Quora 是如何维持高质量代码的
| 2015-08-01 08:35 收藏: 1
一个高质量的代码库可以加快长期开发的速度,因为它会使得迭代、协作和维护更加容易。在Quora,我们十分重视代码库的质量。
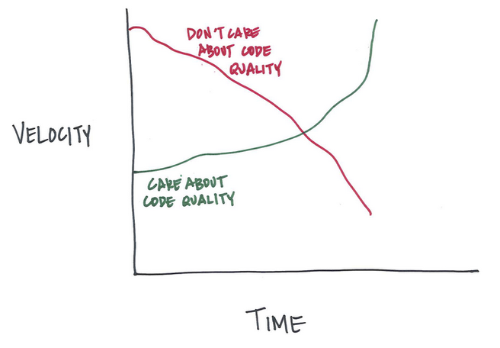
除了会取得收益之外,要维护高质量的代码,会带来一大笔间接费用,还会牺牲实际开发周期。很多人发现,实际产生的收益很难抵消这一间接费用,这时人们会面临两个选择:要么以低质量代码提升开发速度,要么维护高质量代码而牺牲开发速度。而对于初创公司来说,他们希望开发速度能快一些,所以就不得不使用低质量的代码。
我们开发了一系列工具和流程,这样就可以在维护高质量代码库的同时,提升开发的速度。在这篇文章中,我们将会介绍关于保证代码质量的一些方法,以及一些平衡这两方面的具体案例。
维护高质量代码的目标
维护高质量代码主要的好处在于能够长期推动开发速度,这也是我们所关注的重点。通过编写清晰代码而产生的短期成本,就可以换来长期的收益。
记住这一点,然后下面是四点基本原则,我们发现对代码质量非常有帮助:
Quara的代码质量基本原则
1. 代码的阅读和理解都要很容易——现在的情况是更多的时间用在了代码的阅读上,而不是代码的编写上。实际上,应该把阅读的时间减少,即便这样意味着需要花费更多的时间来写代码。
2. 代码的不同部分需要有不同的质量标准——不同的代码行需要有不同的使用时间、范围、被破坏的风险、被破坏后造成的成本及其修复的成本,等等。总体来讲,这些对长期迭代速度的影响不同,所以执行一个统一的质量标准是不合理的。
3. 代码质量的间接费用是可以缩减的——维护高质量成本的间接费用一般是可以节省的,这可以通过使用自动化、更好的工具、更好的流程和培训更优质的开发人员来实现。
4. 代码库一致性很重要——保持整个代码库的一致性是十分有价值的,即便这意味着有一部分代码不能是最优的。一个不一致的代码库是很难阅读和理解的(见第一点),也很难编写,很难通过自动化工具进行优化。
下面,我来介绍几个我们将这几点原则用于实际开发的例子。
提交后code review
我们代码库的代码变更需要从六个维度进行评估——正确性、隐私、性能、架构、复用性和风格。读代码是code review的关键部分,所以说,code review在提升代码可读性方面起着至关重要的作用。
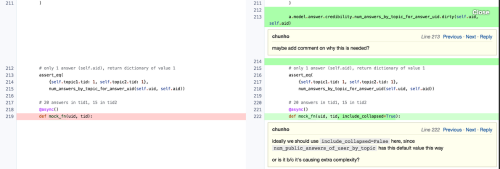
但是有一点不好的是,code review同样会减缓开发速度。比如说,提交前code review在行业中目前是比较常见的,其中代码必须在推送之前就进行审查和修改。这样的话,即使是每一轮审查只需要2天的时间,这样重复2-3轮,也会耽误开发人员一周的时间,这是严重的时间浪费。
在Quora,我们主要做的是提交后code review。也就是说,代码首先进入生产阶段,然后再找人进行code review。为了让你对这一工作的规模有个认识,举个例子,昨天我们48个人总共推送了187次代码。提交后review是很好的办法,因为它解放了开发人员,可以去做其他的工作。code review人员也可以更好的管理自己的时间,可以在他们方便的时候做代码审查,而不是非得匆忙的完成这一工作,以便不影响其他人的工作。过程合理的话,预计代码审查一周内可以完成,而实际上大部分情况下,一到两天就可以完成。之所以说一周的时间,也是经过仔细考虑的,因为一周足够长,可以允许审查人员灵活安排,而一周的时间又有点短,因为它需要将不好结果的影响最小化,比如说有人读了代码之后将不好的代码在整个代码库中进行传播。实际还有这样一层原因,很多的开发人员都是按周进行个人工作安排的。
我们之所以可以做提交后code review,是因为我们相信我们的每一位开发人员,我们选择的都是最优秀的人才,并且我们在他们的代码质量培训/工具方面投入了大量资金。这也督促我们对代码进行更好的测试,而好的测试能帮助检测代码的准确性,甚至在任何code review工作开始之前就可以检测。对此,我们采用的是Phabricator,一个稳健的、高配置的审查工具。我们对它做了几点改进,这样就能与我们的提交后code review工作流更好的配合。比如说,我们构建了一个命令行工具,可以将代码推向生产阶段,并提出代码审查请求。有了该工具,Phabricator的diff就可以继续工作,而无需去修复那些commits。
所有这些说明,对于不同类型的代码问题,我们有不同的代码审查标准。如果说我们事先发现了某一个潜在错误,问题比较大,可能会带来很大影响,那么我们会转而执行提交前审查,而不是平常的提交后审查。这方面的几个例子:
- 涉及用户隐私和匿名的代码。
- 涉及核心的抽象类(abstraction),因为很多其他的代码都可能依赖于它。
- 涉及基础设施的某些部分,其有些错误可能会导致宕机的风险。
当然这还取决于开发人员如何决策——如果他们想要对某些代码进行提交前审查,从而从中获取更多想法,这也是可以的,而不用非得采用平常的提交后code review,只不过这种情况比较少见。
code review任务分派
为了做好code review,每一个变更都应该由有着相关经验的人员来审查。如果这些code review人员能负责“维护”这些他们审查过的代码的话那就更好了,这样他们可以获得一定物质报酬,进而形成长期的交易关系。
我们之前实施了一个简单的系统,其模块和目录层级代码的“所有权”只需要在文件开头赋予一个元标签(meta tag)就可以指定了。比如:
__reviewer__ = 'vanessa, kornel'如果某commit要对文件做一些修改,其reviewer就会根据文件(或结构树【ancestor tree】),进行分析,并自动作为reviewer添加到commit中。我们针对code review任务的分派或者说路由选择还有一些其他的规则,比如说,如果没有reviewer的话,一个数据科学家可自动作为一个reviewer添加到启动A/B测试的commit中。实际上我们已经搭建了一些工具,可以让我们更容易的制定更多这类自定义的“路由”规则。举个例子,如果我们想做,那就很容易就能增加一个规则,可以将某一个新任务所有的commits都路由指派给相应的人员。
这样的一个智能系统,将所有的commits都分配给合适的人员进行代码审查,能有效减轻开发人员的负担,否则他们还需要四处寻找合适的审查人员,还要确保大部分的审查人员否能认真审查每条commit。
测试
测试对我们的开发流程来说是非常重要的一步,我们写了很多的单元测试、功能测试和UI测试代码,覆盖很大的测试范围。而一个综合性测试可以让开发人员并行工作,工作进行的更快,而不用担心会破坏现有功能。我们投入了大量时间来制定测试框架(建立在nosetests之上),使其容易使用、可快速应用,从而降低编写测试代码的间接费用。
我们还开发了几项工具,可以实现测试的自动化。我们之前发布了一篇关于“持续集成系统”的文章,描述了一个中心服务器,可以在部署任何新代码之前运行所有测试。该测试服务器可以并行运行,这样的话运行所有的测试只需要不到5分钟的时间。这样的快速运转可以激励人们经常性的编写和执行测试程序。我们有一个叫做“test-local”的工具,只能识别和执行代码工作副本的测试变更相关的测试文件。为了能做的更好,我们的测试还需要进行模块化(这能进一步帮我们在测试失败的时候进行快速调试)。为了确保好的测试代码能得到期望的性能,我们维护了一个共享文档,描述了编写测试代码相关的最佳实践。这些指导方针在代码审查过程中会被严格执行。
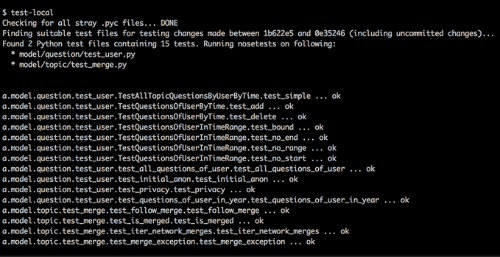
同code review一样,我们对不同类型的变更也有不同的测试标准,对测试范围有更高的要求,尤其是变更成本很高的情况。
所有这些系统使得我们能够从写测试代码的过程中获取最大收益,可以以很小的间接费用节省很多的开发周期。
代码质量指南
我们非常热衷于共享代码质量标准的指南,它可以帮我们做很多事情:
- 作为新开发人员培训的很好的工具。
- 与整个团队分享每个人的智慧和最佳实践。
- 降低开发和代码审查过程的间接费用。比如说,我们讨论一次就可以得出一些有价值的结论的话,那么再在每次code review时讨论代码行应该是80个字符串还是100个字符串就完全没有意义了。
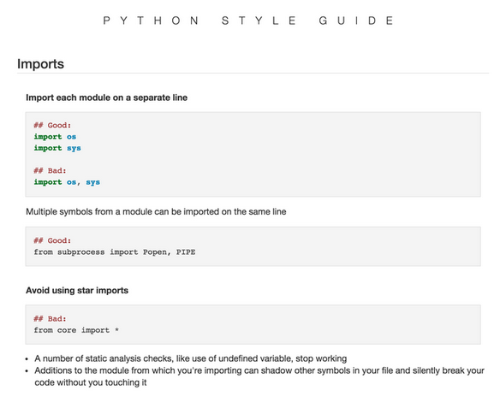
除了针对不同语言的语法风格指南,我们还有一些针对抽象事务的指导,比如如何写一个好的测试用例,或者如何做出更好的模块架构,从而提高工作效率。这些指南不是一成不变的,是随着我们对不同的过程有了更深的理解而不断发展的。我们还有很多重构的工具(一些开源工具比如codemod,还有一些内部开发的工具),以备我们改变指南的时候需要重新“修改”所有的历史代码。
旧代码的清理
一个快速发展的团队会尝试很多不同的工具,当然其中不乏有一些可以用而有一些不可用。到最后,任何一家快速发展的公司,随着时间的推移其代码库都会开发很多多余的东西,而这些可能永远都不会再用,放在那里只会使很多东西变得混乱。清理这些废弃代码可以使得代码库更健康的运行,还能提升开发的速度。
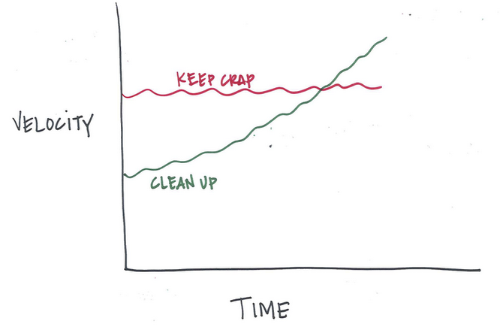
我们会定期组织“清理周”,对这些多余代码进行清理。在清理周内,某一些团队或者有时会发动整个公司专门来清理旧代码。这种定期的清理模式可以降低在“正常工作”和“清理工作”之间来回转换的成本,还能使得清理工作更加社交化,更加有乐趣。
代码库有些部分会比其他部分相对更好清理一些。同样地,清理代码库的不同部分会对开发速度产生不同的影响。为了能更好的利用好旧代码清理的时间,我们在考虑成本的基础上优化了相关模块,来进行清理工作,以及衡量清理工作对未来开发速度的影响。
Linting
我们很可能会低估在某一实例中不遵循上述代码质量指南(比如说docstring的格式或代码行长度)所造成的成本,但事实上成本的确是增加了。同时,要记住各种各样的规则并应用,也是一件很烦的事情,尤其是规则还在不断增加。最终造成的结果就是,很多人都选择不再遵循这些指导方针。
我们开发了一个内部的linter,叫做qlint,可以相应减轻一些上述困扰。qlint是一个很智能的linter,可以读懂文本结构以及AST,是基于flake8和pylint的。它旨在使得未来增加自定义的lint规则变得更容易。比如说,我们其中一个做法是Python中任何一个“私有”变量都需要进行突出强调,所以我们在qlint中新增了一个规则,那就是可以检测出这类私有变量中任何不合理的地方。
我们还将qlint与很多系统集成起来,提供无缝的开发环境,这样人们就不必亲自盯着lint错误。对于新手来说,qlint是一个与我们常用的文本编辑器——Vim,Emacs和Sublime——充分集成的工具,可以在规则被破坏的情况下提供可视的反馈(红色标记)。它还与我们的推送流程集成在了一起,任何人在进行code推送的时候都可以运行qlint(以互动的方式)。而实际上,如果某项规则被commit打破,它有可能就会影响到部署工作。我们还将我们的风格指南与qlint集成起来,这样对每一个lint错误,qlint都可以给出一个超链接,指向相关风格指导的相应规则。我们的Phabricator也可以用qlint。通过这种方式,所有被qlint找到的错误都被明显的标记出来,这样他们的代码审查工作就变得相当容易了。

所有这些都帮我们实现了以很小的成本就能提升代码的一致性和质量。
结论
就像文章中所说的那样, Quora对代码的重视程度是很高的。我们讲求务实主义,搭建了很多好的系统、工具和流程,能帮我们增强并维护长期开发的生产效率。今天我们努力维持一个良好的平衡,我们的团队也在不断成长和发展,所以我们相信,未来我们还将生产更多的工具和系统。
如果你想帮我们搭建这样的系统,或者想成为我们强大开发团队的一份子,帮助我们以这样一种务实的、深刻的方式提升代码质量,那么欢迎加入我们。

 );){kind=link}