开放网络操作系统 ONOS Blackbird性能评估
| 2015-05-04 12:17
目标
ONOS是一个网络控制器。applications通过intent APIs与ONOS进行交互。ONOS通过其南向适配层控制数据网络的转发(例如,openflow网络)。ONOS控制层与数据转发层之间是ONOS流 子系统,ONOS流子系统是将application intens转换为openflow流规则的重要组成部分。ONOS也是一个分布式系统,至关重要的是ONOS分布式架构使其性能随着集群数量增加而提 高。这份评估报告将ONOS看作一个整体的集群系统,计划从应用和操作环境两个角度去评估ONOS性能。
我们设计了一系列的实验,测试在各种应用和网络环境下ONOS的延迟和吞吐量。并通过分析结果,我们希望提供给网络运营商和应用开发商第一手资料去了解ONOS的性能。此外,实验的结果将有助于开发人员发现性能瓶颈并优化。
下图把ONOS分布式系统作为一个整体,介绍了关键的测试点。
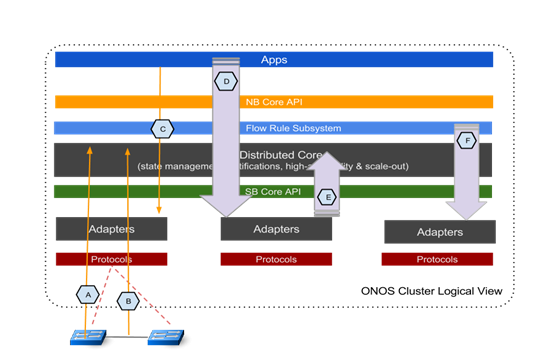
图中包括如下性能测试点:
延迟:
- A -交换机 连接/断开;
- B -link启用/断开;
- C -intent的批量安装/删除/路径切换;
吞吐量:
- D -intent操作;
- E -link事件(测试暂缓);
- F –迸发流规则安装。
通用实验设置
集群规模性能测试:
ONOS最突出的特点是其分布式架构。因此,ONOS性能测试的一个关键方面是比较和分析不同集群大小下ONOS的性能。所有的测试用例将以ONOS集群节点数量为1,3,5,7展开。
测试工具
为了展示ONOS的本质特征,使测试不受测试仪器的瓶颈限制,我们采用了一些比较实用的工具进行实验。所有实验,除了与Openflow协议交互的 交换机和端口及其它相关的,我们在ONOS的适配层部署了一套Null Providers与ONOS core进行交互。Null Providers担任着生成device,link,host以及大量的流规则的角色。通过使用Null Providers,我们可以避免并消除Openflow适配和使用真实设备或者模拟的Openflow设备所存在的潜在的性能瓶颈。
同时,我们也部署了一些负载生成器,这样可以使应用或者网络接口生成高强度的负载去触及ONOS的性能极限。
这些生成器包括:
1.Intent performance 生成器“onos-app-intent-perf”,它与intent API交互,生成intent安装/删除操作,并根据ONOS可承受的最高速度自我调节生成的Intent操作的负载。
2.流规则安装Python脚本工具与ONOS flow subsystem交互去安装和删除subsystem中的流规则。
3.Null LinkProvider中的link 事件(闪烁)生成器,可以迅速提升发送速度到ONOS所能承受的极限并依此速率发送link up/down信息给ONOS core。
4.此外,我们在"topology-events-metrics" 和"intents-events-metrics" 应用中利用计数器去获取关键事件的时间戳与处理速率来方便那些时间及速度相关的测试。
我们将在后续的每个不同的测试过程中详细介绍这些生成器的配置。
测试环境配置
A 7台 集群实验所需要的裸服务器。每个服务器的规格如下:
- 双Intel Xeon E5-2670v2处理器为2.5GHz - 10核心/20超线程内核
- 32GB1600MHz的DDR3 DRAM
- 1Gbps的网络接口卡
- Ubuntu的14.04 OS
- 集群之间使用ptpd同步
ONOS软件环境
- Java HotSpot(TM) (TM)64-Bit server VM; version 1.8.0_31
- JAVA_OPTS=“${JAVA_OPTS: - Xms8G-Xmx8G}”
- onos-1.1.0 snapshot:
- a31e13471ee626abce2bc43c413fab17586f4fc3
- 其他的具体与用例相关的ONOS参数将在具体的用例中进行说明
下面将具体介绍每个用例的细节配置,测试结果讨论及分析。
实验A&B - 拓扑(Switch,Link)发现时延测试
目标
本实验是测试ONOS控制器在不同规模的集群环境中是如何响应拓扑事件的,测试拓扑事件的类型包括:
1)交换机连接或断开ONOS节点
2)在现有拓扑中链路的up和down
ONOS作为一个分布式的系统架构,多节点集群相比于独立节点可能会发生额外的同步拓扑事件的延迟。除了限制独立模式下的延迟时间,也要减少由于onos集群间由于EW-wise通信事件产生额外延时。
配置和方法—交换机连接/断开的延迟
下面的图表说明了测试设置。一个交换机连接事件,是在一个“floating”(即没有交换机端口和链路)的OVS(OF1.3)上通过“set- controller”命令设置OVS桥连接到onos1控制器。我们在OF控制层面网络上使用tshark工具捕捉交换机上线的时间戳,ONOS Device和Graph使用“topology-event-metrics”应用记录时间戳。通过整理核对这些时间戳,我们得出从最初的事件触发到 ONOS在其拓扑中记录此事件的“端到端”的时序曲线。

所需得到的几个关键时间戳如下:
1.设备启动连接时间点t0,tcp syn/ ack;
2.OpenFlow协议的交换:
- t0 -> ONOS Features Reply;
- OVS Features Reply -> ONOS Role Request; (ONOS 在这里处理选择主备控制器);
- ONOS Role Request -> OVS Role Reply –OF协议的初始交换完成。
3.ONOS core处理事件的过程:
- OF协议交换完成后触发Device Event;
- 本地节点的Device Event触发Topology (Graph) Event。
同样的,测试交换机断开事件,我们使用ovs命令“del-controller”断开交换机与它连接的ONOS节点,捕获的时间戳如下:
1.OVS tcp syn/fin (t0);
2.OVS tcp fin;
3.ONOS Device Event;
4.ONOS Graph Event (t1).
交换机断开端到端的延迟为(T1 - T0)
当我们增大ONOS集群的大小,我们只连接和断开ONOS1上的交换机,并记录所有节点上的事件时间戳。集群的整体延迟是Graph Event报告中最迟的节点的延时时间。在我们的测试脚本中,我们一次测试运行多个迭代(例如,20次迭代)来收集统计结果。
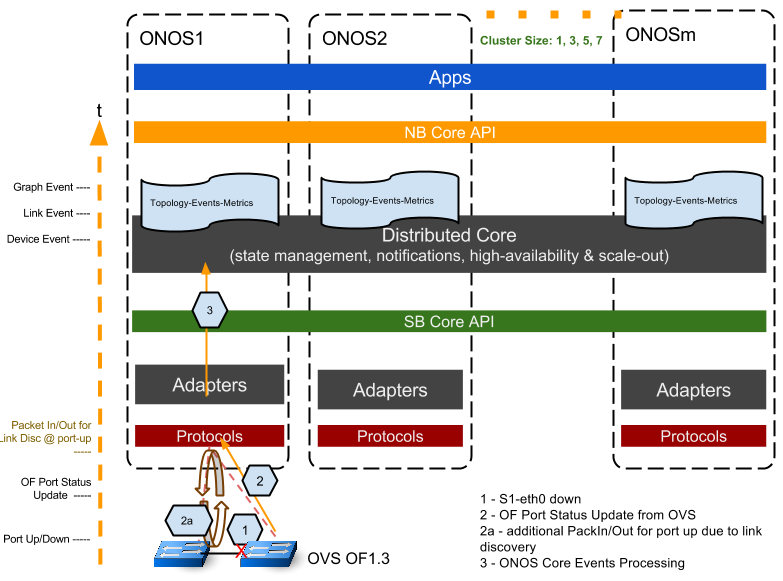
设置和方法—链路up/down的延迟
测试一条链接up / down事件的延迟,除了我们用两个OVS交换机创建链路(我们使用mininet创建一个简单的两个交换机的线性拓扑结构)外,我们使用了与交换机连接 测试的类似方法。这两个交换机的主控权属于ONOS1。参照下面的图表。初步建立交换机-控制器连接后,设置一个交换机的接口up或down,我们通过端 口up或down事件来触发此测试。
一些关键的时间戳记录,如下所述:
1. 交换机端口up/down, t0;
2. OVS向ONOS1发送OF PortStatus Update消息;
2a.在端口up的情况下,ONOS通过给每个OVS交换机发送链路发现消息来产生链路发现事件,同时ONOS收到其他交换机发送的Openflow PacketIn消息。
3.ONOS core处理事件过程:
由OF port status消息引起的Device事件; (ONOS处理)
链路down时,Link Event由Device Event触发在本地节点产生,链路up时,Link Event是在链路发现PacketIn/out完成后产生的;(主要时间都是在OFP消息和ONOS处理上)
本地节点生成Graph Event。(ONOS处理)
类似于交换机的连接测试,我们认为在Graph Event中登记的集群中最迟的节点的延时时间为集群的延迟。
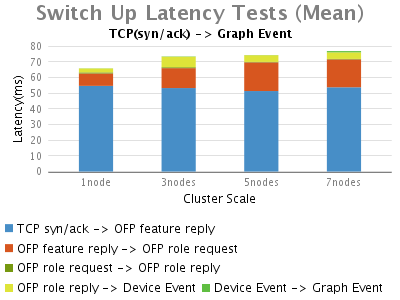
结果
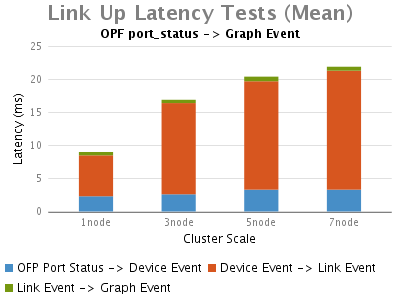
Switch-add Event:
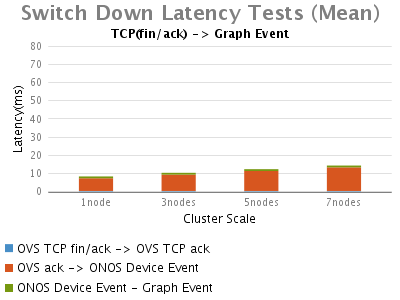
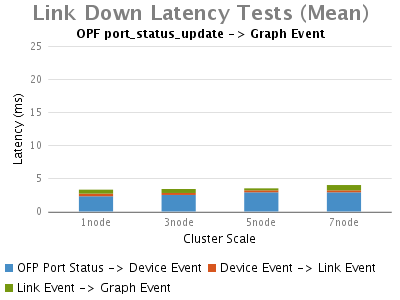
Link Up/Down Event:
分析和总结
Switch Connect/Disconnect Event:
当一个交换机连接到ONOS时,明显的时延划分为以下几个部分:
1.链路发现的中时延最长的部分,是从最初的tcp连接到ONOS收到Openflow features-replay消息。进一步分析数据包(在结果图中未示出),我们可以看到大部分时间是花在初始化控制器与交换机的OpenFlow握手 阶段,ONOS等待OVS交换机响应它的features_request。而这个时延很大程度上不是由ONOS的处理引起的。
2.其次是在"OFP feature reply -> OFP role request"部分,这部分时延也会随着ONOS集群规模增加而增加,其主要花费在ONOS给新上线的交换机选择主控权上,这是由于单节点的ONOS只 需在本地处理,而多节点的集群环境中,集群节点之间的通信将会带来这个额外的延时
3.接着便是从OpenFlow握手完成(OFP role reply)到ONOS登记一个Device Event的过程中消耗的时延。这部分的时延也受多节点ONOS配置影响,因为此事件需要ONOS将其写入Device Store。
4.最后一个延时比较长的是ONOS在本地处理来着Device store的Device event到向Graph中注册拓扑信息事件的部分。
断开交换机时,随着ONOS集群规模的增大ONOS触发Device事件的时延将略有增加。
总之,在OpenFlow消息交换期间,OVS对feature-request的响应时延占据了交换机建立连接事件中,整体时延的绝大部分。接 着,ONOS花费约9毫秒处理主控权选。最后,ONOS在多节点集群环境下,由于各节点之间需要通信选举主节点,交换机上/下线时延将都会增加。
Link Up/Down Events:
此次测试,我们首先观察到的是,链路up事件比链路down事件花费更长的时间。通过时延分析,我们可以看到OVS的端口up事件触发了ONOS特 殊的行为链路发现,因此,绝大多数时延主要由处理链路发现事件引起。与单节点的ONOS相比这部分时延受集群节点的影响也比较大。另外,大多数ONOS core花费在向Graph登记拓扑事件上的时延在个位数的ms级别。
在大部分的网络操作情况下,虽然整体拓扑事件的低延迟是可以被容忍的,但是交换机/链路断开事件却至关重要,因为它们被更多的看作是 applications的adverse events。当ONOS能更快速的检测到link down/up事件时,pplications也就能更快速的响应此adverse events,我们测试的此版本的ONOS具有在个位数ms级发现switch/link down事件的能力。
实验C :intent install/remove/re-route延迟测试
目的
这组测试旨在得到ONOS当一个application安装,退出多种批大小的intents时的延迟特性(即响应时间)。
同时也得到ONOS路径切换事件的延时特性,即最短路径不可用,已安装的intent由于路径改变而需要重路由时所花费的时延。这是一个ONOS的 全方位系统测试,从ONOS的 NB API 经过intent 和flow subsystem 到ONOS的 SB API;采用Null Provider代替Openflow Adaptor进行测试。
这组测试结果将向网络运营商和应用开发者提供当operating intents时applications所期望的响应时间以及intents批的大小和集群数量的大小对时延的影响的第一手资料。
配置和方法—batch intent安装与退出
参考下图,我们用ONOS内置的app“push-test-intent”从ONOS1并通过ONOS1的intent API推进一个批的点对点intents。“push-test-intent”工具构造一系列的基于终点的,批大小和application id的intents。然后通过intent API 发送这些intents请求。当成功安装所有的intents时,返回延迟(响应时间)。随后退出这些intents并返回一个退出响应时间。当 intents请求被发送时,ONOS内部转换intents到流规则并写入相应的分布式存储来分发intents和流表。
参考下图,特别是我们的实验中,intents被构建在一个端到端的7个线性配置的交换机上,也就是说所有intents的入口是从S1的一个端口 和它们的出口是S7的一个端口。(我们使用在拓扑中额外的交换机S8进行intent re-route测试,这个测试后续描述)。我们通过Null Providers来构建交换机(Null Devices),拓扑(Null Links)和流量(Null Flows)。
当增大集群节点数量时,我们重新平均分配switch的主控权到各个集群节点。
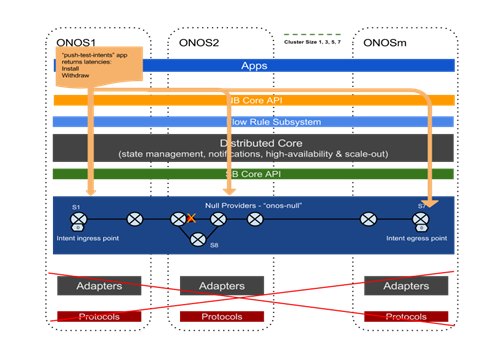
在这个实验中,我们将使用如下指标来衡量ONOS性能:
- 所有安装的intents是6hops点到点intents;
- Intent批的大小:1,10,100,1000,5000 intents;
- 测试次数:每个用例重复测试20次(4次预测试之后统计);
- 集群规模大小从1到3,5,7个节点。
配置和方法--intent Re-route
同样参照上图,intent re-route延迟是一个测试ONOS在最短路径不可用的情况下,重新安装所有intents到新路径的速度。
测试顺序如下:
1.我们通过“push-test-intents -i”选项预安装不会自动退出的intents在线性最短路径上。然后我们通过修改Null Provider 链路定义文件模拟最短路径的故障。当新拓扑被ONOS发现时,我们通过检查ONOS 日志获取触发事件的初始时间戳t0;
2.由于 6-hop最短路径已不可用。ONOS切换到通过S8的7-hop备份路径。Intent和流系统响应该事件,退出旧intents并删除旧流表(因为ONOS当前实现,所有intents和流已不可重新使用)。
3.接下来,ONOS重新编译intents和流,并安装。在验证所有intents确实被成功安装后,我们从“Intents-events-metrics”捕获最后的intent安装时间戳(t1)。
4.我们把(t1-t0)作为ONOS 重路由intent(s)的延迟。
5.测试脚本迭代的几个参数:
a. Intent初始安装的批大小:1,10,100,1000和5000 intents;
b.每个测试结果统计的是运行20次的结果平均值(4个预测试之后开始统计);
c. ONOS集群规模从1,到3,5,7节点。
结果
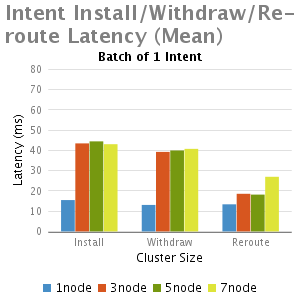
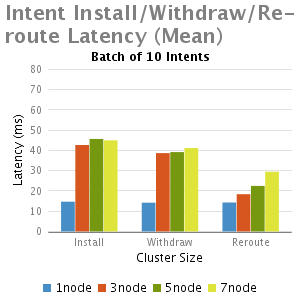
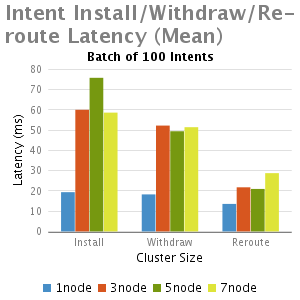
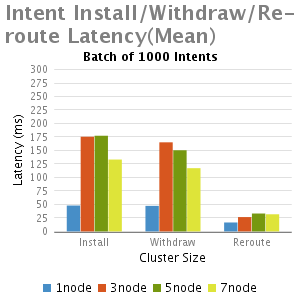
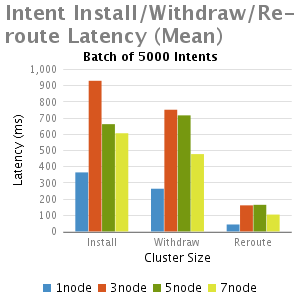
分析和总结
我们从这个实验中得出结论:
1.正如预期,与单节点的ONOS相比,多个节点的ONOS集群由于EW-wise通信的需要延迟比较大
2.小批intents(1-100),不计批大小时,其主要的延时是一个固定的处理时延,因此当批大小增大,每一个intent安装时间减少,这就是时延大批的优点。
3.批大小非常大的情况下(如5000),随着集群大小增加(从3到7),延迟减少,其主要是由于每个节点处理较小数量的intents;
4.Re-routeing延时比初始化安装和退出的延迟都小。
实验D:Intents Operation吞吐量
目标
本项测试的目的是衡量ONOS处理intents operations 请求的能力。SDN控制器其中一个重要用例就是允许agile applications通过intents和流规则频繁更改网络配置。作为一款SDN控制器,ONOS应该具有高水平的intents安装和撤销处理能 力。ONOS使用的分布式架构, 随着集群规模的增加,理应能够维持较高的intent operation吞吐量。
设置和方法
下图描述了测试方法:

本测试使用工具"intent-perf"来产生大量的Intents operation请求。这个intent-perf工具可以在ONOS集群环境中的任何一个节点激活并使用。这个工具在使用过程中有个三个参数需要配置:
- numKeys – 唯一的intents数量, 默认 40,000;
- cyclePeriod – intents安装和撤销的周期(时间间隔),默认 1000ms;
- numNeighbors –程序运行时,发送到各个集群节点的方式。0表示本节点;-1表示所有的集群节点
当intent-perf在ONOS节点运行时,以恒定的速率产生大量的、ONOS系统可以支持的intents安装撤销请求。在ONOS 日志中或 cli request中,会周期性的给出总体的intents处理吞吐量。持续运行一段时间后,我们可以观察到在集群的某个或某些节点总体吞吐量达到了饱和状 态。总体吞吐量需要包含intents安装撤销操作。统计所有运行intent-perf这个工具的ONOS节点上的吞吐量并求和,从而得到ONOS集群 的总体吞吐量。
intent-perf只产生"1-hop" 的intents,即这些intents被编译而成的流表的出口和入口都是在同一个交换机上,所以Null providers模块不需要生成一个健全的拓扑结构。
特别是本实验中,我们使用两个相邻的场景。首先,设置numNeighbors = 0,这种场景下,intent-perf只需要为本地的ONOS节点产生的intents安装和撤销请求,从而把intents的东西向接口通信降至最 低;其次,设置numNeighbors 为-1后,intent-perf生成器产生的intents安装和撤销请求需要分发到所有的ONOS集群节点,这样会把东西向接口的通信量最大化。本次 测试持续进行了300秒的负载测试,统计集群的总体吞吐量。其他的参数使用默认值。
结果
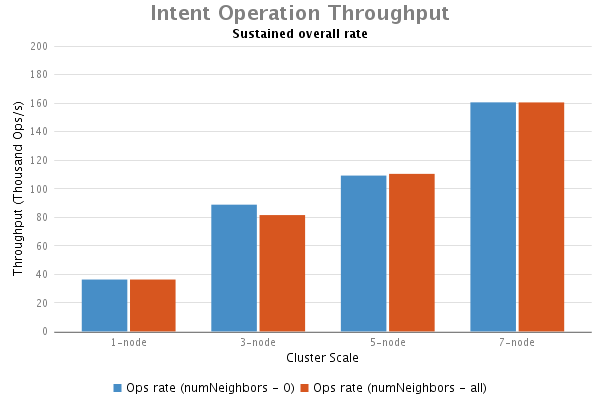
分析和结论
通过本次实验得出结论如下:
1.我们看到在ONOS的intents operations测试中一个明显趋势:总体吞吐量随着集群节点的增加而增加;
2.在流表子系统测试中集群的场景对吞吐量的影响微乎其微。
实验F:Flow子系统迸发吞吐量测试
目的
如前面所提到的,流子系统是onos的一个组成部分,其作用是将Intents转换成可以安装到openflow交换机上的流规则。另外,应用程序 可以直接调用其北向api来注入流规则。使用北向api和intent框架是此次性能评估的关键。另外,此次实验不但给我们暴漏了端到端Intent performance的性能缺陷,而且展示了当直接与流规则子系统交互时对应用的要求。
配置及方法
为了产生一批将被onos安装删除的流规则,我们使用脚本“flow-tester.py”。实际上这些脚本是onos工具执行的一部分。具体位置 在($ONOS_ROOT/tools/test/bin)目录下。执行这个脚本将触发onos安装一套流规则到所控制的交换机设备,当所有流规则安装成 功之后将会返回一个时延时间。这个脚本也会根据接收的一系列的参数去决定这个测试怎么运行。这些参数如下:
- 每个交换机所安装的流规则的数量
- 邻居的数量-由于交换机的连接的控制器并非本地的onos节点,需要onos本地节点同步流规则到(除了运行脚本的onos本地节点之外的)onos节点
- 服务的数量-运行onos脚本的节点数量,即产生流规则的onos节点数量
下图简要的描述了测试的配置:
从下图可以看出,onos1,onos2是运行onos脚本产生流规则的两个服务器;当两个流生成服务器生成流给两个邻居,也就是所生成的流规则被传递到两个与之相邻的节点安装。(因为这个流规则属于被邻居节点控制器的交换机)。

我们使用了Null Provider作为流规则的消费者,绕过了使用Openflow适配器和真实的或者模拟的交换机存在的潜在的性能限制。
具体实验参数设置
- Null Devices的数量保持常量35不变,然后被平均的分配到集群中的所有节点,例如,当运行的集群中有5个节点,每个节点将控制7个Null Devices;
- 集群一共安装122500条流规则-选择这个值其一是因为它足够大,其二,它很容易平均分配到测试中所使用的集群节点。这也是工具“flow-tester.py”计算每个交换机所安装的流规则数量的一个依据。
- 我们测试了2个关联场景:1)邻居数量为0,即所有的流规则都安装在产生流的服务器上场景;2)邻居数量为-1,即每个节点给自己以及集群中的其它节点产生流规则
- 测试集群规模1,3,5,7
- 响应时间为4次预测试之后20次的的测试时间统计整合得出
备注:版本发布的时候,ONOS核心仍然采用Hazelcast作为存储协议来备份流规则。
实验表明,使用Hazelcast协议作为备份,可能导致流规则安装速率频繁迸发增长。
在这一系列实验中,我们通过修改发布版本如下路径的代码关闭了流规则备份。($ONOS_ROOT/core/store/dist/src /main/java/org/onosproject/store/flow/impl /DistributedFlowRuleStore.java)
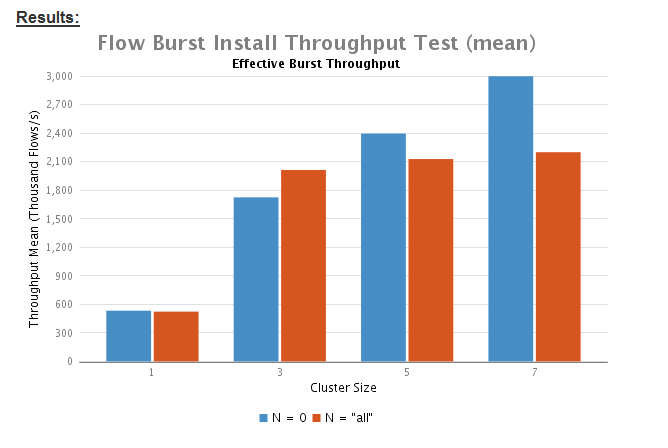
分析与结论
通过测试,可以得出如下系统性能测试结论:
1.根据测试数据显示,当配置N=0时,与配置N=“all”相比,系统有更高的吞吐量。也就是说当生成的流规则只安装给本地ONOS节点控制器的 设备时,流子系统的性能比安装给所有ONOS节点控制的设备时高。因为,ONOS节点之间的EW-wise通信存在开销/瓶颈。即,当配置N=“all” 时,性能低,符合预期值。
2.总的来说,这两种情况下通过增大集群节点数量测试,吞吐量随着集群数量的增加有明显的提高。但是这种提高是非线性的。例如,N=“all”与N=“0”相比,当节点间需要通信同步时,平稳增加的性能趋于平缓。
3.设置N=“all”与N=“0”获得的类似的性能数据说明,EW-wise通信没有成为ONOS intent operation性能的瓶颈。

 );){kind=link}