,要么不能支持直接在线升级至新的发行版本,要么(如Debian/Ubuntu和Windows 7以后的版本)虽能够跨版本升级却容易出现兼容性风险,一旦升级后出现故障往往面临进退两难的局面。
这个问题在一些新兴的Linux发行版,如Arch Linux已经有了较先进的解决方法:将过去累计许多补丁再发行一次大版本的做法变为以月或更短周期的快速迭代更新,并由系统本身提供平滑升级和回滚的支持。这样,用户可以在任何时候、从任何版本直接更新至修了最新安全补丁的系统。然而,这些以 Arch 为代表的平滑升级系统还是带来了一些更新系统后无法使用的事故,不妨在百度以“Arch 升级问题”关键字搜索会发现许多类似的抱怨。事实上,Arch的目标用户主要是喜爱尝鲜的Linux爱好者而不是服务器管理员或者服务端应用架构师。
那么平滑升级的思路是不是在服务器系统就走不通了呢。其实仔细分析平滑升级出现问题的原因,当中最关键的一个因素在于,系统设计时最多只能确保从一个干净的系统顺利升级的途径,如果用户对系统中的某些核心组件做了修改(比如将系统中的Python2升级成了Python3),它就不属于操作系统设计者控制范围内的工作了。这样相当于设定了一个售后服务霸王条款(只是个比喻,这些Linux系统其实都是免费的):自行改装,不予保修。
在过去,用户要使用服务器系统,他就必然需要在上面安装其他的提供对外服务软件和程序,因此对系统本身有意无意的修改几乎是无法避免的。这个问题直到近些年来应用容器(特别是Docker)的概念被大规模的推广以后才出现了新的解决思路。而CoreOS就是通过容器巧妙的避开了用户篡改系统的问题,提出了另一种解决思路:让系统分区只读,用户通过容器运行服务。不得不说,这简直就是以一个霸王条款替代了另一个霸王条款,然而这个新的“条款”带来的附加好处,使得它被对稳定性和安全性都要求很高的服务器领域而言接受起来要心安理得的多。
“反正许多东西都要自动化的,套个容器又何妨。” 恩,就这么愉快的决定了。
自动更新
另一方面来说,除了系统的大版本升级,平时的系统和关键软件的小幅补丁更新也时常由于系统管理员的疏忽而没有得到及时运用,这同样是导致系统安全问题的一个重要因素(比如2014年BrowserStack中招的这个例子)。
这个解决思路就比较简单了:自动更新。这么简单的办法当然早就被人用过了。即便在操作系统层面还见得不多,在应用软件上早都是烂熟的套路。那么,为了不落俗套,怎样把自动更新做得创意一些呢。先来看看系统升级都会有哪些坑。
乍一看来,操作系统这个东东和普通应用在升级时候会遇到的问题还是有几分相似。比如软件正在使用的时候一般是不可以直接热修补的,系统也一样(Linux 4.0 内核已经在着手解决这个痛点了,因此它在未来可能会成为伪命题)。又比如软件运行会有依赖,而系统的核心组件之间也是有依赖的,因此一旦涉及升级就又涉及了版本匹配问题。除此之外,它们之间还是有些不一样的地方。比如许多应用软件其实可以直接免安装的,升级时候直接把新文件替换一下旧的就算完成了。操作系统要想免安装,则需要些特别的技巧。
下面依次来说说CoreOS是怎样应对这几个坑的。
既然系统不能热修补,就一定会牵扯到重启的情况,这在服务器系统是比较忌讳的,为了避免系统重启时对外服务中断,CoreOS设计了服务自动迁移的内置功能,由其核心组件Fleet提供。当然这个并不是一个完美的方案,相信未来还会有更具创意的办法替代它的。
版本匹配的问题在应用软件层面比较好的解决方法还是容器,即把所有依赖打包在一起部署,每次更新就更新整个容器的镜像。同样的思路用到操作系统上,CoreOS每次更新都是一次整体升级,下载完整的系统镜像,然后做MD5校验,最后重启一下系统,把内核与外围依赖整个儿换掉。这样带来的额外好处是,每次升级必然是全部成功或者全部失败,不会存在升级部分成功的尴尬情况。
要想免安装软件那样直接重启换系统会遇到什么问题呢?两个方面,其一是,应用软件是由操作系统托管和启动的,可以通过系统来替换他的文件。那么操作系统自己呢,是由引导区的几行启动代码带动的,想在这么一亩三分地上提取镜像、替换系统、还想搞快点别太花时间,额,那真是螺蛳壳里做道场——排不出场面(还记得Window或者Mac电脑每次升级系统时候的等待界面么)。其二是,系统升级出问题是要能回滚的啊,不然怎么在生产环境用?即便不考虑启动时替换文件所需要的时间,万一更新过后启动不起来,原来的系统又已经被覆盖了,我天,这简直是给自己埋了一个地雷。由此可见,想要实现快速安全的升级,在重启后安装更新的做法从启动时间和回滚难度的两个方面看都不是最佳的办法。
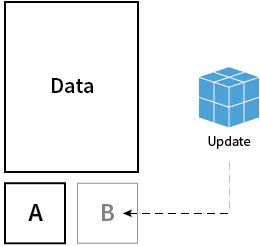
为此,CoreOS又有一招绝活。进过CoreOS的主页的读者应该都见过上面这个A/B双系统分区的设计图。正如图中所示,CoreOS安装时就会在硬盘上划出两块独立的系统分区(空间大致为每个1GB),并且每次只将其中一个在作为系统内核使用,而后台下载好的新系统镜像会在系统运行期间就部署到备用的那个分区上。重启的时候只需要设计个逻辑切换两个分区的主次分工即可,不到分分钟就完成了升级的过程,要是真出现启动失败的情况,CoreOS会自动检测到并切换回原来的能正常工作的分区。用事先部署好的分区直接替换启动的方法避免重启后临时安装更新,这种思路的转换,确实有点神来之笔的意思。
说个题外话。之前有一次我和其他的CoreOS爱好者在Meetup活动时聊到对于双系统分区的看法,当时大家得出较一致的结论是:既然还是必须重启,用不用两个分区用户都没有实际获益,相比之下,“平滑升级才是卖点,双分区只是噱头”。我在《CoreOS实践指南》系列里也曾表达过类似的观点。一直到后来自己仔细反思了这种设计的巧妙,才发觉原先想法的片面性,实在贻笑大方。
这些方法说起来蛮轻松,若要真的实施出来,就不是拍拍脑袋那么容易了。纵观Linux开源系统百家争鸣,真正实现了这样后台更新设计的系统也仅CoreOS一枝独秀。
升级参数配置
理解了CoreOS的自升级方式,继续来说说与升级相关的配置。CoreOS系统升级有关的选项通常会在首次启动服务器时通过 cloud-init 的 coreos.update 项指定,系统启动后也可以在/etc/coreos/update.conf 文件里修改。可配置的属性包括三个:升级通道、升级策略和升级服务器。这三个属性在DockerOne的回答中都已经提到,下面将在此基础上再略作深化。
初始化升级配置
这是最常用的配置升级参数的方式,系统首次启动时cloud-init将完成大多数节点和集群相关的初始化任务。与CoreOS升级有关的部分是coreos.update下面的三个键,其内容举例如下:
coreos:
update:
reboot-strategy: best-effort
group: alpha
server: https://example.update.core-os.net其中只有group一项是必须的,它指定了系统的升级通道。升级策略 reboot-strategy的默认值是best-effort,而升级服务器server的默认值是CoreOS的官方升级服务器。
修改升级配置
对于已经启动的集群,可以在/etc/coreos/update.conf配置文件中对升级参数进行修改,其内容格式简单明了。举例如下:
GROUP=alpha
REBOOT_STRATEGY=best-effort
SERVER=https://example.update.core-os.net同样,大多数情况下用户只会看到GROUP这一个值,因为只有它是必须的。其余的两行可以没有,此时会使用默认值代替。
需要注意的是:
- 每次修改完成以后需要执行
sudo systemctl restart update-engine命令使配置生效 - 修改一个节点的配置并不会影响集群其他节点的升级配置,需要逐一单独修改
- 最好让集群中的节点使用相同的升级通道,方便管理,虽然混用通道一般不会直接导致问题
- 优先选择用cloud-init。在初始化时就将系统参数设计好,减少额外修改的工作量
升级通道
升级通道间接的定义了CoreOS每次升级的目标版本号。这个思路大概是从Chrome浏览器借鉴来的,官方提供三个升级通道:Alpha(内测版)、Beta(公测版 )和 Stable(正式发行版)。举个例子来说,如果用户配置的是Alpha通道,那么他的每次更新就会升级到当前最新的内测系统版本上。内存版本类似于Chrome浏览器的所谓“开发版”,会第一时间获得新的功能更新,稳定性一般还是蛮可以的,但不适合做为产品服务器,主要面向的对象是喜爱新鲜的开发者和玩家。公测版稳定性略高,也会比较快的获得新功能的推送,适合作为项目开发测试环境把玩。正式发行版中的组件往往都不是最新版本的,但其稳定性最高,适合作为产品服务器使用。CoreOS目前采用一个整数数字来表示版本号,数字越大则相对发布时间越新。
各通道发布更新的频率依次为(见官方博客声明):
- Alpha:每周星期四发布
- Beta:每两周发布一次
- Stable:每个月发布一次
每个通道当前的系统版本号及内置组件版本号可以在这个网页上查看到。
除了三个公开的通道,订阅了CoreUpdate服务的用户还可以定制升级自己的通道,但这个服务是付费的。此外,使用了企业版托管CoreOS系统的用户也可以免费使用此功能,企业版的起步费用是10个节点以内 $100/月,见这个链接。还有另一个土豪企业版服务起步价是25个节点以内 $2100/月,差别就是提供额外的人工技术支持服务,果然技术人才是最贵的东东。
升级策略
升级策略主要与自动升级后的重启更新方式有关。它的值可以是 best-effort(默认值)、 etcd-lock、 reboot 和off。其作用依次解释如下:
- best-effort:如果Etcd运行正常则相当于 etcd-lock,否则相当于reboot
- etcd-lock:自动升级后自动重启,使用LockSmith 服务调度重启过程
- reboot:自动升级后立即自动重启系统
- off:自动升级后等待用户手工重启
默认的方式是best-effort,通常它相当于etcd-lock策略,重启过程会使用到CoreOS的LockSmith服务调度升级过程。主要是防止过多的节点同时重启导致对外服务中断和Etcd的Leader节点选举无法进行。它的工作原理本身很简单,通过在Etcd的coreos.com/updateengine/rebootlock/semaphore 路径可用看到它的全部配置:
$ etcdctl get coreos.com/updateengine/rebootlock/semaphore
{
"semaphore": 0,
"max": 1,
"holders":
[
"010a2e41e747415ba51212fa995801dd"
]
}通过设定固定数量的锁,只有获得锁的主机才能够进行重启升级,否则就继续监听锁的变化。重启升级后的节点会释放它占用的锁,从而通知其他节点开始下一轮获取升级锁的竞争。
除了直接修改Etcd的内容,CoreOS还提供了 locksmithctl 命令更直观的查看LockSmith服务的状态或设置升级锁的数量。
查看升级锁的状态信息:
$ locksmithctl status
Available: 0 <-- 剩余的锁数量
Max: 1 <-- 锁的总数
MACHINE ID
010a2e41e747415ba51212fa995801dd <-- 获得锁的节点其中获得锁的节点就是已经已经下载部署好新版本系统,等待或即将重启(与升级策略有关)的节点的Machine ID。用locksmithctl set-max 命令可用修改升级锁数量(即允许同时重启升级的节点数量):
$ locksmithctl set-max 3
Old: 1
New: 3此时若再次用locksmithctl status查看状态就会看到 Max 的数量变成3了。
此外,locksmithctl unlock 命令可以将升级锁从获得锁的节点上释放,这个命令很少会用到,除非一个节点获得锁后由于特殊的原因无法重启(例如磁盘错误等硬件故障),因而始终占用这个锁。这种情况下才会需要手工释放。
升级服务器
许多希望在内网中使用CoreOS的用户都比较关心能否在内网搭建自己的升级服务器?答案是肯定的。
比较可惜的是,CoreOS 升级服务器是属于CoreUpdate服务的一部分,也就是说,它是需要付费使用的。不过考虑到通常会在自己内网搭建服务器集群的大都是企业级用户,收费也还算公道。
从文档资料来看,CoreOS所用升级服务器协议与Google的ChromeOS升级服务器是完全兼容的,甚至可以相互替代。比较有趣的是,两者都开源了各自的操作系统,但都没有开源其升级服务器实现,这个中意思仿佛是如果让用户去自己架设升级服务器,谁来保证这些升级服务器的镜像是最新的呢,那么自动升级提供的系统安全性的意义又何在了呢。
顺带说一句,在CoreOS的SDK中有一个 start_devserver工具 用于测试部署用户自己构建的CoreOS镜像(系统是开源的嘛),因此如果用户直接下载官方镜像提供给这个工具,应当是可以自己构建内网升级服务器的。但是官方文档对这方面的介绍比较模糊,我暂且抛砖引玉了,待高人给出具体方案。
手动升级系统
CoreOS始终会自动在后台下载和部署新版本系统,即使将升级策略设为off(这样只是禁止自动重启)。因此在绝大多数情况下,除非处于测试目的和紧急的版本修复,用户是不需要手动触发系统升级的。不过,大概是考虑到总是有新版本强迫症用户的需求(其实主要是系统测试的需求啦),CoreOS还是提供了手动更新的途径。
查看当前系统版本
相比手动更新,用户也许更想看到的仅仅是:现在的系统到底是部署的哪个版本啦。方法很简单,查看一下etc目录下面的 os-release 文件就可以了。
$ cat /etc/os-release
NAME=CoreOS
ID=coreos
VERSION=607.0.0
VERSION_ID=607.0.0
BUILD_ID=
PRETTY_NAME="CoreOS 607.0.0"
ANSI_COLOR="1;32"
HOME_URL="https://coreos.com/"
BUG_REPORT_URL="https://github.com/coreos/bugs/issues"这个文件实际上是一个软链接,指向系统分区的 /usr/lib/os-release 文件,而后者是只读分区的一部分,因此不用担心这个文件中的内容会被外部篡改。
自动升级的频率
CoreOS会在 启动后10分钟 以及之后的 每隔1个小时 自动检测系统版本,如果检查到新版本就会自动下载下来放到备用分区上,然后依据之前的那个升级策略决定是否自动重启节点。OK,就这么简单。
具体的升级检测记录可以通过 journalctl -f -u update-engine 命令查看到。
手动触发升级
恩,下面这个命令是给升级强迫症用户准备滴。
命令非常简单:update_engine_client -update,如果提示 "Update failed" 则表示当前已经是最新版本(搞不懂CoreOS那班人为啥不弄个友好点的提示信息)。如果检测到有新版本的系统则会立即将其下载和部署到备用系统分区上。
$ update_engine_client -update
[0404/032058:INFO:update_engine_client.cc(245)] Initiating update check and install.
[0404/032058:INFO:update_engine_client.cc(250)] Waiting for update to complete.
LAST_CHECKED_TIME=1428117554
PROGRESS=0.000000
CURRENT_OP=UPDATE_STATUS_UPDATE_AVAILABLE
NEW_VERSION=0.0.0.0
... ...
CURRENT_OP=UPDATE_STATUS_FINALIZING
NEW_VERSION=0.0.0.0
NEW_SIZE=129636481
Broadcast message from locksmithd at 2015-04-04 03:22:56.556697323 +0000 UTC:
System reboot in 5 minutes!
LAST_CHECKED_TIME=1428117554
PROGRESS=0.000000
CURRENT_OP=UPDATE_STATUS_UPDATED_NEED_REBOOT
NEW_VERSION=0.0.0.0
NEW_SIZE=129636481
[0404/032258:INFO:update_engine_client.cc(193)] Update succeeded -- reboot needed.部署完成后,如果用户的升级策略不是 off,系统会发送消息给所有登录当前的用户:“5分钟后系统将重启”。当然,你自己也会在5分钟后被踢出SSH登录,等再次登录回来的时候,就会发现系统已经变成新的版本了。
更好的升级策略
在看到CoreOS的4种升级策略时候,不晓得读者有没发现一个问题。前3种策略都会让新的系统版本下载部署后马上重启服务器,如果这个时候恰好是系统访问的高峰期,即使重启过程中,服务会自动迁移到其他的节点继续运行,仍然可能会造成短暂的服务中断的情况。而第4种策略索性等待管理员用户来重启系统完成升级,又引入了额外的人工干预,如果重启不及时还会使得集群得不到必要的安全更新。
有没有办法既让服务器不要在服务高峰期重启,又不至于很长时间没有更新呢?CoreOS给出了一种推荐的解决方法。我将它称为第5种升级策略:基于定时检测的自动重启。
这种升级策略没有在内置的选项当中,我们需要做些额外的工作:
- 将升级策略设置成 off
- 增加一个服务用来检测备用分区是否已经部署新的系统版本,如果部署了就进行重启
- 增加一个定时器在集群的低峰时段触发执行上面那个服务
检测和重启服务
首先来看最关键的这个服务update-window.service,它会去执行放在 /opt/bin 目录下面的update-window.sh脚本文件。
[Unit]
Description=Reboot if an update has been downloaded
[Service]
ExecStart=/opt/bin/update-window.sh这个脚本首先使用 update_engine_client -status 检测了备份分区是否已经部署好了新版本的系统。如果发现新的版本已经部署好,就根据 Etcd 服务是否启动来选择通过 Locksmith 调度重启节点(先获取锁然后重启动)或延迟一个随机的时间后重启节点,这样做的目的是防止太多节点在同一个时间重启导致集群不稳定。
#!/bin/bash
# If etcd is active, this uses locksmith. Otherwise, it randomly delays.
delay=$(/usr/bin/expr $RANDOM % 3600 )
rebootflag='NEED_REBOOT'
if update_engine_client -status | grep $rebootflag; then
echo -n "etcd is "
if systemctl is-active etcd; then
echo "Update reboot with locksmithctl."
locksmithctl reboot
else
echo "Update reboot in $delay seconds."
sleep $delay
reboot
fi
fi定时触发服务
接下来添加定时器update-window.timer在集群访问的低峰时段触发前面那个服务,
[Unit]
Description=Reboot timer
[Timer]
OnCalendar=*-*-* 05,06:00,30:00这个定时器Unit文件的功能类似于一个crontab记录,只不过对于用了Systemd启动的系统比较推荐使用这样的方式。上面的配置表示每天早上的5:00, 5:30, 6:00 和 6:30。
写到 cloud-init 里
既然是每个节点都要有的东东,当然要放到cloud-init 配置里面。把上面的内容统统写进去,看起来就是这个样子的了:
#cloud-config
coreos:
update:
reboot-strategy: off
units:
- name: update-window.service
runtime: true
content: |
[Unit]
Description=Reboot if an update has been downloaded
[Service]
ExecStart=/opt/bin/update-window.sh
- name: update-window.timer
runtime: true
command: start
content: |
[Unit]
Description=Reboot timer
[Timer]
OnCalendar=*-*-* 05,06:00,30:00
write_files:
- path: /opt/bin/update-window.sh
permissions: 0755
owner: root
content: |
#!/bin/bash
# If etcd is active, this uses locksmith. Otherwise, it randomly delays.
delay=$(/usr/bin/expr $RANDOM % 3600 )
rebootflag='NEED_REBOOT'
if update_engine_client -status | grep $rebootflag; then
echo -n "etcd is "
if systemctl is-active etcd; then
echo "Update reboot with locksmithctl."
locksmithctl reboot
else
echo "Update reboot in $delay seconds."
sleep $delay
reboot
fi
fi
exit 0到这里,CoreOS升级相关的事儿已经侃得差不多了。不过总觉得还差点什么。
具有国内特色的CoreOS升级问题
在国内服务器用过CoreOS的用户大约都会发现一个比较忧伤的现象:好像CoreOS的自动升级没有生效捏?
相信不少用户大概已经猜到原因了吧。为了验证猜测,不妨做个手动升级试试。下面是我在国内的一个CoreOS集群上得到的结果:
$ update_engine_client -check_for_update
[0328/091247:INFO:update_engine_client.cc(245)] Initiating update check and install.
[0328/092033:WARNING:update_engine_client.cc(59)] Error getting dbus proxy for com.coreos.update1:
GError(3): Could not get owner of name 'com.coreos.update1': no such name
[0328/092033:INFO:update_engine_client.cc(50)] Retrying to get dbus proxy. Try 2/4
... ...
[0328/092053:INFO:update_engine_client.cc(50)] Retrying to get dbus proxy. Try 4/4
[0328/092103:WARNING:update_engine_client.cc(59)] Error getting dbus proxy for com.coreos.update1:
GError(3): Could not get owner of name 'com.coreos.update1': no such name
[0328/092103:ERROR:update_engine_client.cc(64)] Giving up -- unable to get dbus proxy for com.coreos.update1看到最后输出Giving up的时候,整个人都不好了。现在来说说怎么解决这个问题。
使用HTTP代理升级CoreOS
既然是访问不到升级服务器,解决办法就很干脆了:翻墙。
首先得找一个能用的墙外HTTP代理服务器,这个...大家各显神通吧,记录下找到的地址和端口,下面来配置通过代理升级服务器。
创建一个配置文件 /etc/systemd/system/update-engine.service.d/proxy.conf,内容为:
[Service]
Environment=ALL_PROXY=http://your.proxy.address:port将ALL_PROXY的值换成实际的代理服务器地址,重启一下update-engine服务即可:
sudo systemctl restart update-engine这个工作也可以在cloud-config里面用write_files命令在节点启动时候就完成:
#cloud-config
write_files:
- path: /etc/systemd/system/update-engine.service.d/proxy.conf
content: |
[Service]
Environment=ALL_PROXY=http://your.proxy.address:port
coreos:
units:
- name: update-engine.service
command: restart官方的服务器呢
其实一直有小道消息说,CoreOS公司已经在积极解决这个问题,预计2015年下半年会在国内架设专用的升级服务器。只能是期待一下了。
小结
“平滑而安全的滚动升级”和“无需干预的自动更新”既是CoreOS系统设计的初衷,也是一直是许多用户青睐CoreOS的原因。特别是在需要长期运行的服务器集群上,这些特性不仅节省了手工安装补丁和升级系统的成本,更避免了系统和核心软件升级不及时带来的安全性隐患。
希望这篇文章中介绍的内容能对大家理解CoreOS的系统升级相关问题提供一定参考和帮助。欢迎通过评论参与讨论。

 );){kind=link}