写一个每秒接收 100 万数据包的程序究竟有多难?
| 2015-06-30 08:23 评论: 2 收藏: 3
在上周的一次非正式谈话中,我偶然听同事说:“Linux 的网络栈太慢了!你别指望每秒在每个核上传输超过 5 万的数据包”。
这让我陷入了沉思,虽然对于任意的实际应用来说,每个核 5 万的速率可能是极限了,但 Linux 的网络栈究竟可能达到多少呢?我们换一种更有趣的方式来问:
在 Linux 上,编写一个每秒接收 100 万 UDP 数据包的程序究竟有多难?
我希望,通过对这个问题的解答,我们将获得关于如何设计现代网络栈很好的一课。

首先,我们假设:
- 测量每秒的数据包(pps)比测量每秒字节数(Bps)更有意思。您可以通过更好的管道输送以及发送更长数据包来获取更高的Bps。而相比之下,提高pps要困难得多。
- 因为我们对pps感兴趣,我们的实验将使用较短的 UDP 消息。准确来说是 32 字节的 UDP 负载,这相当于以太网层的 74 字节。
- 在实验中,我们将使用两个物理服务器:“接收器”和“发送器”。
- 它们都有两个六核2 GHz的 Xeon处理器。每个服务器都启用了 24 个处理器的超线程(HT),有 Solarflare 的 10G 多队列网卡,有 11 个接收队列配置。稍后将详细介绍。
- 测试程序的源代码分别是:udpsender、udpreceiver。
预备知识
我们使用4321作为UDP数据包的端口,在开始之前,我们必须确保传输不会被iptables干扰:
receiver$ iptables -I INPUT 1 -p udp --dport 4321 -j ACCEPT
receiver$ iptables -t raw -I PREROUTING 1 -p udp --dport 4321 -j NOTRACK为了后面测试方便,我们显式地定义IP地址:
receiver$ for i in `seq 1 20`; do \
ip addr add 192.168.254.$i/24 dev eth2; \
done
sender$ ip addr add 192.168.254.30/24 dev eth3 1. 简单的方法
开始我们做一些最简单的试验。通过简单地发送和接收,有多少包将会被传送?
模拟发送者的伪代码:
fd = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
fd.bind(("0.0.0.0", 65400)) # select source port to reduce nondeterminism
fd.connect(("192.168.254.1", 4321))
while True:
fd.sendmmsg(["\x00" * 32] * 1024)因为我们使用了常见的系统调用的send,所以效率不会很高。上下文切换到内核代价很高所以最好避免它。幸运地是,最近Linux加入了一个方便的系统调用叫sendmmsg。它允许我们在一次调用时,发送很多的数据包。那我们就一次发1024个数据包。
模拟接受者的伪代码:
fd = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
fd.bind(("0.0.0.0", 4321))
while True:
packets = [None] * 1024
fd.recvmmsg(packets, MSG_WAITFORONE)同样地,recvmmsg 也是相对于常见的 recv 更有效的一版系统调用。
让我们试试吧:
sender$ ./udpsender 192.168.254.1:4321
receiver$ ./udpreceiver1 0.0.0.0:4321
0.352M pps 10.730MiB / 90.010Mb
0.284M pps 8.655MiB / 72.603Mb
0.262M pps 7.991MiB / 67.033Mb
0.199M pps 6.081MiB / 51.013Mb
0.195M pps 5.956MiB / 49.966Mb
0.199M pps 6.060MiB / 50.836Mb
0.200M pps 6.097MiB / 51.147Mb
0.197M pps 6.021MiB / 50.509Mb测试发现,运用最简单的方式可以实现 197k – 350k pps。看起来还不错嘛,但不幸的是,很不稳定啊,这是因为内核在核之间交换我们的程序,那我们把进程附在 CPU 上将会有所帮助。
sender$ taskset -c 1 ./udpsender 192.168.254.1:4321
receiver$ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.362M pps 11.058MiB / 92.760Mb
0.374M pps 11.411MiB / 95.723Mb
0.369M pps 11.252MiB / 94.389Mb
0.370M pps 11.289MiB / 94.696Mb
0.365M pps 11.152MiB / 93.552Mb
0.360M pps 10.971MiB / 92.033Mb现在内核调度器将进程运行在特定的CPU上,这提高了处理器缓存,使数据更加一致,这就是我们想要的啊!
2. 发送更多的数据包
虽然 370k pps 对于简单的程序来说已经很不错了,但是离我们 1Mpps 的目标还有些距离。为了接收更多,首先我们必须发送更多的包。那我们用独立的两个线程发送,如何呢:
sender$ taskset -c 1,2 ./udpsender \
192.168.254.1:4321 192.168.254.1:4321
receiver$ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.349M pps 10.651MiB / 89.343Mb
0.354M pps 10.815MiB / 90.724Mb
0.354M pps 10.806MiB / 90.646Mb
0.354M pps 10.811MiB / 90.690Mb接收一端的数据没有增加,ethtool –S 命令将显示数据包实际上都去哪儿了:
receiver$ watch 'sudo ethtool -S eth2 |grep rx'
rx_nodesc_drop_cnt: 451.3k/s
rx-0.rx_packets: 8.0/s
rx-1.rx_packets: 0.0/s
rx-2.rx_packets: 0.0/s
rx-3.rx_packets: 0.5/s
rx-4.rx_packets: 355.2k/s
rx-5.rx_packets: 0.0/s
rx-6.rx_packets: 0.0/s
rx-7.rx_packets: 0.5/s
rx-8.rx_packets: 0.0/s
rx-9.rx_packets: 0.0/s
rx-10.rx_packets: 0.0/s通过这些统计,NIC 显示 4 号 RX 队列已经成功地传输大约 350Kpps。rx_nodesc_drop_cnt 是 Solarflare 特有的计数器,表明NIC发送到内核未能实现发送 450kpps。
有时候,这些数据包没有被发送的原因不是很清晰,然而在我们这种情境下却很清楚:4号RX队列发送数据包到4号CPU,然而4号CPU已经忙不过来了,因为它最忙也只能读350kpps。在htop中显示为:
多队列 NIC 速成课程
从历史上看,网卡拥有单个RX队列,用于硬件和内核之间传递数据包。这样的设计有一个明显的限制,就是不可能比单个CPU处理更多的数据包。
为了利用多核系统,NIC开始支持多个RX队列。这种设计很简单:每个RX队列被附到分开的CPU上,因此,把包送到所有的RX队列网卡可以利用所有的CPU。但是又产生了另一个问题:对于一个数据包,NIC怎么决定把它发送到哪一个RX队列?
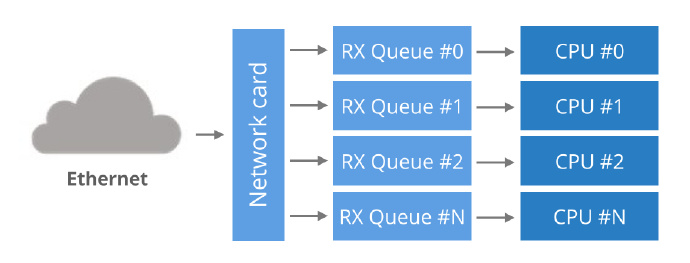
用 Round-robin 的方式来平衡是不能接受的,因为这有可能导致单个连接中数据包的重排序。另一种方法是使用数据包的hash值来决定RX号码。Hash值通常由一个元组(源IP,目标IP,源port,目标port)计算而来。这确保了从一个流产生的包将最终在完全相同的RX队列,并且不可能在一个流中重排包。
在我们的例子中,hash值可能是这样的:
RX_queue_number = hash('192.168.254.30', '192.168.254.1', 65400, 4321) % number_of_queues 多队列 hash 算法
Hash算法通过ethtool配置,设置如下:
receiver$ ethtool -n eth2 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA 对于IPv4 UDP数据包,NIC将hash(源 IP,目标 IP)地址。即
RX_queue_number = hash('192.168.254.30', '192.168.254.1') % number_of_queues 这是相当有限的,因为它忽略了端口号。很多NIC允许自定义hash。再一次,使用ethtool我们可以选择元组(源 IP、目标 IP、源port、目标port)生成hash值。
receiver$ ethtool -N eth2 rx-flow-hash udp4 sdfn
Cannot change RX network flow hashing options: Operation not supported 不幸地是,我们的NIC不支持自定义,我们只能选用(源 IP、目的 IP) 生成hash。
NUMA性能报告
到目前为止,我们所有的数据包都流向一个RX队列,并且一个CPU。我们可以借这个机会为基准来衡量不同CPU的性能。在我们设置为接收方的主机上有两个单独的处理器,每一个都是一个不同的NUMA节点。
在我们设置中,可以将单线程接收者依附到四个CPU中的一个,四个选项如下:
- 另一个CPU上运行接收器,但将相同的NUMA节点作为RX队列。性能如上面我们看到的,大约是360 kpps。
- 将运行接收器的同一 CPU 作为RX队列,我们可以得到大约430 kpps。但这样也会有很高的不稳定性,如果NIC被数据包所淹没,性能将下降到零。
- 当接收器运行在HT对应的处理RX队列的CPU之上,性能是通常的一半,大约在200kpps左右。
- 接收器在一个不同的NUMA节点而不是RX队列的CPU上,性能大约是330 kpps。但是数字会不太一致。
虽然运行在一个不同的NUMA节点上有10%的代价,听起来可能不算太坏,但随着规模的变大,问题只会变得更糟。在一些测试中,每个核只能发出250 kpps,在所有跨NUMA测试中,这种不稳定是很糟糕。跨NUMA节点的性能损失,在更高的吞吐量上更明显。在一次测试时,发现在一个坏掉的NUMA节点上运行接收器,性能下降有4倍。
3.多接收IP
因为我们NIC上hash算法的限制,通过RX队列分配数据包的唯一方法是利用多个IP地址。下面是如何将数据包发到不同的目的IP:
sender$ taskset -c 1,2 ./udpsender 192.168.254.1:4321 192.168.254.2:4321ethtool 证实了数据包流向了不同的 RX 队列:
receiver$ watch 'sudo ethtool -S eth2 |grep rx'
rx-0.rx_packets: 8.0/s
rx-1.rx_packets: 0.0/s
rx-2.rx_packets: 0.0/s
rx-3.rx_packets: 355.2k/s
rx-4.rx_packets: 0.5/s
rx-5.rx_packets: 297.0k/s
rx-6.rx_packets: 0.0/s
rx-7.rx_packets: 0.5/s
rx-8.rx_packets: 0.0/s
rx-9.rx_packets: 0.0/s
rx-10.rx_packets: 0.0/s接收部分:
receiver$ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.609M pps 18.599MiB / 156.019Mb
0.657M pps 20.039MiB / 168.102Mb
0.649M pps 19.803MiB / 166.120Mb万岁!有两个核忙于处理RX队列,第三运行应用程序时,可以达到大约650 kpps !
我们可以通过发送数据到三或四个RX队列来增加这个数值,但是很快这个应用就会有另一个瓶颈。这一次rx_nodesc_drop_cnt没有增加,但是netstat接收到了如下错误:
receiver$ watch 'netstat -s --udp'
Udp:
437.0k/s packets received
0.0/s packets to unknown port received.
386.9k/s packet receive errors
0.0/s packets sent
RcvbufErrors: 123.8k/s
SndbufErrors: 0
InCsumErrors: 0这意味着虽然NIC能够将数据包发送到内核,但是内核不能将数据包发给应用程序。在我们的case中,只能提供440 kpps,其余的390 kpps + 123 kpps的下降是由于应用程序接收它们不够快。
4.多线程接收
我们需要扩展接收者应用程序。最简单的方式是利用多线程接收,但是不管用:
sender$ taskset -c 1,2 ./udpsender 192.168.254.1:4321 192.168.254.2:4321
receiver$ taskset -c 1,2 ./udpreceiver1 0.0.0.0:4321 2
0.495M pps 15.108MiB / 126.733Mb
0.480M pps 14.636MiB / 122.775Mb
0.461M pps 14.071MiB / 118.038Mb
0.486M pps 14.820MiB / 124.322Mb接收性能较于单个线程下降了,这是由UDP接收缓冲区那边的锁竞争导致的。由于两个线程使用相同的套接字描述符,它们花费过多的时间在UDP接收缓冲区的锁竞争。这篇论文详细描述了这一问题。
看来使用多线程从一个描述符接收,并不是最优方案。
5. SO_REUSEPORT
幸运地是,最近有一个解决方案添加到 Linux 了 —— SO_REUSEPORT 标志位(flag)。当这个标志位设置在一个套接字描述符上时,Linux将允许许多进程绑定到相同的端口,事实上,任何数量的进程将允许绑定上去,负载也会均衡分布。
有了SO_REUSEPORT,每一个进程都有一个独立的socket描述符。因此每一个都会拥有一个专用的UDP接收缓冲区。这样就避免了以前遇到的竞争问题:
eceiver$ taskset -c 1,2,3,4 ./udpreceiver1 0.0.0.0:4321 4 1
1.114M pps 34.007MiB / 285.271Mb
1.147M pps 34.990MiB / 293.518Mb
1.126M pps 34.374MiB / 288.354Mb现在更加喜欢了,吞吐量很不错嘛!
更多的调查显示还有进一步改进的空间。即使我们开始4个接收线程,负载也会不均匀地分布:

两个进程接收了所有的工作,而另外两个根本没有数据包。这是因为hash冲突,但是这次是在SO_REUSEPORT层。
结束语
我做了一些进一步的测试,完全一致的RX队列,接收线程在单个NUMA节点可以达到1.4Mpps。在不同的NUMA节点上运行接收者会导致这个数字做多下降到1Mpps。
总之,如果你想要一个完美的性能,你需要做下面这些:
- 确保流量均匀分布在许多RX队列和SO_REUSEPORT进程上。在实践中,只要有大量的连接(或流动),负载通常是分布式的。
- 需要有足够的CPU容量去从内核上获取数据包。
- To make the things harder, both RX queues and receiver processes should be on a single NUMA node.
- 为了使事情更加稳定,RX队列和接收进程都应该在单个NUMA节点上。
虽然我们已经表明,在一台Linux机器上接收1Mpps在技术上是可行的,但是应用程序将不会对收到的数据包做任何实际处理——甚至连看都不看内容的流量。别太指望这样的性能,因为对于任何实际应用并没有太大用处。

 );){kind=link}