KubeCon 欧洲大会热点议题总汇
| 2017-05-03 17:39 收藏: 1
4 月 22 日,由 K8S 技术社区、Linux 中国联合主办的 K8S GeekGathering 2017 吸引了国内容器领域关注者 100+ 人到场参与,以下是 EasyStack 容器架构师王后明的演讲实录整理:
大家下午好,开场之前,我做一个简单的现场调查,有哪位朋友在生产环境上或者使用 K8S 平台的,大家可以举手。生产环境或者在运维,或者在生产上使用的,开发和测试环境上用的多一些。
今天的话题,我主要是对 KubeCon 2017 欧洲峰会的热门话题的总结和社区关注的的分享和回顾,说到现场的,对我印象最深的是其中某个话题的时候,现场调查的时候,问有谁,哪位同事在生产环境上运维 K8S 平台,在现场可以看到超过 80% 的人举手,我感觉在 K8S 平台,在国外的使用程度,可能比国内走得更前一步,已经有非常非常多的生产案例在跑。
1、CNCF最新动态
首先分享第一个问题是 CNCF 的最新动态,在两天的会议上,CNCF 宣布了社区发展的最新情况,就是在加入黄金和会员后,CNCF 已经增加到 85 家的会员的数量,生态发展速度非常快,托管项目,目前从峰会上,3月25日, Docker 把容器运营时捐赠给了容器的基金会,进入基金会以后,CNCF 托管的项目目前一共有 9 个,包括 K8S 、等等,目前一共 9 个托管的项目,但同时,因为在这个图里面,CNCF 进行了维护,相当于整个企业在云里面做运用改造,可能涉及到非常多的项目,包括整个技术架构,项目的安装部署,容器的编排,应用的开发和部署的流程,整个其实涉及到非常非常多的开源的项目,来支撑云应用层的生态,目前 CNCF 基金会管理 9 个项目,更多项目进入基金会的视野,将来会有更多项目进入 CNCF 下托管,这是 CNCF 社区的情况。

峰会上一个比较重要的消息就是说 Docker 把自己的容器运营时捐赠给了 CNCF 和基金会。我们知道在 K8S 1.5 版本的时候,他已经脱离多个运行的CII容器,Container 的接口,有这个接口之后, K8S 可以绕过 Docker 使用基金会的实现,做容器的编排,在 1.5 发布之后, Docker 的话,多少也能够感觉到一些压力,因为如果 K8S 一个 CII+OCI 标准运行成为事实以后, Docker 的市场占有率会有所下降,今年峰会的时候, Docker 选择把 ContainerD 捐赠给基金会,这是自己的容器运营时,主要解决下面几个问题,比如说它怎么样,第一个部分是进行容器竞相的格式的管理,怎么样把分层的镜像,进行运行时,同时会管理底层的存储和网络,怎么样去分配,就是容器运行时要做的事情,容器 ContainerD 的话,主要是结合 Docker 的产品,结合微软的共同开发了开源的容器运行时的平台,这是 ContainerD 要解决的问题。
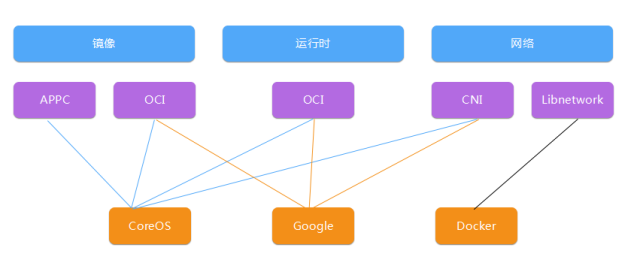
说到 OCI 和这些标准,我们可以简单看一下,目前这个容器的生态里面所存的几个,标准化的一个组织,首先从镜像运行时和网络方面都有不同的标准化组织来规范容器的生态,CoreOS 是 APPC 和 OCI 和 CNI,谷歌是 OCI 和 CNI, Docker 自己推的 Liwork,1.5 版本里面,怎么调动不同的容器运行时的接口,1.5 开始是这个状态,避免直接使用,直接调用下面的,比如 Docker 和这样的容器的实现,就是形成统一的容器运行时的接口,底下不同的实现是通过不同的接口调度容器,如果一个公司企业里面来选择一个容器的编排的工具,选择 K8S 是底层的容器引擎没有硬性的要求,这样可以更好地避免底层技术厂商锁定的问题。
其实在峰会上,分享了他为什么选择把 ContainerD 捐赠给基金会,主要是两个大的方面,一个是大家也是立志于形成整个容器生态的统一的规范,避免说大家各自玩自己的一套规范。这样也是给整个生态的开发者和厂商都会带来一些兼容性的问题,选择 CNCF 基金会,是因为两者目标一致,形成统一的容器生态的规范,然后技术实现方面的话,ContainerD 是直接使用 GRPC 的调动的关系,监控数据也是使用普罗米修斯的方式发布,这样可以更好地跟 K8S 更好地融合。其实 ContainerD 进入 CNCF 以后,代替 Docker 的地位,在社区已经有针对 ContainerD 和 CNCF 接口的实现,直接调用 CII 的调用 Containerd 的技术实现也跟 CNCF 其他项目保持一致,做下面容器的盛行周期的管理,这个就是 Containerd 的为什么捐赠给 CNCF 基金会的说明。
2、峰会上的技术热点总汇

接下来我们可以看一下整个峰会上所讲述的一些比较重要的和比较新的技术话题,我们看到第一点是 KubeVirt ,我们目前用得比较多的是,IaaS 层里面, Open Stack 比较多,容器的话 K8S 比较大, KubeVirt 的实现方法有两种,对 Open Stack 平台里面,从 Open Stack 平台上,完成对虚拟化和容器技术的统一调度, KubeVirt 目的是做容器和虚拟机的统一调度,实现方式是把 K8S 作为容器的控制平面,评比容器的差异,让整个 K8S 调度数据中心的虚拟化和容器的技术。
现场的话,工程师也给大家做了说明,怎么样实时创建虚拟机,同时怎么管理虚拟机的生命周期, KubeVirt 的实现的话,实现方式,和 K8S 目前三方的,如果我们要新增功能,在 K8S 里面新增一些功能加一些资源,是类似的方案在 K8S 里面,是不会直接改这个 Server,会扩展一套新的,会有一套新的管理者响应新的资源,因为整个平台是在 K8S 框架下,所以这两个下面的统一资源管理是通过 TBR 统一管理、调度三方资源,把三方的服务定义为统一的实现,具体的他们新加了一个 API Server,通过新的资源的描述类型,来定义这个虚拟机的资源,我们响应虚拟机类型的资源,把资源真正的请求分发到底层运行在每个节点上的资源,这样的话,来完成整个用 K8S 平台对虚拟机和容器做统一的调度。
这是 KubeVirt 的大概介绍。这个项目的话,目前它还没有到特别成熟的阶段,目前是相当于原型的阶段,来证明这种方式,如果我们想用 K8S 作为统一的虚拟机和容器的管理平台也是可行的。这是关于容器和虚拟化,它俩统一管理,作为统一的控制平面的实现方式之一,除了 KubeVirt 之外,其实整个当前 K8S 生态上面,其实也有另外一些实现容器和虚拟机调度管理的思路,第一种是 Virtlet,让虚拟机和容器统一管理,和 KubeVirt 相似,Virtlet 沿用现有的资源和框架,做两者统一的资源的调度,现在已经进入统一项目下面,大家可以自己做一些尝试。
另外一种是 Frakti 也是一个项目,跟郭理靖分享的京东云的相似,底层其实用来真正跑容器运行时,其实还是虚拟化的技术,只是把虚拟化和容器进行了深度的融合,底层的容器运行时还是虚拟化的技术。主要是用的 hypervisor 控制的。 Open Stack 这边其实也是另外一种实现思路,就是在 Open Stack 和虚拟机统一管理,这是另外的话题,这边我们就不说这部分了,这是容器和虚拟机统一管理的方案。接下来我们可以看一下对 Open Service API 以及 K8S Service Catalog。
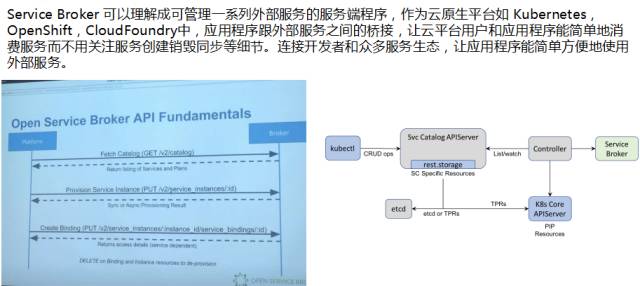
我们如果用某一个平台之外的服务,我们要做的事情非常简单,第一步要获取这个服务提供商可以提供哪些服务,比如从这上面可以提供服务,有这个服务能力之后,我们第二步直接向服务提供商提供具体的数据出来。把创建出来的数据库和底层的某个应用进行绑定,绑定好之后,我们应用可以更方便用,往数据库里写入数据存储数据,这样的话,我们使用这些服务的时候,并不需要关注具体的细节,这是提供给我们的桥梁,让整个生态应用之间,使用、分发更方便。这个就是 Open Service Broke API 做的事情,对应的,类似于 KubeVirt ,是插件格式加入整个平台里面,相当于整个的实现,让 K8S 里面的服务更好地使用数据库提供的原理,这个也是和刚才类似,也是通过三方的资源来实现,目前也是孵化项目,可以做一些使用。
在目前的审计,在生产的系统里面是非常重要的组成部分,按照时间顺序记录用户,管理员或者其他组建,跟安全相关的行为,审计的话,可以给系统管理员提供,对安全行为的审计,过程中需要回答的几个问题,比如这个用户做了什么操作,操作是什么时候发生,由谁发起,对谁发起,它发起的目标是什么,它在哪里被观察到,哪里被发起,会影响哪些地方。这是整个审计过程中需要的信息,其实在整个审计的系统里面都应该能囊括到,主要是用来发现系统的安全违规行为,做性能分析、软件 BUG 的分析,调试的工具,这是审计系统要完成的功能,审计系统,并不会给系统带来额外的安全性,主要是以 K8S 审计为例,Virtlet在 Open Service 之后的行为,是已认证用户的行为的记录。这是审计系统的定位,只能说作为我们感应系统安全的一个参数信息的来源,这是审计系统。
那审计系统在 K8S 里面,目前功能比较简单,你在审计的时候,加几个选项就能把审计系统打开,打开之后,我们可以从日志里面看到,我们系统的用户和管理员做的认证的操作,当前的日志的记录,目前是比较简单的状态,刚开始有这么一个系统,可以来作为系统 K8S 审计的信息的输出,这是审计的在 K8S 的状态,然后另外一个就是别的工程师分享了, K8S 里面无服务框架的项目,其实跟容器也是相当于目前像公有云里面,AWS,谷歌、微软,都有自己的无服务框架的产品,在 K8S 里面,也有不少的尝试的实现, K8S 的话,也是跟 KubeVirt 类似,也是用TBR作为函数,操作的具体的展现的对象,同时也是新加了一个响应函数的请求,最底层的话,无服务器请求,并不是没有最后的服务器的门第,是通过最底层的 K8S 的基础资源来响应函数后面的资源的运算的请求,同时相关的一些配置,是通过 map 做的。这是 K8S 的实现,同时通过插件化的方式加入整个 K8S 的平台里面来的。

除了 K8S 之外,也有这样的框架。底层也是利用 Kubeless 是兼容谷歌的 API。另外还有分享的容器初始化系统的,因为 Linux 内核启动的时候会先启动一个 init 进程,这个进程的 PID 开始 hypervisor 于特殊的使命,需要做好的父进程的角色,比如传递信号,容器使用PID隔离不同容器里面进程的,带到这个问题就是每个容器里面都能看到这么一个进程,这个进程因为Linux 设立的是唯一的进程有使命,处理这个子进程的关系,在 init 为 1 的进程就变得重要了,早期如果运维过生产环境, Docker 或多或少遇到,容器某个进程怎么样,其实这种情况下,就是跟容器初始化进程关系比较大,因为 PID 为 1 的进程比较关键。
所以对应实现的话,有三种实现的方式,第一种是 dumb init,系统起来的时候,如果我们在某个容器件里面使用这个的话,我们首先要启动真正的应用,这个 dumb init 是完成了容器初始化的工作,真正的是作为 dumb init 的子进程,不会因为没有处理进程化,导致进程上不掉的情况,所以 dumb init 是比较轻量级的实现方式。另外从 Docker 1.13版本之后, Dockerd 已经加了这种标记, Dockerd 会自动会用户的应用程序处理初始化的工作,所以从新版本的话,我们遇到这种进程相对少一些了。这是 Docker 这边的实现。第三种方式是可以通过 Systemd,同时我们在容器里面的话,也可以选择用 Systemd 充当内部的初始化的进程,这个好处是除了做容器初始化系统之外,还能更多处理日志,服务之间的启动顺序,这是它带来的好处,这是容器初始化系统,大家做应用容器的时候,如果遇到类似的问题,可以选择三种不同的方式,用哪种方式解决可能存在的问题。
3、与生产实践相关的技术话题
最后一部分跟大家分享一下,我所听到的这些里面跟生产应用关系比较大的,对我印象深刻的几个话题,其中之一是 helm ,我大概普及一下,简单理解可以理解成应用系统里的一个,其实就是,目的是让 K8S 里面的一个应用,它使用和维护升级更加方便。我们知道。如果我们单跑一个容器其实非常方便,我们直接进行单个容器的使用、启动、删除就可以。如果真正的一个系统做完微服务化,整个大系统不可能是单个的容器,容器之间或多或少存在跟其他系统之间微服务的交互关系,这个时候,把各个大系统里面子系统的依赖关系交代清楚,这个是非常重要的。 helm 的出现是为了解决大系统进行容器应用化之后,在线上运维的所做的事情,相当于我们把每个小的服务定义好之后,以 helm 里面的定义好,一个应用的话,可以包括多个微服务,一个 helm 可以理解为一个ITE,相当于一个大应用之间,它的依赖关系可以通过一个管理起来,这是 helm 做的事情。
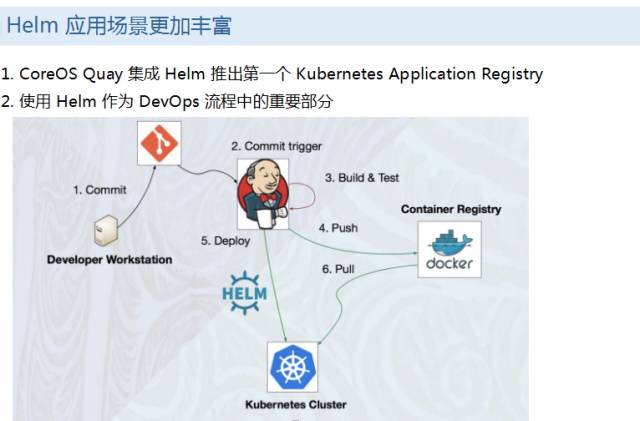
K8S 生态里面的一个应用包的管理工具。 helm 的内部组成相对简单, helm 自己是一个客户端,你自己执行的样本、app 这些,你可以自己设定对应的应用,运营的名字是,客户端发起请求以后,响应完以后,服务器上把这个应用的描述先描述的压缩文件下载到 K8S 集群里面,度曲这些信息,部署组件, helm 的话,在整个企业里面,其实它的重要性越来越重要,其中第一点是 CTO 分享了,第一个 K8S 里面的,我们目前只有 Docker ,这只是单个容器的,有了 helm 之后,我们可以把标准的应用,不仅仅是我们可以用容器生态来管理好一个容器,更方便的是我们把标准应用通过应用的方式管理和发布,quay 集成 helm ,类似于应用商店,quay 和容器的仓库融合得比较紧密,在整个微服务过程中,除了能把整个 image 之外,同时可以推送到应用的里面去,这样能达到整个应用方面的运维和管理。这是这个产品。
第二部分,其实 helm 可以作为整个流程的重要部分,其实整个企业做应用容器化的时候,少不了代码提交、触发、流程之后,把对应的应用推送到容器里面去,有了 helm 之后,我们可以做的事情还有很多,一个大的服务分为三个应用,如果我们三个应用事先定义好应用的组织关系,这个时候,如果我们每次应用的代码提交,其实都会带动整个线上的大系统做整体的更新和测试,这样不仅是对某个服务本身做一个测试,其实可以对多个服务大系统做大的过程,这是 helm 在企业里面应用更丰富,重要性,后面会越来越重要。包括国内国外,越来越多的平台和产品已经支持用 helm 作应用商店的方式。最后一个部分就是分享一下华为工程师的分享,如何让 K8S 支持 5 万+个服务。在1.6发布的时候,官方宣称, K8S 可以支持5千个物理节点,如果真正开始规模化地使用这么一些应用的时候。
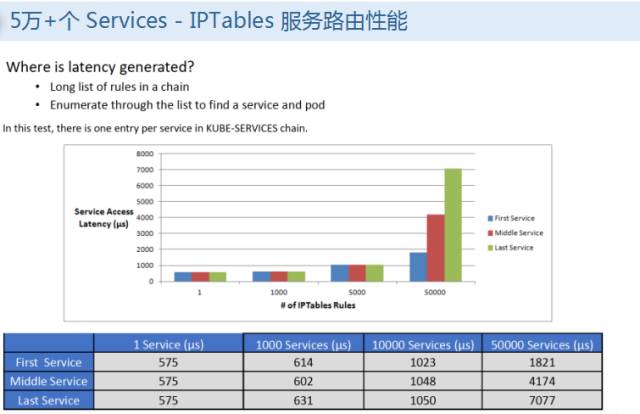
如果规模上去之后,会遇到一些问题,因为服务的话,都是通过 IP 做流量的负载,对整个副本,决定你这个应用最后到哪个访问的时候,它流量在那个 pot 上面,是通过 IPTables 的规则,可以看到整个系统规则里面一些 IPTables 规则的增加,你的数量上来之后,会成倍的增加,iptables 达到一定程度会造成反应延迟非常大,这个时候对 IPTables 做一些删除修改的话,整个延迟非常大,为什么慢,是因为 IPTables 不是增量做规则的增加,如果当前有服务出来,后面要新创建一个服务,这些规则是要把当前所有规则拷贝出来做修改,再把这个规则 save 回去,把整个规则做一个更新,这个过程会导致 IPTables 锁住,如果规则非常大,会非常耗时,有个具体的数据是如果有 5 千个 servies 的时候,IPTables 有四万条,添加一条规则耗时 11 分钟才能把这条规则在系统上生效,这是绝大的耗时,有 16 万条规则,需要耗时 5 小时。在生产里面可以理解为不可用的状态了。IPTables 作为内部使用,存在的问题。这是服务延迟的问题,就是你请求到节点之后,分发到哪一步了的延迟,第一个服务和最后一个服务之间,到哪个之间的间隔,这是比较显著的变化了。面对 IPTables 存在的问题,社区有方案,用 IPVS 代替当前kube proxy,基于 Netfilter 之上的协议。
目前通过 NAT 负载均衡模式,支持更高级的,直接路由的方式,目前 K8S 使用 NAT 的实现,这种实现的话,目前代码还是在,如果五千规则需要耗 11 分钟,现在降到2秒,之前需要5小时,也只需要 2 秒,这样的话,可以解决这样的问题。这是如何用 IPVS 支持 5 万级别的 service,这是性能数据的对比,在5千个数据的时候,之前需要 11 分钟,如果 2 万个服务的话,需要 5 小时,用 IPVS,可以很小,这样的话能够很好地支撑整个大的应用的,大规模的应用的分发,大规模应用的运行。以上就是我在峰会上听到的比较多的热门的技术话题的简单分享,涉及到的问题比较多,大家有问题的话,这只是影子,告诉大家有这个东西,后面要用的话,可以从社区上,或者网络上找到更丰富的资源和介绍,我的分享就到这儿,谢谢大家。
全程 PPT 下载
下载 K8S GeekGathering 2017 全程演讲 PPT:https://pan.baidu.com/share/link?shareid=3448394954&uk=3289666732#list/path=%2F
提取码:5t57

 );){kind=link}