揭秘 TensorFlow:Google 开源到底开的是什么?
| 2015-11-15 14:02 收藏: 1

这两天发现朋友圈被Google开源深度学习系统TensorFlow的新闻刷屏了。这当然是一个很好的消息,尤其对我们这种用机器学习来解决实际问题的工程师来说更是如此。但同时很多人并不清楚听起来神乎其神的“TensorFlow”到底是什么,有什么意义。
我是人工智能科技公司“出门问问”的工程师,对人工智能“深度学习”理论有一定的了解,在这里就为大家“破雾”,聊一聊Google的开源系统TensorFlow。
什么是深度学习?
在机器学习流行之前,都是基于规则的系统,因此做语音的需要了解语音学,做NLP的需要很多语言学知识,做深蓝需要很多国际象棋大师。
而到后来统计方法成为主流之后,领域知识就不再那么重要,但是我们还是需要一些领域知识或者经验来提取合适的feature,feature的好坏往往决定了机器学习算法的成败。对于NLP来说,feature还相对比较好提取,因为语言本身就是高度的抽象;而对于Speech或者Image来说,我们人类自己也很难描述我们是怎么提取feature的。比如我们识别一只猫,我们隐隐约约觉得猫有两个眼睛一个鼻子有个长尾巴,而且它们之间有一定的空间约束关系,比如两只眼睛到鼻子的距离可能差不多。但怎么用像素来定义”眼睛“呢?如果仔细想一下就会发现很难。当然我们有很多特征提取的方法,比如提取边缘轮廓等等。
但是人类学习似乎不需要这么复杂,我们只要给几张猫的照片给人看,他就能学习到什么是猫。人似乎能自动“学习”出feature来,你给他看了几张猫的照片,然后问猫有什么特征,他可能会隐隐预约地告诉你猫有什么特征,甚至是猫特有的特征,这些特征豹子或者老虎没有。
深度学习为什么最近这么火,其中一个重要的原因就是不需要(太多)提取feature。
从机器学习的使用者来说,我们以前做的大部分事情是feature engineering,然后调一些参数,一般是为了防止过拟合。而有了深度学习之后,如果我们不需要实现一个CNN或者LSTM,那么我们似乎什么也不用干。(机器让工人失业,机器学习让搞机器学习的人失业!人工智能最终的目的是让人类失业?)

但是深度学习也不是万能的,至少现在的一个问题是它需要更强的计算能力才能训练出一个比较好的模型。它还不能像人类那样通过很少的训练样本就能学习很好的效果。
其实神经网络提出好几十年了,为什么最近才火呢?其中一个原因就是之前它的效果并不比非深度学习算法好,比如SVM。
到了2006年之后,随着计算能力的增强(尤其是GPU的出现),深度神经网络在很多传统的机器学习数据集上体现出优势来之后,后来用到Image和Speech,因为它自动学出的feature不需要人工提取feature,效果提升更加明显。这是否也说明,我们之前提取的图像feature都不够好,或者是根据人脑的经验提取的feature不适合机器的模型?
很多人对深度学习颇有微词的一个理由就是它没有太多理论依据,更多的像蛮力的搜索——非常深的层数,几千万甚至上亿参数,然后调整参数拟合输入与输出。其实目前所有的机器学习都是这样,人类的大脑的学习有所不同吗,不是神经元连接的调整吗?
但不管怎么说,从深度神经网络的使用者(我们这样的工程师)的角度来说,如果我们选定了一种网络结构,比如CNN,那么我们要做的就是根据经验,选择合适的层数,每层的神经元数量,激活函数,损失函数,正则化的参数,然后使用validation数据来判定这次训练的效果。从效果来说,一般层次越多效果越好(至少相对一两层的网络来说),但是层次越多参数也越多,训练就越慢。单机训练一个网络花几天甚至几周的时间非常常见。因此用多个节点的计算机集群来训练就是深度学习的核心竞争力——尤其对于用户数据瞬息万变的互联网应用来说更是如此。
常见深度神经网络的训练和问题
对于机器学习来说,训练是最关键也最困难的部分,一般的机器学习模型都是参数化的模型,我们可以把它看成一个函数y=f(w;x)。
比如拿识别图像来说,输入x是这张图片的每个像素值,比如MNIST的数据是28*28的图片,每个点是RGB的颜色值,那么x就是一个28*28*3的向量。而一个模型有很多参数,用w表示。输出y是一个向量,比如MNIST的数据是0-9的10个数字,所以我们可以让y输出一个10维的向量,分别代表识别成0-9的置信度(概率),选择最大的那个作为我们的识别结果(当然更常见的是最后一层是softmax而不是普通的激活函数,这样这个10维向量加起来等于1,可以认为是分类的概率)。
而训练就是给这个模型很多(x,y),然后训练的过程就是不断的调整参数w,然后使得分类错误尽可能少(由于分类错误相对w不连续因而不可求导,所以一般使用一个连续的Loss Function)。
对于神经网络来说,标准的训练算法就是反向传播算法。从数学上来说就是使用(随机)梯度下降算法,求Loss Function对每个参数的梯度。另外我们也可以从另外一个角度来看反向传播算法,比如最后一层的神经网络参数,直接造成错误;而倒数第二层的神经网络参数,通过这一次的激活函数影响最后一层,然后间接影响最终的输出。反向传播算法也可以看成错误不断往前传播的过程。
由于深度神经网络的参数非常多,比如GoogleNet, 2014年ILSVRC挑战赛冠军,将Top5 的错误率降低到6.67%,它是一个22层的CNN,有5百多万个参数。所以需要强大的计算资源来训练这么深的神经网络。
其中,CNN是Image领域常见的一种深度神经网络。由Yann LeCun提出,通过卷积来发现位置无关的feature,而且这些feature的参数是相同的,从而与全连接的神经网络相比大大减少了参数的数量。
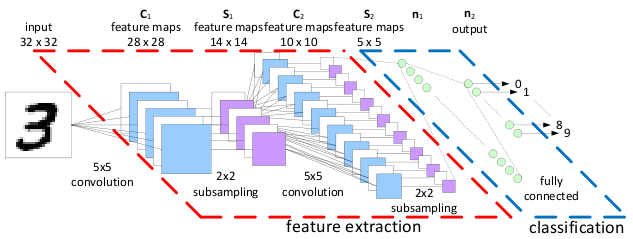
cnn深度神经网络
最开始的改进是使用GPU来加速训练,GPU可以看成一种SIMT的架构,和SIMD有些类似,但是执行相同指令的warp里的32个core可以有不同的代码路径。对于反向传播算法来说,基本计算就是矩阵向量乘法,对一个向量应用激活函数这样的向量化指令,而不像在传统的代码里会有很多if-else这样的逻辑判断,所以使用GPU加速非常有用。
但即使这样,单机的计算能力还是相对有限的。
深度学习开源工具
从数学上来讲,深度神经网络其实不复杂,我们定义不同的网络结构,比如层次之间怎么连接,每层有多少神经元,每层的激活函数是什么。前向算法非常简单,根据网络的定义计算就好了。
而反向传播算法就比较复杂了,所以现在有很多深度学习的开源框架来帮助我们把深度学习用到实际的系统中。
我们可以从以下几个不同的角度来分类这些开源的深度学习框架。
通用vs专用
深度学习抽象到最后都是一个数学模型,相对于传统的机器学习方法来说少了很多特征抽取的工作,但是要把它用到实际的系统中还有很多事情要做。而且对于很多系统来说,深度学习只是其中的一个模块。
拿语音识别来说,语音识别包含很多模块,比如声学模型和语言模型,现在的声学模型可以用LSTMs(一种RNN,也是一种深度学习网络)来做,但是我们需要把它融入整个系统,这就有很多工作需要做。而且目前大部分的机器学习方法包括深度学习,都必须假设训练数据和测试数据是相同(或者类似)的分布的。所以在实际的应用中,我们需要做很多数据相关的预处理工作。
比如Kaldi,它是一个语音识别的工具,实现了语音识别的所有模块,也包括一些语音识别常用的深度神经网络模型,比如DNN和LSTM。
而Caffe更多的是用在图像识别,它实现了CNN,因为这个模型在图像识别上效果非常好。
框架vs库
大部分开源的深度学习工具把整个模型都封装好了,我们只需要指定一些参数就行了。比如我们使用Caffe的CNN。
但是还有一些工具只是提供一些基础库,比如Theano,它提供了自动求梯度的工具。
我们可以自己定义网络的结构,我们不需要自己求梯度。使用Theano的好处是如果我们“创造”一个新的网络结构或者是很新的深度神经网络,那么其它框架很可能还没有实现,所以Theano在学术界很流行。当然坏处就是因为它不可能针对特定的模型做优化,所以可能性能不如特定的实现那么好。
单机vs集群
目前大部分的开源工具都是单机版的,有些支持在一个节点的多个GPU训练,但是支持GPU cluster比较少,目前支持多机训练的有GraphLab和Deeplearning4j。
Tensor Flow到底是什么?
Tensor意味着N维数组,Flow意味着基于数据流图的计算,TensorFlow即为张量从图的一端流动到另一端。
TensorFlow 表达了高层次的机器学习计算,大幅简化了第一代系统,并且具备更好的灵活性和可延展性。TensorFlow一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型,从电话、单个CPU / GPU到成百上千GPU卡组成的分布式系统。

从目前的文档看,TensorFlow支持CNN、RNN和LSTM算法,这都是目前在Image,Speech和NLP最流行的深度神经网络模型。
而且从Jeff Dean的论文来看,它肯定是支持集群上的训练的。
在论文里的例子来看,这个架构有点像Spark或者Dryad等图计算模型。就像写Map-reduce代码一样,我们从高层的角度来定义我们的业务逻辑,然后这个架构帮我们调度和分配计算资源(甚至容错,比如某个计算节点挂了或者太慢)。目前开源的实现分布式Deep learning的GraphLab就是GAS的架构,我们必须按照它的抽象来编写Deep Learing代码(或者其它分布式代码,如果PageRank),而Deeplearning4j直接使用了Spark。
Map-Reduce的思想非常简单,但是要写出一个稳定可用的工业级产品来就不容易了。而支持分布式机器学习尤其是深度学习的产品就更难了,Google的TensorFlow应该是一种抽象方式,可惜现在开源的部分并没有这些内容。有点像Google开源了一个单机版的Hadoop,可以用这种抽象(Map-reduce)来简化大数据编程,但是实际应用肯定就大大受限制了。
深度学习能解决所有问题吗?
至少目前来看,深度学习只是在Speech和Image这种比较“浅层”的智能问题上效果是比较明显的,而对于语言理解和推理这些问题效果就不那么好了,也许未来的深度神经网络能解决更“智能”的问题,但只是目前还不行。
Google开源TensorFlow的意义
这一次的Google开源深度学习系统TensorFlow在很多地方可以应用,如语音识别,自然语言理解,计算机视觉,广告等等。但是,基于以上论点,我们也不能过分夸大TensorFlow这种通用深度学习框架在一个工业界机器学习系统里的作用。在一个完整的工业界语音识别系统里, 除了深度学习算法外,还有很多工作是专业领域相关的算法,以及海量数据收集和工程系统架构的搭建。
不过总的来说,这次谷歌的开源很有意义,尤其是对于中国的很多创业公司来说,他们大都没有能力理解并开发一个与国际同步的深度学习系统,所以TensorFlow会大大降低深度学习在各个行业中的应用难度。

 );){kind=link}