Apache Drill 1.0发布
作者:
@刘江总编
| 2015-05-21 14:53

虽然大数据往往将关系型数据库当作靶子,但事实上真正生产环境的Hadoop和Spark等大数据平台,每天大部分工作仍然是为SQL查询提供服务,所以,SQL on Hadoop就成了竞争最激烈的技术领域。
5月19日,Apache基金会宣布针对Hadoop、NoSQL(MongoDB和HBase)和云存储(Amazon S3, Google Cloud Storage, Azure Blog Storage, Swift)的无模式SQL查询引擎Drill 1.0发布。
项目的PMC成员Tomer Shiran说:
这是许多公司数十名工程师将近三年开发的成果。Apache Drill的灵活性和易用性已经吸引了数千维护,而1.0版的企业级可靠性、安全与性能将进一步加速采用。
发布声明中列出的相对于0.9的重要改进包括:
- Substantial improvements in stability, memory handling and performance
- Improvements in Drill CLI experience with addition of convenience shortcuts and improved colors/alignment
- Substantial additions to documentation including coverage of troubleshooting, performance tuning and many additions to the SQL reference
- Enhancements in join planning to facilitate high speed planning of large and complicated joins
- Add support for new context functions including CURRENTUSER and CURRENTSCHEMA
- Ability to treat all numbers as approximate decimals when reading JSON
- Enhancements in Drill's text and CSV handling to support first row skipping, configurable field/line delimiters and configurable quoting
- Improved JDBC compatibility (and tracing proxy for easy debugging).
- Ability to do JDBC connections with direct urls (avoiding ZooKeeper)
- Automatic selection of spooling or back-pressure exchange semantics to avoid distributed deadlocks in complex sort-heavy queries
- Improvements in query profile reporting
- Addition of ILIKE(VARCHAR, PATTERN) and SUBSTR(VARCHAR, REGEX) functions
更多详情可以参考官方网站:http://drill.apache.org
Drill实际上是MapR在主导的,项目负责人和核心开发者大多来自MapR。它实际上是众多SQL on Hadoop中的一个,此外还包括:
- Hadoop上原生的Hive
- Hortonworks主导的Hive演进项目Stinger
- Cloudera主导的Impala
- MapR主导的Apache Drill
- Facebook的Presto
- Pivotal的Greenplum
- Salesforce最初开发的Apache Phoenix
- 出自韩国的Apache Tajo(Google Tenzing的模仿)
- Spark社区的Spark SQL
- Splice Machine
从逻辑上来说,除了Spark SQL会借助Spark的火势取得一定优势外,其余最值得关注的还是Hadoop三巨头分别支持的Impala、Stinger和Drill。Impala和Drill都是在Google Dremel启发下产生的,之前好像Impala势头较猛,但现在Drill有迎头赶上的意思。
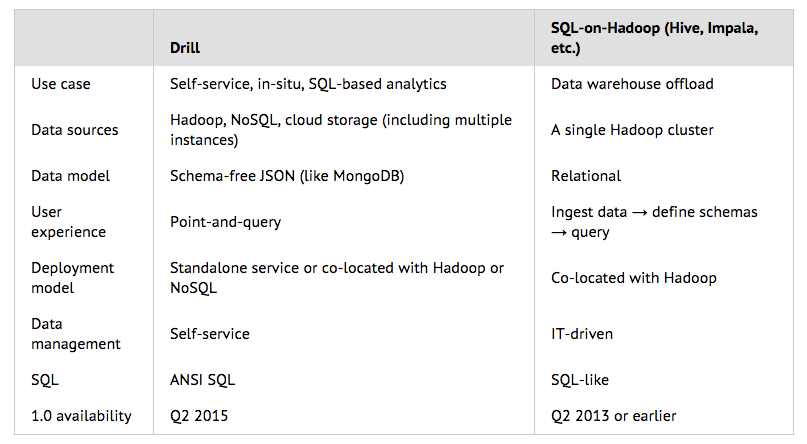
Drill这次正式发布,在FAQ里专门做了比较:

 );){kind=link}