ZFS 那点事
| 2016-06-03 14:56
最近看到很多关于ZFS移植到Linux上文章,看来ZFS还是很被大家看好,那就写点关于ZFS的东西,之前对ZFS的使用主要集中在SmartOS上,那就在聊聊我对SmartOS上使用ZFS的体验和ZFS的特性吧。
ZFS COW (Copy On Write)
首先说下ZFS的copy on write 这个技术并不复杂,看下图比较清晰,
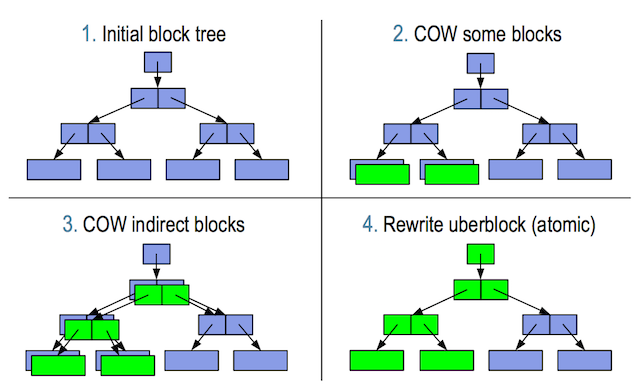
- 图-1: 可以看到uberblock实际上是Merkle Tree的root. 它记录了文件系统的所有状态,当检索一个数据块的时候, 会从uberblock这里一路往下查找metadata block同时比较checksum, 直到找到对应的数据块。
- 图-2: 当写一个新的block 时,没有performance的影响,当修改一个旧的block时,需要先copy一份, 实际上会带来一些performance的问题, 实际上所有的metadata和checksum都是需要复制新建。 但COW和Transaction技术一起,可以对数据的一致性得到比较好的保护。
- 图-3: 数据已经写入,上层的metadata和checksum的数据也已经修改好,但uberblock还没被更新,这个时候断电重新启动,数据不会丢失,我们仍然可用找到修改的数据, 然后将uberblock原子的更新。
-
图-4: uberblock是通过原子的方式,所有绿色的部分都已经更新。
COW 带来另一个好处是Snapshot,Replication非常方便, 如下图:
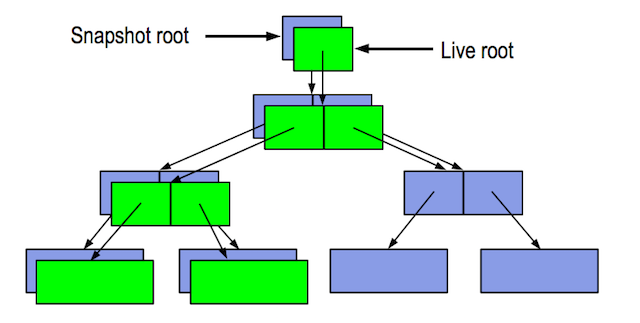
做snapshot只需要找上图中不同颜色的相关的数据指针即可!
再看Replication, 如下图: 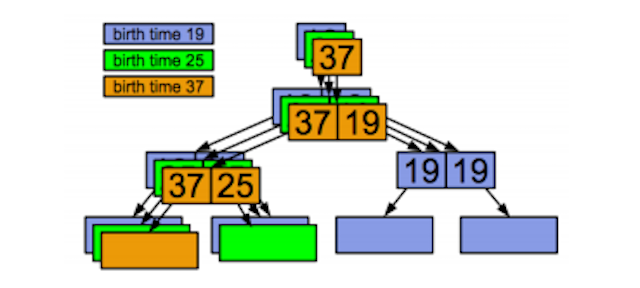
这里Merkle Tree的每个父亲节点都有一个birth time的元数据,birth time代表着transaction group的ID.这时如果想要复制19-37之间的数据就非常的容易,找到所有birth time大于19的父亲节点再使用数据指针和checksum的数据,找到对应的数据块即可用。
ZFS Checksum
在ZFS中,对所有数据不管是用户数据还是文件系统自身的metadata数据都进行256位的Checksum,Checksum的数据存储在父亲节点上,形成一棵自验证的Merkle Tree, 当ZFS在提交数据时会进行校验。
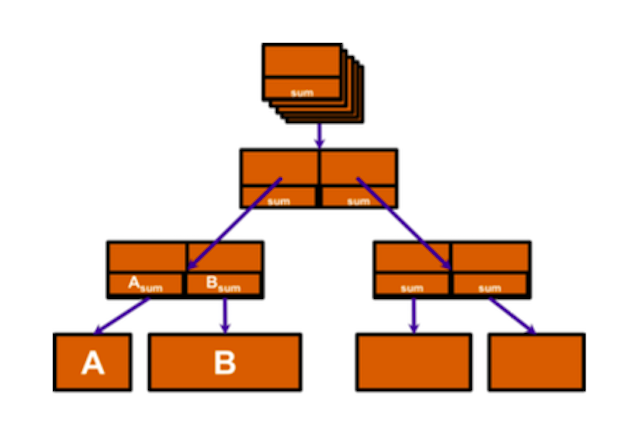
当磁盘,RAID卡的硬件问题或者驱动bug这种些Silent Data Corruption的情况,在ZFS中则提出了相对应的ZFS Mirror和RAID-Z方式,它在负责读取数据的时候会自动和256位校验码进行校验,会主动发现这种Silent Data Corruption,然后通过相应的Mirror硬盘或者通过RAID-Z阵列中其他硬盘得到正确的数据返回给上层应用,并且同时自动修复原硬盘的Corruption Data。
这样ZFS通过COW技术和Chumsum技术有效的保护了数据的完整性。
ZFS Raidz
ZFS提供了多种soft raid的方式,下面看使用比较多的Raidz的整列方式,创建各种Raidz1/2/3的情况下,vdev我们应该使用多少的磁盘会比较合适? 参考ZFS Best Practices 答案如下:
推荐使用2^n+x的个数, x指校验数据的份数, 即允许坏多少块盘。
- raidz1: 底层块设备个数3, 5, 9, 17等
- raidz2: 底层块设备个数4, 6, 10, 18等
- raidz3: 底层块设备个数5, 7, 11, 19等
建议基数不超过16(除非你的CPU特别强悍)
ZFS Dynamic Strip
由于ZFS是基于COW和一个全局动态的ZFS Pool,任何一次写 操作,都是对一块新数据块(Block)的一次写操作。ZFS从ZFS Pool中动态挑选出一个最优的设备,并且以一个transaction(事务)线性写入,充分有效地利用了现有设备的带宽, 也减少了read-modify-write的次数。如下图我们有5个磁盘,组成了raidz1的整列,每次不同的颜色代表不同的strip, 所有的写入都是一个完整的strip。对于写入的recordsize都是可以动态调整的,但只是对新文件创建有影响。已存在的文件还是保持其原有的recordsize。调节recordsize对顺序类型的负载没有帮助。调节recordsize的方式是针对使用随机少量的读写来密集的处理大文件的情况来提升作业量。

ZFS Transaction
先给个图看下ZFS的整个I/O Stack:
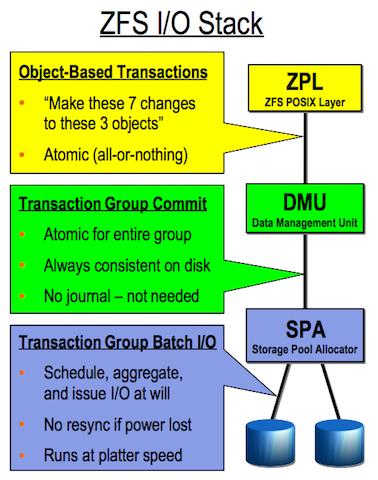
我们知道ZFS是事务型的文件系统,提供了同步和异步写2种方式,ZPL(zfs posix layer)把所有的写操作(包括metadata和real data)封装进了事务, ZPL会开事务把多个写操作放入一个事务, 这个事务并不会马上提交,将数据写到物理磁盘,而是收集起来放入一个transaction group。这里所有的写请求都会放在transaction group中,transaction group会同步或者异步的方式最总写到磁盘。
Trasction Group
在任意时刻,系统最多同时存在如下3种类型的transaction group在一个pool里面:
- Open Group: 维护文件系统把新的写请求
- Quiescing Group: 在这个group 新的写请求是无法加入的, 会等待所有Group中所有transaction commit。
- Sync Group: 将数据同步到磁盘。
这里你可能会问用多个transaction group而不是单个transaction带来了什么好处?
A:好处是你可以捆绑多个transaction进一个大的写操作,这样就减少了IOPS.
这里每个transaction group都有一个唯一的ID,而且这个ID是顺序单调递增的,这个标示写在uberblock里面,每次transaction group的sync都会更新这个uberblock, uberblock是一个ring buffer 128个slot, 存储在整个磁盘整列上, 将transaction group的id对128取模,就是这个transaction group在这个uberblock上的值。实际上zfs会在每个磁盘上存4个uberblock的副本,当zfs启动一个pool会查找所有4份uberblock副本的这128个slot找到transaction group id最大的uberblock, 把它设置成当前的可用uberblock.
这里问题来了,如果写uberblock的时候断电,怎么处理?
这里uberblock通过checksum的值来做断电保护,一个有效的uberblock需要符合条件:正确的checksum + 最大的transaction group id这2个条件。再加上ZFS Copy On Write的机制(uberblock一旦写成功,所有老的数据不再相关),保证了数据在磁盘上的一致性。
关于Transaction Group更细节的介绍可以看ZFS fundamentals Transaction Groups和illumos的源码txg.c
异步I/O
到这里你可能会问,对于用户写入数据到数据通过Sync Group同步到磁盘这段时间数据存哪里?
只要数据没有sync到磁盘,都是在ARC(Adaptive Replacement Cache)里面, 可以看成内存内,实际上是对内存的不停修改,所以当内存挂掉,内存中的数据也就没了,所以不建议将ZFS sync的配置设置成disable, 但是在data pool的数据一致性是可用保证的。
既然我们不推荐用async的方式,但我们又不能让数据仅仅留在内存(尽管留在内存的时间非常短暂5-30s),还是需要同步到磁盘, 这个时候ZIL登场了。
ZIL (ZFS Intent Log)
ZIL 我们一般使用一个或则多个硬盘,正常情况下使用ssd的磁盘,ZIL能记录所有的写操作,然后写到ZIL 的磁盘,因为zfs copy on write的机制,ZIL实际的存储信息很小, 只保存修改的数据,或者是数据块的外部指针, 假如你写入一个大的数据文件,如果设置logbias=troughput, 那么这个所有的写操作是直接到data pool的不经过ZIL, ZIL中只保存数据的指针, 所以说如果设置logbias=troughput,那么使用独立的ZIL设备是没有意义的。 如果logbias=latency,由于zfs对zil的使用有阈值限制, 例如单次提交的写超过阈值则直接写data pool, 否则会写入ZIL之后sync到data pool。这个阈值是通过设置zfs_immediate_write_sz (/etc/system文件)的大小来确定。所有的这些参数的调整要更据你的具体应用场景来确定。
这里如果我们不添加独立ZIL设备,实际上pool里面的数据盘上也会又ZIL的存储, 只要是ZFS sync=standard, 值得一提的是sync=always的话,所有文件系统的transaction是直接写到data pool.
为什么推荐独立的ZIL设备?
同步写操作减少对整个data pool的IOPS影响, 使用ssd做ZIL可用降低同步写的延迟, 这一点非常重要,NFS/ISCSI Target/OLTP Database等都是同步写,这里会大大提升性能。
稍微总结下:
- ZIL提供了断电情况下的数据保护。
- 在每次同步写发生的情况下避免更新整个磁盘的data structure.
- 大量的同步写操作会增加了整个data pool的IOPS的压力,所有需要使用独立的ZIL设备。
- 通过SSD作为独立ZIL设备可以加速同步写。甚至我们可以使用多个SSD将ZIL做成Mirror,防止单盘的失效。
- 如果你的data pool是全SSD的,又没有独立的ZIL设备,可以直接将logbias=throughput。
SmartOS 上ZFS I/O Throttle
对于在云平台多租户场景下任意一个租户vm的IO的burst可能会对其他租户的正常使用造成影响, SmartOS实现了I/O throttle:
- 跟踪每个vm的IO 请求,当IO 请求超过合理的范围,这个vm的所有read/write请求会delay一些时间,最大是100微秒。
- 每个vm的IO使用率指标计算公式: (number of read syscalls) x (Average read latency) + (number of write syscalls) x (Average write latency)
- IO throttle只会出现现在整个系统IO负载很大的场景下, 可以通过给vm设置zfs-io-priority参数来让某个vm获得比较大的IO优先级。注意zfs-io-priority这是一个相对值, 具体参考Tuning the IO Throttle
根据Smartos ZFS I/O Throttle, 在自己的环境用FIO, fsyncbomb测试了(read/write, write/write, read/read的场景)下,基本符合预期,可见SmartOS在这块做的还是不错的。
不错的参考

 );){kind=link}