日均请求量百亿级数据处理平台的容器云实践
| 2016-07-29 15:17 收藏: 1
编者按: 七牛云研发架构师袁晓沛,7 月 15 日在 ArchSummit 全球架构师峰会七牛云专场上,带来了题为《自定义数据处理平台的容器云实践》的分享,结合七牛云自定义数据处理平台业务的容器化实践,从平台的业务特点、为什么容器化、如何实现容器化以及容器实践的具体效果等角度进行了分享。以下是对他演讲内容的整理。
 袁晓沛:曾参与盛大网盘 EverBox、EMC 备份服务 Mozy 后端存储的设计、开发工作,主要方向在分布式系统的架构设计、开发、性能调优以及后期运维优化。目前在七牛云的主要工作是基于容器平台构建分布式应用,借助容器的优势,实现大规模分布式应用的自动化运维以及高可用,以 PaaS 服务的形式提供服务器后端应用,同时致力于让开发者从繁琐的后端运维工作中解放出来。
袁晓沛:曾参与盛大网盘 EverBox、EMC 备份服务 Mozy 后端存储的设计、开发工作,主要方向在分布式系统的架构设计、开发、性能调优以及后期运维优化。目前在七牛云的主要工作是基于容器平台构建分布式应用,借助容器的优势,实现大规模分布式应用的自动化运维以及高可用,以 PaaS 服务的形式提供服务器后端应用,同时致力于让开发者从繁琐的后端运维工作中解放出来。
数据处理业务简介
首先是业务定义:七牛云数据处理依托于七牛云存储中的海量数据,提供零运维、高可用、高性能的数据处理服务,日处理数近百亿次,让用户轻松应对图片、音视频以及其他各类数据的实时、异步处理场景。
数据主要有三种处理方式:
- 官方数据处理:提供基础的数据处理服务,包括但不限于图片的转码、水印、原图保护、防盗链等,以及音视频的转码、切片和拼接等。
- 自定义数据处理:允许用户构建、上传自定义的私有数据处理服务,并无缝对接七牛云存储上的数据以及其他数据处理服务。
- 第三方数据处理:一个开放的应用平台,提供大量功能丰富的第三方数据处理服务,比如图片鉴黄、人脸识别、广告过滤、语言翻译、TTS 等。

图 1
图 1 是数据处理的一个调用示例。无论是七牛云的官方数据处理,还是自定义数据处理,或者第三方数据处理,都是以这种形式调用的。最左边的是一个 URL,代表一个文件,中间绿色的 Facecrop 是数据处理命令,右边的 200 × 200 是请求参数。
图 2
如图 2 所示,从左边的人物肖像图原图到右边 200 × 200 的小图片,这个服务可以把人脸从原图中剪裁出来。通过管道操作,还可以把图片再存到存储中,以后直接使用这个小图,不需要再走数据处理计算。这是一个典型的数据处理调用。
官方数据处理的挑战
第一,请求量非常大。目前,系统每天有近百亿的数据处理请求量。年底,可能会在目前近千台的计算集群基础上翻好几倍,整个存量、增量都非常大。
第二,突发流量非常频繁。很多客户是从其它云迁到七牛云,首次把大量文件迁移到七牛存储后,往往会发起大量的数据处理请求,这会带来大量突发流量。
第三,CPU 密集型计算。目前后端集群中,绝大部分的机器都是用来跑图片、音视频转码的,这些都是 CPU 密集型的计算,这意味着后台需要很多台机器,而且 CPU 的核数越多越好。
第四,IO 操作频繁。IO 分为磁盘 IO 和网络 IO,数据处理前,往往需要先把原始文件从七牛存储中下载到本地磁盘,所以磁盘 IO 和网络 IO 都很频繁。
官方数据处理的架构演化
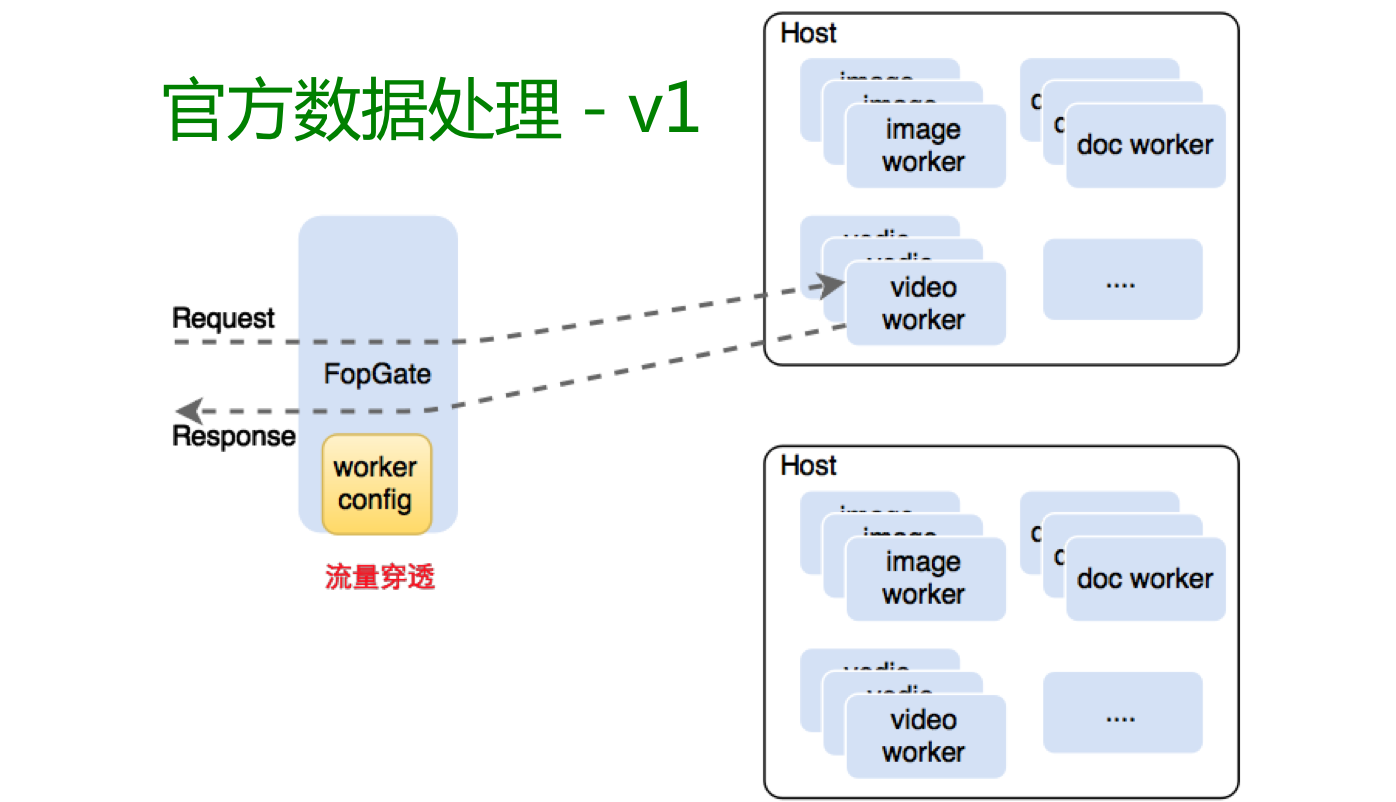
图 3
图 3 是数据处理早期的一个架构图。当时比较简单,所有请求都经过 FopGate,每个节点上都部署了很多图片、音视频或者文档处理的 Worker,是具体做转码的计算服务。整个架构,Worker 在网关上是静态配置,增加新的 Worker 时需要改网关配置重新加载,做起来会很麻烦。另外,请求进来时,对应要处理的数据也是通过网关服务进入,控制流和数据流放在一起,网关整体压力非常大,当时出了很多问题。

图 4
图 4 是数据处理目前的主体架构。右图左上角增加了一个 Discovery 组件,收集 Agent 上报的信息,Agent 和 Worker 把自己能做什么事都上报到 Discovery。每增加新的主机 Agent 和 Worker 时,不再需要静态配置,只需要指向的这个 Discovery 服务。网关可以通过 Discovery 获取信息,根据进入的具体请求,将这个请求路由到不同的 Agent ,Agent 再把请求转到 Worker 处理。Agent 组件还有负载均衡的作用,请求会选择后端相应的节点执行,另外也起到下载文件的作用。下载文件的数据流不经过网关服务,Worker 向 Agent 发起一个下载请求,然后这个 Agent 到存储上下载数据,放到自己的缓存中。
这个架构解决了一些问题,但是之前提及的挑战依然存在。主要的问题是 FopGate 在过载时依然会崩溃,每个主机会过载出问题,造成请求变慢或者宕机。接下来讨论一下如何解决这些问题。
如何应对官方数据处理的挑战
系统测量
第一,测量 FopGate 的服务能力。按照线上的配置,针对同比例缩小的集群做性能测试,测试出 FopGate 单机最大的请求数和句柄数,根据实际的业务量,确定机器配置和数量。
第二,测量某种数据处理的资源使用范式。大多数据处理是 CPU 密集型计算,我们需要找到单个处理的资源使用规律。测试方式如下:取线上约 10 万或 100 万个请求,针对一台测试机器压力测试。比如测 Image,测试这台机器的变量有以下三个:Image 实例数,并发处理数和队列长度。最终拿到的一个结果是,做图片剪裁、图片处理、图片转码等服务,一个进程一个 CPU 的逻辑核,同时处理一个任务,对它来说是最快的,多个任务同时处理反倒会让CPU 的处理变慢。
第三,测量单实例的服务能力。一个程序实现得很好,可以把多核利用起来。针对这样的实例,分配多个 CPU 线程、调大并发、并压测这个的实例,试图用 10 万个请求看整体处理速度,发现整体处理速度并没有起多个实例,但每个实例限制 CPU 线程数、限制并发好。所以最终的结论是操作系统对于 CPU 的调度,比进程要好;相比起一个大实例、接受高并发请求,我们更倾向于运行多个实例、但每个实例限制并发。
增加队列
这个主要的考虑是提高服务质量,避免单实例过载。前面得到结论,一个图片处理的实例,一个核,并发量为 1 时最快。我们为每台节点机器加了一个排队机制,排队之后不争抢资源,整体处理速度反而变快。
另外,从运营角度讲,可以用队列长度来区分免费用户和付费用户。比如,可以将免费用户的排队长度设置得长一点,比如设成 10,意味着最后一个请求要等前面 9 个请求处理完才能处理。而对于付费用户,可以将队列长度调短一点,只有 3 或者 5,这样平均等待时间就变短。总原则是区别付费用户和免费用户,免费用户保证高可用,但是不能保证高质量和低延迟,因为资源有限;对于付费用户可以保证高质量,因为可以通过排队长度控制这个事情。
限流
为什么有了队列之后还要限流?两个原因:
第一,大量长链接影响 FopGate 性能。因为七牛云处理最多的是图片、音频和视频三种请求。图片请求往往比较快,高峰期时可能几秒、几十毫秒完成,但是视频和音频转码往往比较慢,可能需要好几分钟或者好几十分钟,它取决于一个具体的转码参数和转码时长。如果不限流,网关会维持大量的长链接,累积大量句柄,轻则影响的性能,严重的情况下会造成宕机。
第二,突发流量,导致队列过长。队列太长,有大量任务积压的情况下,会有任务在处理之前就超时。与其超时,还不如直接限流,拒绝处理不掉的请求。
限流手段有三种:
第一,并发 HTTP 请求限制。超过这个限制,直接拒绝请求并返回。但这并不是最好的方式,因为超时的请求已经解析处理过,这对于性能是有一定损耗的。最好的做法是用一个信号量控制 TCP accept,比如控制信号量个数是 1 万个,1 万个请求正在并发处理时就不 accept 。这是最好的方式,但实现略复杂。
第二,单用户请求数限制。有些用户可能会在特殊情况下发起大量的请求,为了不让他影响别的用户,系统会限制单个用户的请求量。
第三,Cmd 数限制。主要指具体某个操作,比如图片查看,要对 Cmd 数进行限制。因为不能让大量同样的 Cmd 把资源消耗殆尽,影响其他 Cmd 的操作。
合理协调 IO 和 CPU
为什么要合理协调?因为数据处理的流程是:下载、写盘、处理、写盘、返回,涉及到网络 IO 和磁盘 IO。整个优化方式总原则是就近计算,将下载和计算部署在一起。目前,新的架构中是混合部署的。本来可以设计,将下载部署在其他机器上,但这样会增加一次网络的路由次数。所以,从一台机器的 Agent 下载后,直接在本机处理,不会再经过一次网络路由。另外一种方式是挂载 ramfs,直接把下载内容放在内存中。比如内存分 8 G,下载完成后直接放在内存中,要用的时候直接进内存读,这样可以节约磁盘 IO 的开销,也能整体加快单个请求处理速度。
前面这些是官方数据处理的一些挑战、架构演化以及我们采取的一些对策,后面讲一下自定义数据处理所面临的挑战。
自定义数据处理的挑战
第一,处理程序由客户提供,我们不知道客户在程序里做了什么事情,也不知道客户的程序会使用多少资源,这意味着我们至少要做两点:一是安全性,不能访问到别的资源,二是隔离性,单个程序不能无限制使用资源。
第二,业务规模不确定性,无法估算量有多大。这个带来的挑战是业务可伸缩性,需要客户可控。
基于这三个需求:安全性、隔离性、可伸缩性,Docker 非常适合这个业务场景,整个自定义数据处理在 14 年开始基于 Docker 实现。
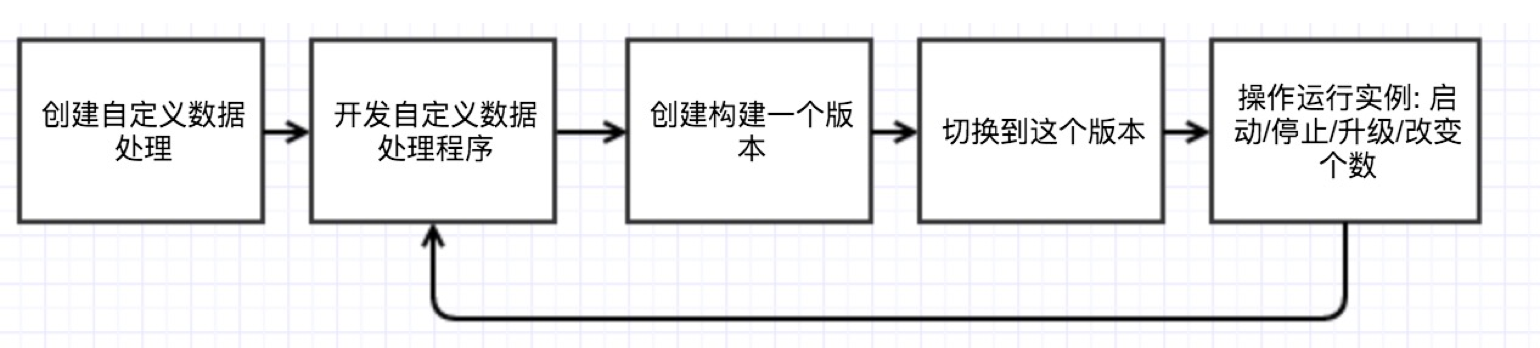
图 5
图 5 是自定义数据处理的业务流程:
第一,用户要创建一个自定义数据处理,即注册一个 UFOP。
第二,用户在本机上开发自定义数据处理程序。开发这个程序要遵循七牛 UFOP 范式。
第三,把这个程序提交一个构建版本。
第四,切换到这个版本,设置实例数。实例启动后,该 UFOP 就可以访问了。
这是迭代的,有一个箭头直接指回开发自定义数据处理程序,意味着升级程序、构建另一个新版本、切换到新版本实例的一个过程。
业务流程-注册
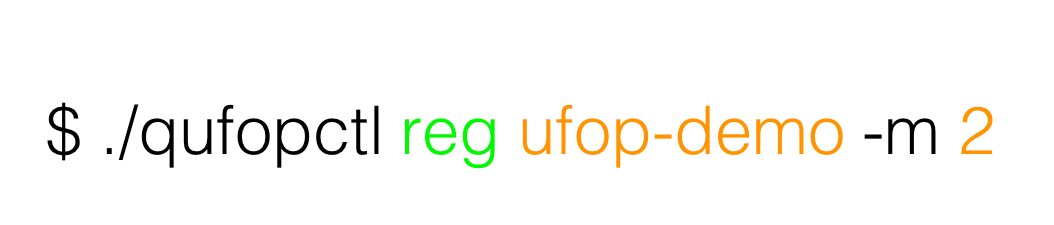
图 6
图 6 是注册的过程,第一个 qufopctl 是客户端工具,第二个是 reg 注册,第三个 ufop-demo 是名字,最后 -m 2 是模式,支持私有和公有模式。
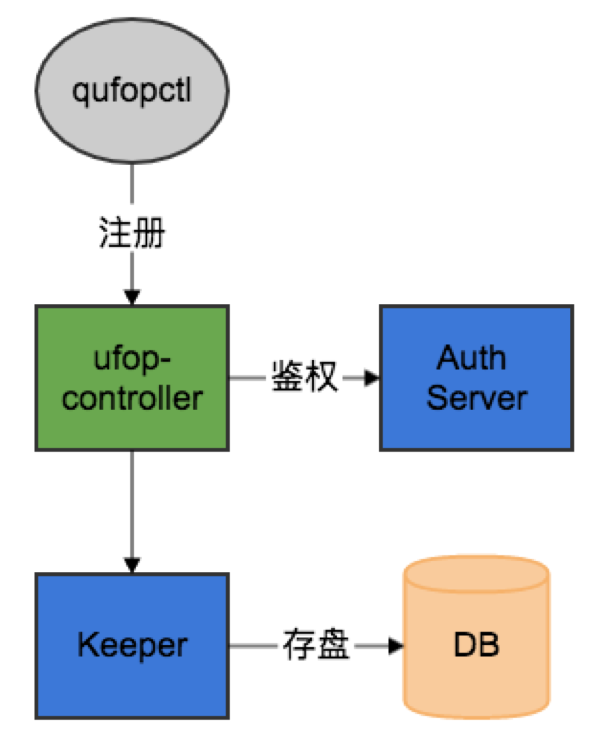
图 7
图 7 是自定义数据处理后端注册的流程,qufopctl 把前面描述的注册命令,发到 ufop-controller,它会进一步走鉴权服务,鉴权成功之后通过 Keeper 服务存盘到 DB。注册成功后,用户开始在本地实现 UFOP 应用。
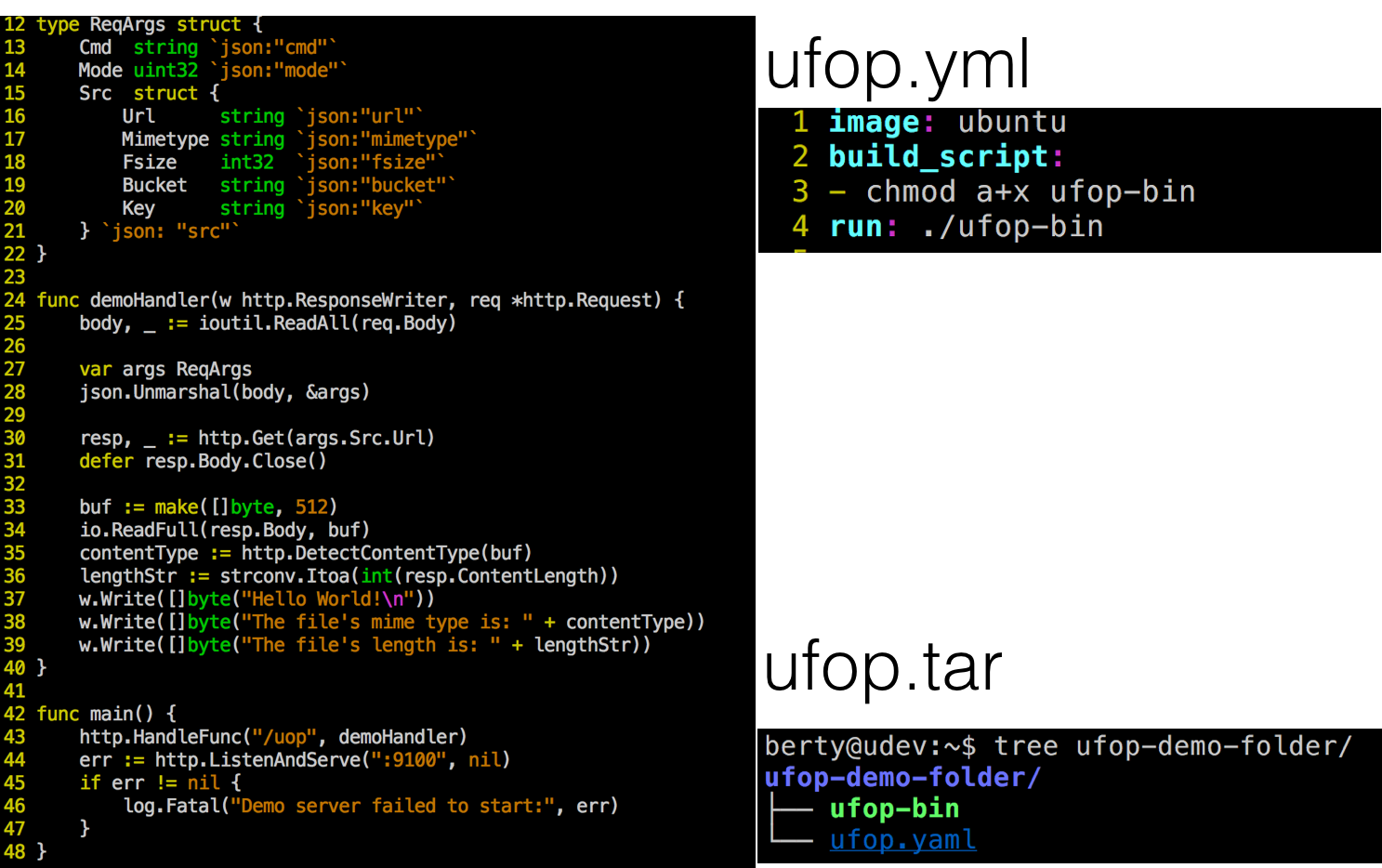
图 8
图 8 左边是一个最小的 UFOP 代码,简单来说就是在 UFOP 请求路由上加一个 UFOP 请求,拿到待处理文件 URL 后下载对应文件,然后获取文件的类型和长度,并作为结果返回。右上角是我们定义的一个描述性文件。2014 年,我们做的时候 Docker 还没有那么火,所以没有直接用 Dockerfile,而是自己定义描述模式。第一行是引用源;第二行是构建脚本,把外面的程序改成可写;第三是执行,怎么执行这个程序。右下角是要打包成 tar 包的本地目录。
业务流程-构建

图 9
如图 9 所示为构建命令,是把本地的程序上传到服务端,并构建一个版本。
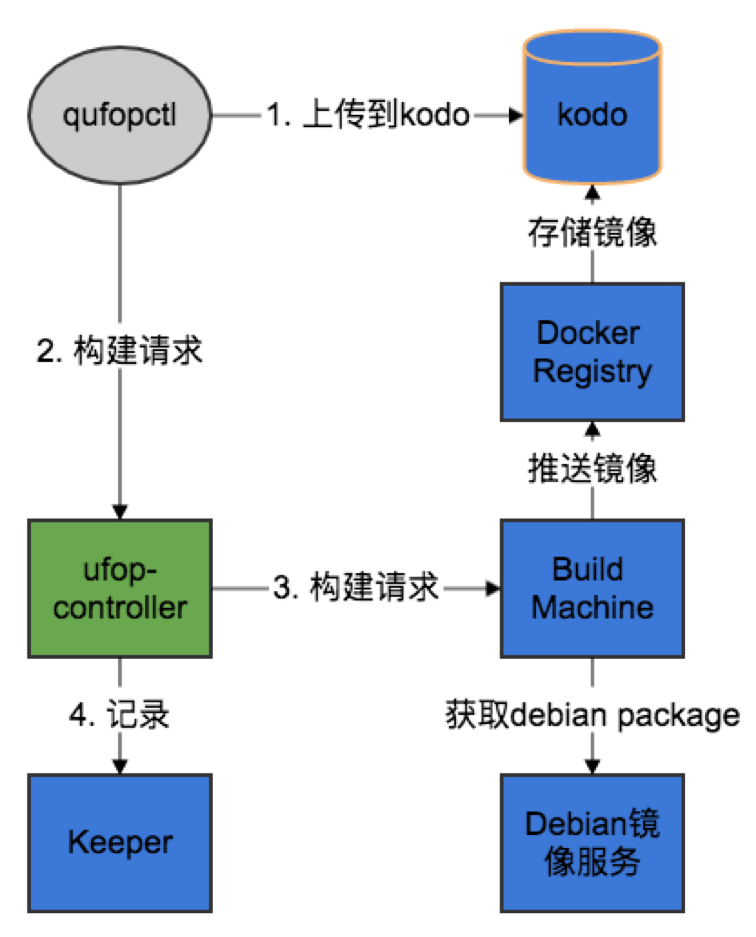
图 10
图 10 是构建的后端。整个后端的过程如下:qufopctl 把程序 tar 包上传到 Kodo,发起构建请求,再把构建请求转发到构建机器,接着把 UFOP 描述文件转化为 Dockerfile,基于 Dockerfile 构建 Docker image,最后推送到 Docker Registry。
下面是构建后端我们踩过的一些小坑。
使用 Debian 镜像服务
原先使用 AppRox,是 Debian 包下载、缓存服务,但实际上经常下载超时,而且下载出错后,自己没办法辨别本地文件存在问题,需要手动清除,比较糟糕。后来,搭建了一个镜像源。镜像源的做法是首次全量下载,全部下载完毕后,设置一个定时增量同步的时间,在凌晨,一天一次,每天更新的量只有几十兆,几分钟便可完成。从此,再也没有出现过这方面的问题。
避免 Docker 构建缓存

图 11
Docker 的构建缓存比较容易出错。图 11 第一个是错误用法:第一步,下载一个 jdk 的压缩包,第二步,创建一个目录,将压缩包解压到这个目录,并且把原来的压缩包删除。分了两条命令,但是容器其实会对每一条命令做缓存。
假如我们第一次运行这两条命令时是没有问题的。第二次运行时,我们觉得第二条命令中 OPT 目录不好,想到另外一个目录,于是对第二条语句做了更改,那么就会出问题。为什么?因为第一条命令没有任何变化,所以容器构建系统认为,没有任何的变化就不去执行,于是直接跑第二条命令,第二条在前一次执行时,已经将压缩包删除,因此会跑失败。这种错误很容易犯,解决方法是把压缩包的下载、目录的创建、解压缩和删除压缩包,都放在同一条命令里。当这条命令被修改后,每次都会重新执行,就不会出现这个问题了。
调整实例数

图 12
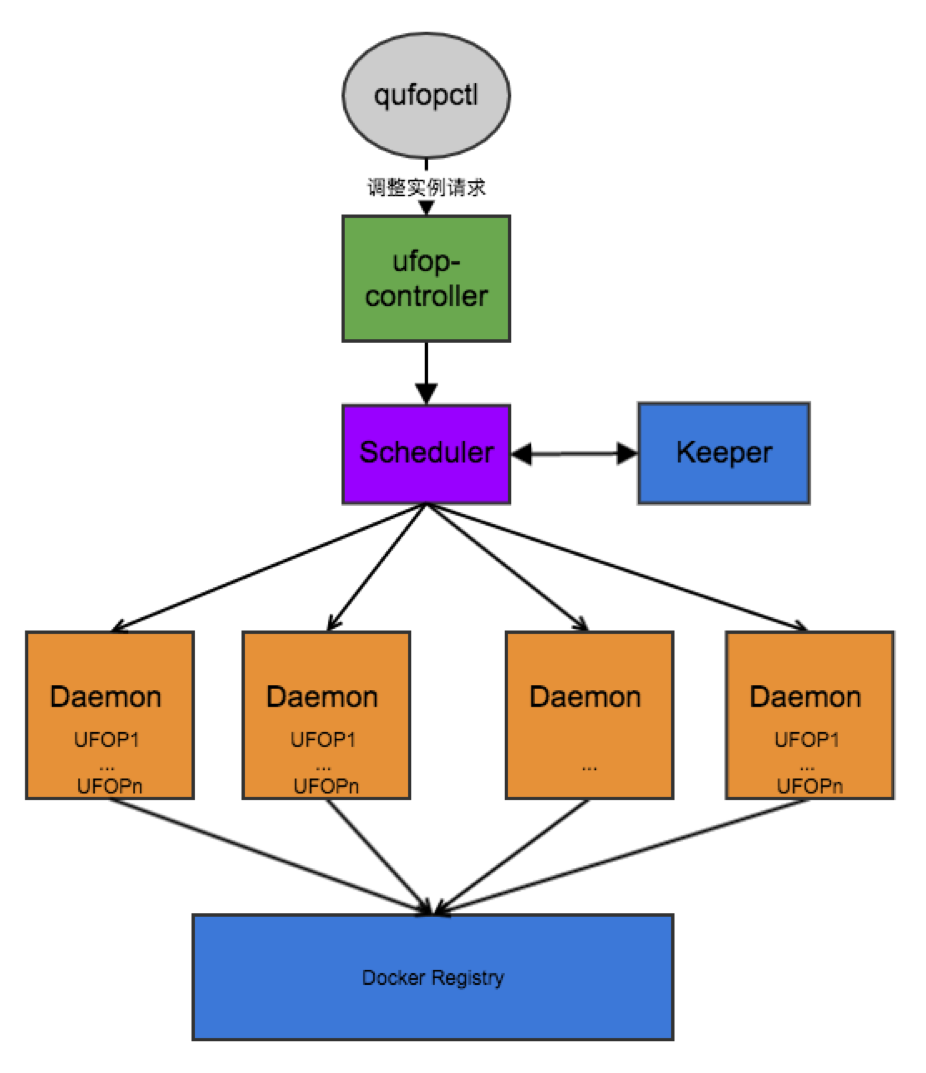
图 13
接下来是调整实例数,前面已经构建完成,程序已经上传到服务器端。qufopctl resize ufop-demo -n 3,这条命令会增加 3 个实例。
整个后端的过程如图 13 所示,qufopclt 发送请求到 ufop-controller,中心调度器 Scheduler 下面有很多个 node,运行着我们实现的 Daemon 服务,所有容器都是由 scheduler 下发给某个 Daemon,这些 Daemon 启动对应的容器。Daemon 会把所在机器剩余资源的情况,包括CPU、内存和磁盘,实时报给 Scheduler,Scheduler 会根据实例的规格要求、找到相应满足要求的 node。这些容器实例创建成功后,Daemon 会把具体的端口信息返回到 Scheduler,Scheduler 再通过 Keeper 服务持久化,这样就结束了。 Docker Registry 是 Docker 的镜像仓库。
升级实例
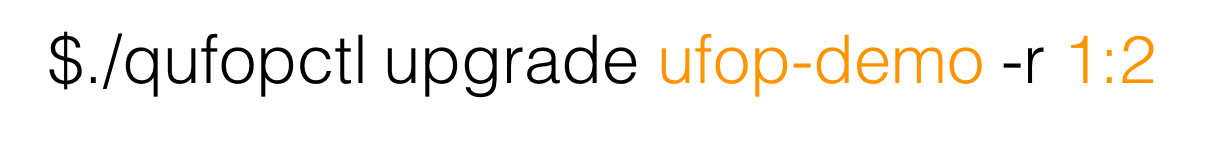
图 14
到前面这一步,UFOP 已经运行起来并且可以使用,如图 14 所示为升级实例的过程。我们有一个 Upgrade 的命令,-r 是一个实例,现在要做的是升级前两个实例,后端会发生什么事情呢?
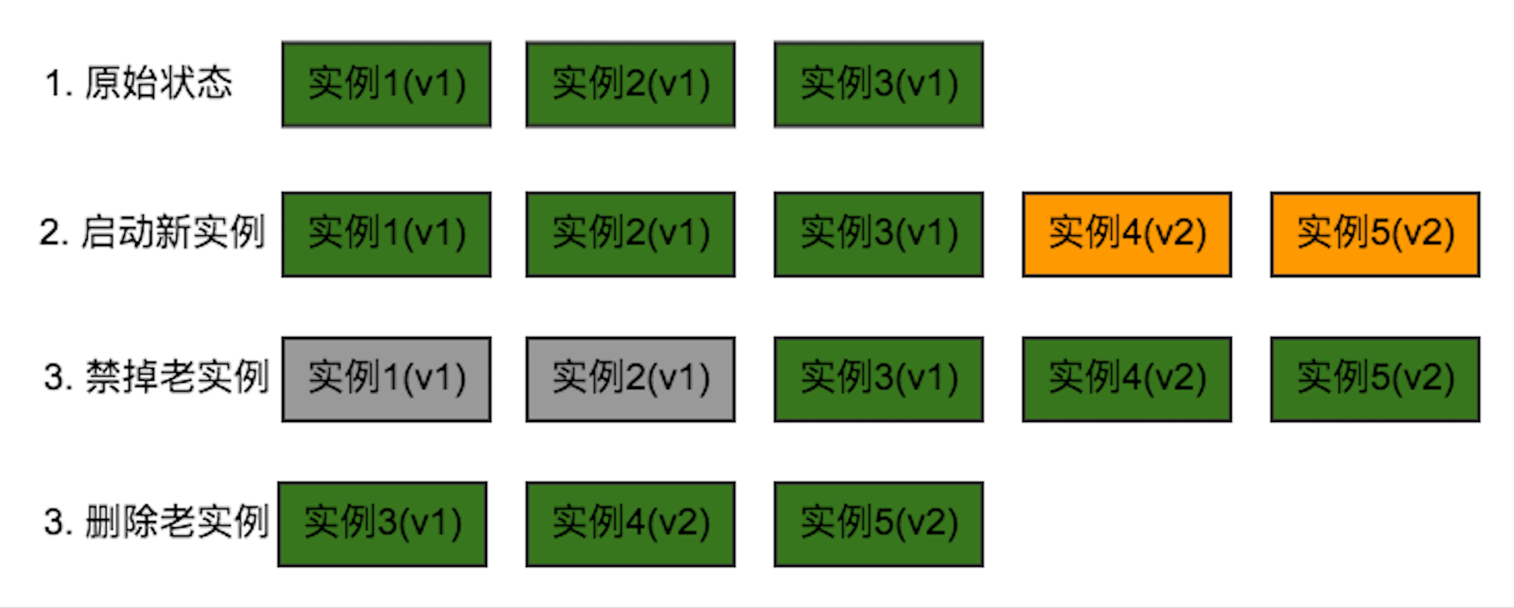
图 15
图 15 所示为一个灰度升级阶段。首先原始阶段有三个实例,假设每个版本都是 V1,现在要升级两个实例,后端的做法是增加两个实例,实例 4 和实例 5,这两个对应的版本是 V2,图 15 中橙色部分。等 V4 和 V5 彻底被启动后,我们将老的实例删除,它的结果是原来的一个 V1, 两个 V2,整体灰度升级过程就是这样子。
有些细节值得注意:
第一,新实例 WarmUp,往往刚开始很多内部组件没有初始化,像内存池、线程池、连接池需要初始化,所以初始请求处理得往往比较慢,但是又不能不发请求,因为不发请求永远热不起来。做法是设定预热时间段,定时间段的权重,保证在这个时间段预热好之后就承担正常的流量。
第二,老实例 CoolDown。如果直接删除老实例,对服务的可用性没有影响,因为老的请求正在被处理。做法是:使用 Docker StopWait,当用 Docker Stop 停止一个容器时,它默认的行为是先发一个 SIGTERM,如果不指定 StopWait 时间,就会马上发一个 SIGKILL 信号,这样你的容器将被直接杀死。若一个容器正在处理请求,那么我们希望能有一段时间让我们将请求处理完后,优雅的关闭,否则会影响可用性。所以使用这个命令时,可以设置 StopWait 时间,若等待超过设置的时间,却发现容器没有优雅关闭,再发 SIGKILL 信号。另外在业务层面,老实例在 CoolDown 时,应该设成一个关闭中的状态,避免新的请求再打进去。
第三,保留足够的计算冗余。这个是如何考虑的呢?因为升级需要考虑步长,如果升级的步长大于计算的冗余实例数,意味着剩余的等待实例会承担更多的请求,多于预期的请求会影响服务的质量,因为请求的时间会变长。所以选用的升级步长应该小于冗余的实例数。
数据流

图 16
刚才讲的是控制流,包括如何注册、如何创建一个新的实例。而这些数据流的请求过来是什么样的?这涉及到一些内部组件,即云存储的服务器。服务器后面有数据处理,自定义数据处理会从之前说的状态服务中获取某一个后端实例列表,由它做负载均衡传给后端。在后端数据流的维度上,每台机器还有一个 Fetcher,它接收到请求后会把请求路由到本机,并执行实例。同时,它会做数据下载的工作,我们出于对用户隐私安全的考虑做了一些混淆,不允许他直接下载,而是转化成本地的。这是数据流的流程。右边有一个组件叫 DiskCache,是一个缓存集群。
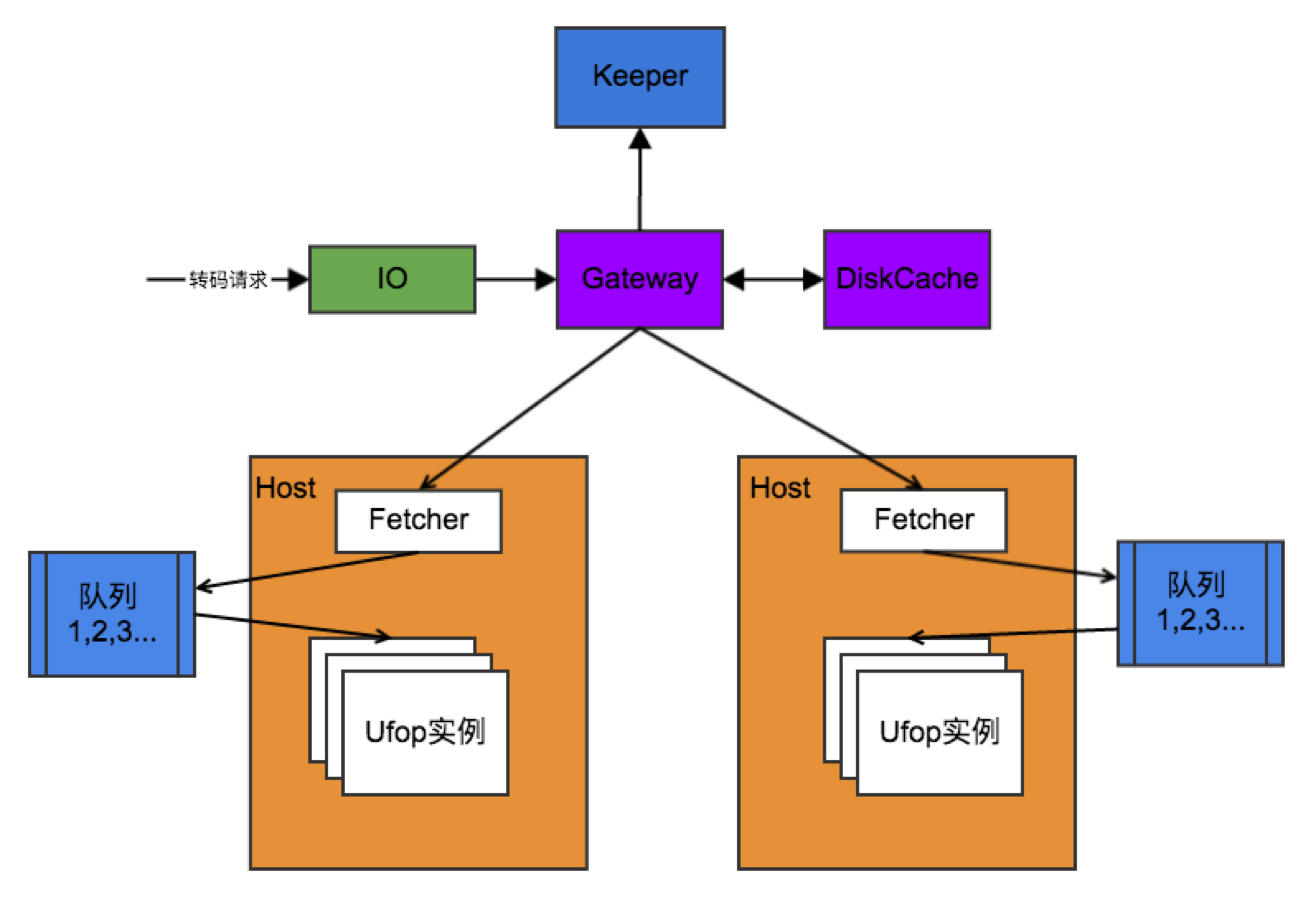
图 17
图 17 是数据链路的 V2 版本,是一个思路,还没有完全实现。唯一的改动是在实例之间加了一个队列,当然这个队列是可选的。当前所有请求都放在这个队列中,由 UFOP 实例获取请求,处理完成后将结果返回,这是一步处理的过程。这个队列有什么作用?前面提到,调整实例可以做手动伸缩,没有说自动伸缩。而这个队列可以做自动伸缩。
自动伸缩设置
自动伸缩需要用户做一些配置,一个是默认的实例数,也就是第一次用户上传一个自定义数据处理的版本,上传完成后调整实例数,调整成 10 个,还要设置一个平均单实例待处理任务数的配置,假如,这个设置是 10,当队列里面有小于 100 个待处理任务数时是不需要伸缩的,但是当队列里面的任务数大于 100,比如到 110 就要伸缩了,因为单个实例平均待处理的任务数已经超过,这个时候再增加一个实例是最适合的选择。通过对队列的监控,可以达到自动伸缩。
自动伸缩的后端

图 18
图 18 是自动伸缩的后端。最上面中间有一个 Scaler 组件,会实时监控队列长度,拿到每个队列的配置,即平均单任务待处理任务数。它根据这两个信息,可以实时地发出调整实例的请求,比如平均单任务处理数超过预想时,它可以自动增加一个实例,并告诉调度器,调度器会找相应的节点启动实例,启动后告诉 Keeper,Keeper 会把这些信息记录下来。回到前面的数据流,及时从里面获取信息,达到自动伸缩的目的。
如何应对自定义数据处理的挑战
解决方案:
第一,安全性。这一部分做法比较简单。自定义数据处理单个物理机上的容器数约几十个,这与 CPU 的核数有关。可以设置某个范围的端口不互访,以达到容器不能互访的目的,从而获得安全性。
第二,隔离性。可以限定某一个容器只用指定配额的 CPU 和内存,这取决于用户的配置。
第三,可伸缩性。首先实现了一个简单高效的容器调度系统,它是支持秒级伸缩的;其次是暴露伸缩 API ,用户可以手动伸缩达到伸缩目的;最后是利用队列长度,达到自动伸缩的目的。
视频实录:《自定义数据处理平台的容器化实践》:http://v.qq.com/x/page/c03150up4cm.html

「七牛架构师实践日」——这里只谈架构 七牛架构师实践日是由七牛云发起的线下技术沙龙活动,联合业内资深技术大牛以及各大巨头公司和创业品牌的优秀架构师,致力于为业内开发者、架构师和决策者提供最前沿、最有深度的技术交流平台,帮助大家知悉技术动态,学习经验成果。
七牛架构师实践日第十期【泛娱乐+直播 技术最佳实践】将于 7 月 31 日与大家在 上海 见面,目前活动正在火热报名中,点击此处了解更多信息,期待你的参与。

 );){kind=link}