关于现代 CPU,程序员应当更新的知识
有人在Twitter上谈到了自己对CPU的认识:
我记忆中的CPU模型还停留在上世纪80年代:一个能做算术、逻辑、移位和位操作,可以加载,并把信息存储在记忆体中的盒子。我隐约意识到了各种新发展,例如矢量指令(SIMD),新CPU还拥有了虚拟化支持(虽然不知道这在实际使用中意味着什么)。
我错过了哪些很酷的发展呢?有什么是今天的CPU可以做到而去年还做不到的呢?那两年,五年或者十年之前的CPU又如何呢?我最感兴趣的事是,哪些程序员需要自己动手才能充分利用的功能(或者不得不重新设计编程环境)。我想,这不该包括超线程/SMT,但我并不确定。我也对暂时CPU做不到但是未来可以做得到的事感兴趣。
本文内容除非另有说明,都是指在x86和Linux环境下。历史总在重演,很多x86上的新事物,对于超级计算机、大型机和工作站来说已经是老生常谈了。
现状
杂记
现代CPU拥有更宽的寄存器,可寻址更多内存。在上世纪80年代,你可能已经使用过8位CPU,但现在肯定已在使用64位CPU。除了能提供更多地址空间,64位模式(对于32位和64位操作通过x867浮点避免伪随机地获得80位精度)提供了更多寄存器和更一致的浮点结果。自80年代初已经被引入x86的其他非常有可能用到的功能还包括:分页/虚拟内存,pipelining和浮点运算。
本文将避免讨论那些写驱动程序、BIOS代码、做安全审查,才会用到的不寻常的底层功能,如APIC/x2APIC,SMM或NX位等。

内存/缓存 (Memory / Caches)
在所有话题中,最可能真正影日常编程工作的是内存访问。我的第一台电脑是286在,那台机器上,一次内存访问可能只需要几个时钟周期。几年前,我使用奔腾4,内存访问需要花费超过400时钟周期。处理器比内存的发展速度快得多,对于内存较慢问题的解决方法是增加缓存,如果访问模式可被预测,常用数据访问速度更快,还有预取——预加载数据到缓存。
几个周期与400多个相比,听起来很糟——慢了100倍。但一个对64位(8字节)值块读取并操作的循环,CPU聪明到能在我需要之前就预取正确的数据,在3Ghz处理器上,以约22GB/s的速度处理,我们只丢了8%的性能而不是100倍。
通过使用小于CPU缓存的可预测内存访问模式和数据块操作,在现代CPU缓存架构中能发挥最大优势。如果你想尽可能高效,这份文件是个很好的起点。消化了这100页PDF文件后,接下来,你会想熟悉系统的微架构和内存子系统,以及学习使用类似likwid这样的工具来分析和测验应用程序。
TLB
芯片里也有小缓存来处理各种事务,除非需要全力实现微优化,你并不需要知道解码指令缓存和其他有趣的小缓存。最大的例外是TLB——虚拟内存查找缓存(通过x86上4级页表结构完成)。页表在L1数据缓存,每个查询有4次,或16个周期来进行一次完整的虚拟地址查询。对于所有需要被用户模式内存访问的操作来说,这是不能接受的,从而有了小而快的虚拟地址查找的缓存。
因为第一级TLB缓存必须要快,被严重地限制了尺寸。如果使用4K页面,确定了在不发生TLB丢失的情况下能找到的内存数量。x86还支持2MB和1GB页面;有些应用程序会通过使用较大页面受益匪浅。如果你有一个长时间运行,且使用大量内存的应用程序,很值得研究这项技术的细节。
乱序执行/序列化 (Out of Order Execution / Serialization)
最近二十年,x86芯片已经能思考执行的次序(以避免因为一个停滞资源而被阻塞)。这有时会导致很奇怪的表现。x86非常严格的要求单一CPU,或者外部可见的状态,像寄存器和记忆体,如果每件事都在按照顺序执行都必须及时更新。
这些限制使得事情看起来像按顺序执行,在大多数情况下,你可以忽略OoO(乱序)执行的存在,除非要竭力提高性能。主要的例外是,你不仅要确保事情在外部看起来像是按顺序执行,实际上在内部也要真的按顺序。
一个你可能关心的例子是,如果试图用rdtsc测量一系列指令的执行时间,rdtsc将读出隐藏的内部计数器并将结果置于edx和eax这些外部可见的寄存器。
假设我们这样做:
foo
rdtsc
bar
mov %eax, [%ebx]
baz其中,foo,bar和baz不去碰eax,edx或[%ebx]。跟着rdtsc的mov会把eax值写入内存某个位置,因为eax外部可见,CPU将保证rdtsc执行后mov才会执行,让一切看起来按顺序发生。
然而,因为rdtsc,foo或bar之间没有明显的依赖关系 ,rdtsc可能在foo之前,在foo和bar之间 ,或在bar之后。甚至只要baz不以任何方式影响移mov,令也可能存在baz在rdtsc之前执行的情况。有些情况下这么做没问题,但如果rdtsc被用来衡量foo的执行时间就不妙了。
为了精确地安排rdtsc和其他指令的顺序,我们需要串行化所有执行。如何准确的做到?请参考英特尔的这份文档。
内存/并发 (Memory / Concurrency)
上面提到的排序限制意味着相同位置的加载和存储彼此间不能被重新排序,除此以外,x86加载和存储有一些其他限制。特别是,对于单一CPU,不管是否是在相同的位置,存储不会与之前的负载一起被记录。
然而,负载可以与更早的存储一起被记录。例如:
mov 1, [%esp]
mov [%ebx], %eax执行起来就像:
mov [%ebx], %eax
mov 1, [%esp]但反之则不然——如果你写了后者,它永远不能像你前面写那样被执行。
你可能通过插入串行化指令迫使前一个实例像写起来一样来执行。但是这需要CPU序列化所有指令这会非常缓慢,因为它迫使CPU要等到所有指令完成串行化后才能执行任何操作。如果你只关心加载/存储顺序,另外还有一个 mfence指令只用于序列化加载和存储。
本文不打算讨论memory fence,lfence和sfence,但你可以在这里阅读更多关于它们的内容 。
单核加载和存储大多是有序的,对于多核,上述限制同样适用;如果core0在观察core1,就可以看到所有的单核规则适用于core1的加载和存储。然而如果core0和core1相互作用,不能保证它们的相互作用也是有序的。
例如,core0和core1通过设置为0的eax和edx开始,core0执行:
mov 1, [_foo]
mov [_foo], %eax
mov [_bar], %edx而core1执行
mov 1, [_bar]
mov [_bar], %eax
mov [_foo], %edx对于这两个核来说, eax必须是1,因为第一指令和第二指令相互依赖。然而,eax有可能在两个核里都是0,因为core0的第三行可能在core1没看到任何东西时执行,反之亦然。
memory barriers序列化一个核心内的存储器访问。Linus对于使用memory barriers而不是使用locking有这样一段话 :
不用locking的真正代价最终不可避免。通过使用memory barriers自以为聪明的做事几乎总是错误的前奏。在所有可以发生在十多种不同架构并且有着不同的内存排序的情况下,缺失一个小小的barrier真的很难让你理清楚…事实上,任何时候任何人编了一个新的锁定机制,他们总是会把它弄错。
而事实证明,在现代的x86处理器上,使用locking来实现并发通常比使用memory barriers代价低,所以让我们来看看锁。
如果设置_foo为0,并有两个线程执行incl (_foo)10000次——一个单指令同一位置递增20000次,但理论上结果可能2。搞清楚这一点是个很好的练习。
我们可以用一段简单的代码试验:
#include <stdlib.h>
#include <thread>
#define NUM_ITERS 10000
#define NUM_THREADS 2
int counter = 0;
int *p_counter = &counter;
void asm_inc() {
int *p_counter = &counter;
for (int i = 0; i < NUM_ITERS; ++i) {
__asm__("incl (%0) \n\t" : : "r" (p_counter));
}
}
int main () {
std::thread t[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; ++i) {
t[i] = std::thread(asm_inc);
}
for (int i = 0; i < NUM_THREADS; ++i) {
t[i].join();
}
printf("Counter value: %i\n", counter);
return 0;
}用clang++ -std=c++11 –pthread在我的两台机器上编译得到的分布结果如下:
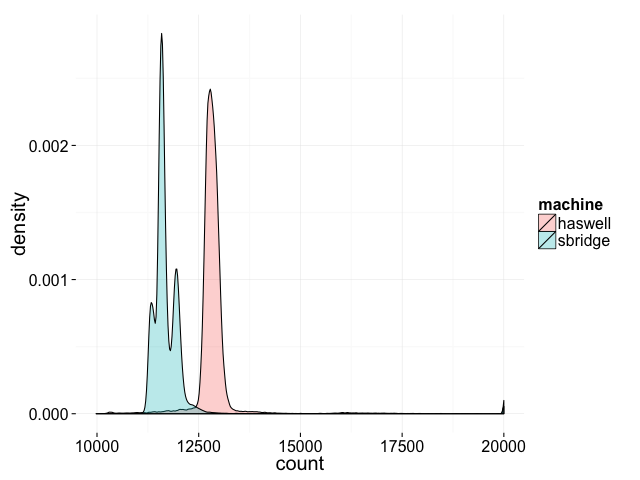
不仅得到的结果在运行时变化,结果的分布在不同的机器上也是不同。我们永远没到理论上最小的2,或就此而言,任何低于10000的结果,但有可能得到10000和20000之间的最终结果。
尽管incl是个单独的指令,但不能保证原子性。在内部,incl是后面跟一个add后再跟一个存储的负载。在cpu0里的一个增加有可能偷偷的溜进cpu1里面的负载和存储之间执行,反之亦然。
英特尔对此的解决方案是少量的指令可以加lock前缀,以保证它们的原子性。如果我们把上面代码的incl改成lock incl,输出始终是20000。
为了使序列有原子性,我们可以使用xchg或cmpxchg, 它们始终被锁定为比较和交换的基元。本文不会详细描它是如何工作的,但如果你好奇可以看这篇David Dalrymple的文章。
为了使存储器的交流原子性,lock相对于彼此在global是有序的,而且加载和存储对于锁不会被重新排序相。对于内存排序严格的模型,请参考x86 TSO文档。
在C或C++中:
local_cpu_lock = 1;
// .. 做些重要的事 ..
local_cpu_lock = 0;编译器不知道local_cpu_lock = 0不能被放在重要的中间部分。Compiler barriers与CPU memory barriers不同。由于x86内存模型是比较严格,一些编译器的屏障在硬件层面是选择不作为,并告诉编译器不要重新排序。如果使用的语言比microcode,汇编,C或C++抽象层级高,编译器很可能没有任何类型的注释。
内存/移植 (Memory / Porting)
如果要把代码移植到其他架构,需要注意的是,x86也许有着今天你能遇到的任何架构里最强的内存模式。如果不仔细思考,它移植到有较弱担保的架构(PPC,ARM,或Alpha),几乎肯定得到报错。
CPU1 CPU2
---- ----
if (x == 1) z = y;
y = 5; mb();
x = 1;…如果我读了Alpha架构内存排序保证正确,那么至少在理论上,你真的可以得到Z = 5
mb是memory barrier(内存屏障)。本文不会细讲,但如果你想知道为什么有人会建立这样一个允许这种疯狂行为发生的规范,想一想成产成本上升打垮DEC之前,其芯片快到可以在相同的基准下通过仿真运行却比x86更快。对于为什么大多数RISC-Y架构做出了当时的决定请参见关于Alpha架构背后动机的论文。
顺便说一句,这是我很怀疑Mill架构的主要原因。暂且不论关于是否能达到他们号称的性能,仅仅在技术上出色并不是一个合理的商业模式。
内存/非临时存储/写结合存储器 (Memory / Non-Temporal Stores / Write-Combine Memory)
上节所述的限制适用于可缓存(即“回写(write-back)”或WB)存储器。在此之前,只有不可缓存(UC)内存。
一个关于UC内存有趣的事情是,所有加载和存储都被设计希望能在总线上加载或存储。对于没有缓存或者几乎没有板载缓存的处理器,这么做完全合理。
内存/NUMA
非一致内存访问(NUMA),即对于不同处理器来说,内存访问延迟和带宽各有不同。因为NUMA或ccNUMA如此普遍,以至于是被默认为采用的。
这里要求的是共享内存的线程应该在同一个socket上,内存映射I/O重线程应该确保它与最接近的I/O设备的socket对话。
曾几何时,只有内存。然后CPU相对于内存速度太快以致于人们想增加一个缓存。缓存与后备存储器(内存)不一致是一个坏消息,因此缓存必须保持它坚持着什么的信息,所以它才知道是否以及何时它需要向后备存储写东西。
这不算太糟糕,而一旦你获得了两个有自己缓存的核心,情况就变复杂了。为了保持作为无缓存的情况下相同的编程模型,缓存必须相互之间以及与后备存储器是一致的。由于现有的加载/存储指令在其API中没有什么允许他们说“对不起!这个加载因为别的cpu在使用你想用的地址而失败了” ,最简单的方式是让每个CPU每次要加载或存储东西的时候发一个信息到总线上。我们已经有了这个两个CPU都可以连接的内存总线,所以只要要求另一个CPU在其数据缓存有修改时做出回复(并失去相应的缓存行)。
在大多数情况下,每个CPU只涉及其他CPU不关心的数据,所以有一些浪费的总线流量。但不算糟糕,因为一旦CPU拿出一条消息说“你好!我要占有这个地址并修改数据”,可以假定在其他的CPU要求前完全拥有该地址,虽然不是总会发生。
对于4核CPU,依然可以工作,虽然字节浪费相比有点多。但其中每个CPU对其他每一个CPU的响应失败比例远远超出4个CPU总和,既因为总线被饱和,也因为缓存将得到饱和(缓存的物理尺寸/成本是以同时的读和写数量 O(n^2) ,并且速度与大小负相关)。
这个问题“简单”的解决方法是有一个单独的集中目录记录所有的信息,而不是做N路的对等广播。反正因为现在我们正在一个芯片上包2-16个内核,每个芯片(socket)对每个核的缓存状态有个单一目录跟踪是很自然的事。
不仅解决了每个芯片的问题,而且需要通过某种方式让芯片相互交谈。不幸的是,当我们扩展这些系统即使对于小型系统总线速度也快到真的很难驱动一个信号远到连接一堆芯片和都在一条总线上的记忆体。最简单的解决办法就是让每个插座都拥有一个存储器区域,所以每一个socket并不需要被连接到的存储器每一个部分。因为它很明确哪个目录拥有特定的一段内存,这也避免了目录需要一个更高级别的目录的复杂性。
这样做的缺点是,如果占用一个socket并且想要一些被别的socket拥有的memory,会有显著的性能损失。为简单起见,大多数“小”(<128核)系统使用环形总线,因此性能损失的不仅仅是通过一系列跳转达到memory付出的直接延迟/带宽处罚,他也用光了有限的资源(环状总线)和减慢了其他socekt的访问速度。
理论上来讲,OS会透明处理,但往往低效 。
Context Switches/系统调用(Syscalls)
在这里,syscall是指Linux的系统调用,而不是x86的SYSCALL或者SYSENTER指令。
所有现代处理器具有一个副作用是,Context Switches代价昂贵,这会导致系统调用代价高昂。Livio Soares和Michael Stumm的论文对此做了详细讨论。我在下文将用一些他们的数据。下图为Xalan上的酷睿i7每一个时钟可以多少指令(IPC):
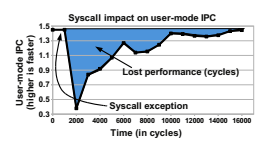
系统调用的14000周期后,代码仍不是全速运行。
下面是几个不同的系统调用的足迹表,无论是直接成本(指令和周期),还是间接成本(缓存和TLB驱逐的数量)。
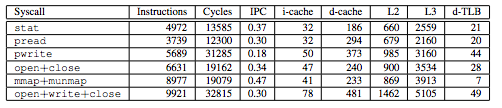
有些系统调用引起了40多次的TLB回收!对于具有64项D-TLB的芯片,几乎扫荡光了TLB。缓存回收不是毫无代价。
系统调用的高成本是人们对于高性能的代码转而进行使用脚本化的系统调用(例如epoll, 或者recvmmsg)究其原因,人们需要高性能I/O经常使用用户空间的I/O stack。Context Switches的成本就是为什么高性能的代码往往是一个核心一个线程(甚至是固定线程上一个单线程),而不是每个逻辑任务一个线程的原因。
这种高代价也是VDSO在后面驱动,把一些简单的不需要任何升级特权的系统调用放进简单的用户空间库调用。
SIMD
基本上所有现代的x86 CPU都支持SSE,128位宽的向量寄存器和指令。因为要完成多次相同的操作很常见,英特尔增加了指令,可以让你像为2个64位块一样对128位数据块操作,或者4个32位的块,8个16位块等。ARM用不同的名字(NEON)支持同样的事情,而且支持的指令也很相似。
通过使用SIMD指令获得了2倍,4倍加速这是很常见的,如果你已经有了一个计算繁重的工作这绝对值得期待。
编译器足够到可以分辨常见的可以实现矢量化模式的简单的代码,就像下面代码,会自动使用现代编译器的向量指令:
for (int i = 0; i < n; ++i) {
sum += a[i];
}但是,如果你不手写汇编语言,编译器经常会产生非优化的代码 ,特别是对SIMD代码,所以如果你很关心尽可能的得到最佳性能,你就要看看反汇编并检查你编译器的优化错误。
电源管理
有现代CPU都有很多花哨的电源管理功能用来在不同的场景优化电源使用。这些的结果是“跑去闲置”,因为尽可能快的完成工作,然后让CPU回去睡觉是最节能的方式。
尽管有很多做法已经被证明进行特定的微优化可以对电源消耗有利,但把这些微优化应用在实际的工作负载中通常会比预期的收益小 。
GPU/GPGPU
相比其他部分我不是很够资格来谈论这些。幸运的是,Cliff Burdick自告奋勇地写了下面这节:
2005年之前,图形处理单元(GPU)被限制在一个只允许非常有限硬件控制量的API。由于库变得更加灵活,程序员开始使用处理器处理更常用的任务,如线性代数例程。GPU的并行架构可以通过发射数百并发线程在大量的矩阵块中工作。然而,代码必须使用传统的图形API,并仍被限制于可以控制多少硬件。Nvidia和ATI注意到了这点并发布了可以使显卡界外的人更熟悉的API来获得更多的硬件访问的框架。该库得到了普及,今天的GPU同CPU一起被广泛用于高性能计算(HPC)。
相比于处理器,GPU硬件主要有几个差别,概述如下:
处理器
在顶层,一个GPU处理器包含一个或多个数据流多重处理器(SMs)。现代GPU的每个流的多重理器通常包含超过100个浮点单元,或在GPU的世界通常被称为核。每个核心通常主频在800MHz左右,虽然像CPU一样,具有更高的时钟频率但较少内核的处理器也存在。GPU的处理器缺乏自己同行CPU的许多特色,包括更大的缓存和分支预测。在核的不同层,SMs,和整体处理器之间,通讯变得越来越慢。出于这个原因,在GPU上表现良好的问题通常是高度平行的,但有一些数据能够在小数目的线程间共用。我们将在下面的内存部分解释为什么。
内存(Memory)
现代GPU内存被分为3类:全局内存,共享内存和寄存器。全局存储器是GDDR通常GPU盒子上广告宣称约为2-12GB大小,并具有通过300-400GB /秒的速度。全局存储器在处理器上的所有SMS所有线程都能被访问,并且也是内存卡上最慢的类型。共享内存,正如其名所指,是同一个SM中的所有线程之间共享内存。它通常至少是全局储蓄器两倍的速度,但对不同SM的线程之间是不被允许进行访问的。寄存器很像在CPU上的寄存器,他们是GPU上访问数据最快的方式,但它们只在每个本地线程,数据对于其他正在运行的不同线程是不可见的。共享内存和全局内存对他们如何能够被访问都有很严格的规定,对不遵守这些规则的行为有严重性能下降的处罚。为了达到上述吞吐量,内存访问必须在同线程组间线程之间完整的合并。类似于CPU读入一个单一的缓存行,如果对齐合适的话,GPU对于单一的访问可以有缓存行可以服务一个组里的所有线程。然而,最坏的状况是一组里所有线程访问不同的缓存行,每个线程都要求一个独立的记忆体读。这通常意味着缓存行中的数据不被线程使用,并且存储器的可用吞吐量下降。类似的规则同样适用于共享内存,有一些例外,我们将不在这里涵盖。
线程模型 (Threading Model)
GPU线程在一个单指令多线程(SIMT)方式下运行,并且每个线程以组的形式在硬件中以预定义大小(通常32)运行。这最后一部分有很多的影响;该组中的每个线程必须同一时间在同一指令下工作。如果任何一组中的线程的需要从他人那里获得代码的发散路径(例如一个if语句)的代码,所有不参与该分支的线程会到该分支结束才能开始。作为一个简单的例子:
if (threadId < 5) {
// Do something
}
// Do More在上面的代码中,这个分支会导致我们的32个线程中的27组暂停执行,直到分支结束。你可以想象,如果多组线程运行这段代码,整体性能会因大部分的内核处于闲置状态将受到很大打击。只有当线程整组被锁定才能使硬件允许交换另外一组的核来运行。
接口(Interfaces)
现代GPU必须有一个CPU同CPU和GPU内存之间进行数据复制的发送和接收,并启动GPU并且编码。在最高吞吐量的情况下,一个有着16个通道的PCIe 3.0总线可达到约13-14GB / s的速度。这可能听起来很高,但相对于存在GPU本身的内存速度,他们慢了一个数量级。事实上,图形处理器变得更强大以致于PCIe总线日益成为一个瓶颈。为了看到任何GPU超过CPU的性能优势,GPU的必须装有大量的工作,以使GPU需要运行的工作的时间远远的高于数据发送与接收的时间。
较新的GPU具备一些功能可以动态的在GPU代码里分配工作而不需要再回到CPU推出的GPU代码中动态的工作,而无需返回到CPU,单目前他的应用相当有局限性。
GPU结论
由于CPU和GPU之间主要的架构差异,很难想象任何一个完全取代另一个。事实上,GPU很好的补充了CPU的并行工作,使CPU可以在GPU运行时独立完成其他任务。AMD公司正在试图通过他们的“非均相体系结构”(HSA)合并这两种技术,但用现有的CPU代码,并决定如何将处理器的CPU和GPU部分分割开来将是一个很大的挑战,不仅仅对于处理器来说,对于编译器也是。
虚拟化
除非你正在编写非常低级的代码直接处理虚拟化,英特尔植入的虚拟化指令通常不是你需要思考的问题。
同那些东西打交道相当混乱,可以从这里的代码看到。即使对于那里展示的非常简单的例子,设置起用Intel的VT指令来启动一个虚拟客户端也需要大约1000行低阶代码。
虚拟内存
如果你看一下Vish的VT代码,你会发现有一块很好的代码专门用于页表/虚拟内存。这是另一个除非你正在编写操作系统或其他低级别的系统代码你不必担心的“新”功能。使用虚拟内存比使用分段存储器更简单,但本文暂且讨论到这里。
SMT/超线程 (Hyper-threading)
超线程对于程序员来说大部分是透明的。一个典型的在单核上启用SMT的增速是25%左右。对于整体吞吐量来说是好的,但它意味着每个线程可能只能获得其原有性能的60%。对于您非常关心单线程性能的应用程序,你可能最好禁用SMT。虽然这在很大程度上取决于工作量,而且对于任何其他的变化,你应该在你的具体工作负载运行一些基准测试,看看有什么效果最好。
所有这些复杂性添加到芯片(和软件)的一个副作用是性能比曾经预期的要少了很多;对特定硬件基准测试的重要性相对应的有所回升。
人们常常用“计算机语言基准游戏”作为证据来说一种语言比另一种速度更快。我试着自己重现的结果,用我的移动Haswell(相对于在结果中使用的服务器Kentsfield),我得到的结果可以达到高达2倍的不同(相对速度)。即使在同一台机器上运行同一个基准,Nanthan Kurz 最近向我指出一个例子 gcc -O3 比 gcc –O2 慢25%改变对C ++程序的链接顺序可导致15%的性能变化 。评测基准的选定是个难题。
分行 (Branches)
传统观念认为使用分支是昂贵的,并且应该尽一切(大多数)的可能避免。在Haswell上,分支的错误预测代价是14个时钟周期。分支错误预测率取决于工作量。在一些不同的东西上使用 perf stat (bzip2,top,mysqld,regenerating my blog),我得到了在0.5%和4%之间的分支错误预测率。如果我们假设一个正确的预测的分支费用是1个周期,这个平均成本在.995 * 1 + .005 * 14 = 1.065 cycles to .96 * 1 + .04 * 14 = 1.52 cycles之间。这不是很糟糕。
从约1995年来这实际上夸大了代价,由于英特尔加入条件移动指令,使您可以在无需一个分支的情况下有条件地移动数据。该指令曾被Linus批判的令人难忘的 ,这给了它一个不好的名声,但是相比分支,使用cmos更有显著的加速这是相当普遍的额外分支成本的一个现实中的例子是使用整数溢出检查。当使用bzip2来压缩一个特定的文件,那会增加约30%的指令数量(所有的增量从额外分支指令得来),这导致1%的性能损失 。
不可预知的分支是不好的,但大部分的分支是可以预见的。忽略分支的费用直到你的分析器告诉你有一个热点在如今是非常合理的。CPUs在过去十年中执行优化不好代码方面变好了很多,而且编译器在优化代码方面也变得更好,这使得优化分支变成了不良的使用时间,除非你试图在一些代码中挤出绝对最佳表现。
如果事实证明这就是你所需要做的,你最好还是使用档案导引优化而不是试图手动去搞这个东西。
如果你真的必须用手动做到这一点,有些编译器指令你可以用来表示一个特定分支是否有可能被占用与否。现代CPU忽略了分支提示说明,但它们可以帮助编译器更好得布局代码。
对齐 (Alignment)
经验告诉我们应该拉长struct,并确数据对齐。但在Haswell的芯片上,几乎任何你能想到的任何不跨页的单线程事情的误配准为零。有些情况下它是有用的,但在一般情况下,这是另一种无关紧要的优化因为CPU已经变得在执行不优良代码时好了很多。它无好处的增加了内存占用的足迹也是有一点害处。
而且, 不要把事情页面对齐或以其他方式排列到大的界限,否则会破坏缓存性能 。
自修改代码 (Self-modifying code)
这是另外一个目前已经不怎么有意义的优化了。使用自修改代码以减少代码量或增加性能曾经有意义,但由于现代的缓存倾向于拆分他们的L1指令和数据缓存,在一个芯片的L1缓存之间修改运行的代码需要昂贵的通信。
未来
下面是一些可能的变化,从最保守的推测到最大胆的推测。
事务内存和硬件锁Elision (Transactional Memory and Hardware Lock Elision)
IBM已经在他们自己的POWER芯片中有这些功能。英特尔尝试着把这些东西加到Haswell,但因为一个报错被禁用了。
事务内存支持正如它听起来这样:事务的硬件支持。通过三个新的指令xbegin、xend和xabort。
xbegin开始一个新的事务。一个冲突(或xabort)使处理器(包括内存)的架构状态回滚到在xbegin的状态之前.如果您使用的是通过库或语言支持的事务内存,这对你来说应该透明的。如果你正在植入库支持,你就必须弄清楚如何将有有限的硬件缓冲区大小限制的硬件支持转换成抽象的事务。
本文打算讨论Elision硬件锁,在本质上,它被植入的机制与用于实现事务内存的机制非常相似,而且它是被设计来加快基于锁的代码。如果你想利用HLE,看看这个文档 。
快速I/O(Fast I/O)
对于存储和网络来说,I/O带宽正在不断上升,I/O延迟正在下降。问题是,I/O通常是通过系统调用完成。正如我们所看到的,系统调用的相对额外费用一直在往上走。对于存储和网络,答案是转移到用户模式的I/O堆栈。
黑硅(Dark Silicon)/系统级芯片
晶体管规模化一个有趣的副作用是我们可以把很多晶体管包进一个芯片上,但它们产生如此多的热量,如果你不希芯片融化,普通晶体管大多数时间不能开关。
这样做的结果把包括大量时间不使用的专用硬件变得更有意义。一方面,这意味着我们得到各种专用指令,如PCMP和ADX。但这也意味着,我们正把整个曾经不集成在芯片上的设备与芯片集成。包括诸如GPU和(用于移动设备)无线电。
与硬件加速的趋势相结合,这也意味着企业设计自己的芯片,或者至少自己芯片的部分变得更有意义。通过收购PA Semi公司,苹果公司已经走出了很远。首先,加入少量定制的加速器给停滞不前的标准的ARM架构,然后添加自定义加速器给他们自己定制的架构。由于正确的定制硬件和基准和系统设计深思熟虑的结合,iPhone 4比我的旗舰级Android手机反应还稍快,这个旗舰机比iPhone 4新了很多年,并且具有更快的处理器以及更大的内存。
亚马逊挑选了原Calxeda的团队的一部分,并雇用了一个足够大小的硬件设计团队。Facebook也已经挑选了ARM SoC的专家,并与高通公司在某些事情展开合作。Linus也有纪录在案的发言,“我们将在各个方面看到更多的专用硬件” 等等。
结论
x86芯片已经拥有了很多新的功能和非常有用的小特性。在大多数情况下,要利用这些优势你不需要知道它们具体是什么。真正的底层通常由库或驱动程序隐藏了起来,编译器将尝试照顾其余部分。例外是,如果你真的要写底层代码,这种情况下世界上已经变得更加混乱,或者如果你想在你的代码里获得绝对的最佳表现,就会更加怪异。
有些事似乎必然在未来发生。但过往的经验却又告诉我们,大多数的预测是错误的,所以谁又知道呢?

- [1]夜域诡士 [Chrome 42.0|GNU/Linux] 发表于 2015-09-16 22:20 的评论:图中的是一千左右的针数,看样子是拆下来的,还带有焊锡,即便是拆下来的,也不应该带有焊锡,可能是英特尔近几年出的CPU
- linux [Chrome 45.0|Mac 10.10] 2015-09-17 18:01 3 赞
- 图文无关~
- [1]来自美国的 Firefox 40.0|GNU/Linux 用户 发表于 2015-09-13 07:09 的评论:简直翻得狗屁不通啊
“However, loads can be reordered with earlier stores.” 翻译成 "然而,负载可以与更早的存储一起被记录。".
load reorder随便哪个大学的组成原理都讲的好吧. 译者没上过大学, 最好还是别在这误导人好么. - czwking1991 [Chrome 45.0|Windows 7] 2015-09-17 15:52 6 赞
- 弄得后来都去看原文了
- [1]夜域诡士 [Chrome 42.0|GNU/Linux] 发表于 2015-09-16 22:20 的评论:图中的是一千左右的针数,看样子是拆下来的,还带有焊锡,即便是拆下来的,也不应该带有焊锡,可能是英特尔近几年出的CPU
- 来自广东深圳的 Firefox 40.0|Fedora 用户 2015-09-16 23:34 2 赞
- 会不会时 AMD 的 - -!
- 来自广东深圳的 Firefox 40.0|Fedora 用户 2015-09-16 22:16 3 赞
-
文章不错 虽然翻译有点差强人意
那个虚拟化的简例 vmxon_simple 正好需要
赞一个
- 来自广东中山的 Maxthon 3.0|Windows XP 用户 2015-09-15 17:52 7 赞
- 反正没看懂几个词
- [1]来自美国的 Firefox 40.0|GNU/Linux 用户 发表于 2015-09-13 07:09 的评论:简直翻得狗屁不通啊
“However, loads can be reordered with earlier stores.” 翻译成 "然而,负载可以与更早的存储一起被记录。".
load reorder随便哪个大学的组成原理都讲的好吧. 译者没上过大学, 最好还是别在这误导人好么. - 绿色圣光 [Iceweasel 38.2|GNU/Linux] 2015-09-13 18:50 10 赞
- 反正我是基本看不懂。
 );){kind=link}