GitHub 的 MySQL 基础架构自动化测试
| 2017-10-03 12:10 收藏: 2
我们 MySQL 数据库基础架构是 Github 关键组件。 MySQL 提供 Github.com、 GitHub 的 API 和验证等等的服务。每一次的 git 请求都以某种方式触及 MySQL。我们的任务是保持数据的可用性,并保持其完整性。即使我们 MySQL 集群是按流量分配的,但是我们还是需要执行深度清理、即时更新、在线模式迁移、集群拓扑重构、连接池化和负载平衡等任务。 我们建有基础架构来自动化测试这些操作,在这篇文章中,我们将分享几个例子,来说明我们是如何通过持续测试打造我们的基础架构的。这是让我们一梦到天亮的根本保障。
备份
没有比备份数据更重要的了,如果您没有备份数据库,在它出事前这可能并不是什么问题。Percona 的 Xtrabackup 是我们一直用来完整备份 MySQL 数据库的工具。如果有专门需要备份的数据,我们就会备份到另一个专门备份数据的服务器上。
除了完整的二进制备份外,我们每天还会多次运行逻辑备份。这些备份数据可以让我们的工程师获取到最新的数据副本。有时候,他们希望从表中获取一整套数据,以便他们可以在一个生产级规模的表上测试索引的修改,或查看特定时间以来的数据。Hubot 可以让我们恢复备份的表,并且当表准备好使用时会通知我们。
tomkrouper
.mysql backup-list locations
Hubot
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
| ...
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
tomkrouper
.mysql restore 1699133
Hubot
A restore job has been created for the backup job 1699133. You will be notified in #database-ops when the restore is complete.
Hubot
@tomkrouper: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
数据被加载到非生产环境的数据库,该数据库可供请求该次恢复的工程师访问。
我们保留数据的“备份”的最后一个方法是使用延迟副本。这与其说是备份,不如说是保护。对于每个生产集群,我们有一个延迟 4 个小时复制的主机。如果运行了一个不该运行的请求,我们可以在 chatops 中运行 mysql panic 。这将导致我们所有的延迟副本立即停止复制。这也将给值班 DBA 发送消息。从而我们可以使用延迟副本来验证是否有问题,并快速前进到二进制日志的错误发生之前的位置。然后,我们可以将此数据恢复到主服务器,从而恢复数据到该时间点。
备份固然好,但如果发生了一些未知或未捕获的错误破坏它们,它们就没有价值了。让脚本恢复备份的好处是它允许我们通过 cron 自动执行备份验证。我们为每个集群设置了一个专用的主机,用于运行最新备份的恢复。这样可以确保备份运行正常,并且我们能够从备份中检索数据。
根据数据集大小,我们每天运行几次恢复。恢复的服务器被加入到复制工作流,并通过复制保持数据更新。这测试不仅让我们得到了可恢复的备份,而且也让我们得以正确地确定备份的时间点,并且可以从该时间点进一步应用更改。如果恢复过程中出现问题,我们会收到通知。
我们还追踪恢复所需的时间,所以我们知道在紧急情况下建立新的副本或还原需要多长时间。
以下是由 Hubot 在我们的机器人聊天室中输出的自动恢复过程。
Hubot
gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
gh-mysql-backup-restore: db-mysql-0752: Starting replication
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
还有一件我们可以使用备份做的事情是向一组现有的 MySQL 服务器添加一个新的副本。我们初始化一个新的服务器,一旦我们得知它准备就绪,我们就可以开始恢复该特定集群的最新备份。我们有一个脚本,可以运行所有需要手动执行的恢复命令。我们的自动恢复系统基本上使用的是相同的脚本。这简化了系统构建过程,并允许我们在一个启动运行的主机上使用几个对话命令(chatops)来替代一堆手动执行命令。下面显示的是在该对话(chatops)中手动执行的恢复:
jessbreckenridge
.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
Hubot
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Update file ownership
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting up replication
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting replication
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
故障转移
我们使用协调器 来为主服务器和中间服务器执行自动化故障切换。我们期望协调器能够正确检测主服务器故障,指定一个副本进行晋升,在所指定的副本下修复拓扑,完成晋升。我们预期 VIP(虚拟 IP)、连接池可以相应地进行变化、客户端进行重连、puppet 在晋升后的主服务器上运行基本组件等等。故障转移是一项复杂的任务,涉及到我们基础架构的许多方面。
为了建立对我们的故障转移的信赖,我们建立了一个类生产环境的测试集群,并且我们不断地崩溃它来观察故障转移情况。
这个类生产环境的测试集群是一套复制环境,与我们的生产集群的各个方面都相同:硬件类型、操作系统、MySQL 版本、网络环境、VIP、puppet 配置、haproxy 设置 等。与生产集群唯一不同的是它不发送/接收生产流量。
我们在测试集群上模拟写入负载,同时避免复制滞后。写入负载不会太大,但是有一些有意地写入相同数据集的竞争请求。这在正常情况下并不是很有用,但是事实证明这在故障转移中是有用的,我们将会稍后简要描述它。
我们的测试集群有来自三个数据中心的典型的服务器。我们希望故障转移能够从同一个数据中心内晋升替代副本。我们希望在这样的限制下尽可能多地恢复副本。我们要求尽可能地实现这两者。协调器对拓扑结构没有先验假定;它必须依据崩溃时的状态作出反应。
然而,我们有兴趣创建各种复杂而多变的故障恢复场景。我们的故障转移测试脚本为故障转移提供了基础:
- 它能够识别现有的主服务器
- 它能够重构拓扑结构,来代表主服务器下的所有的三个数据中心。不同的数据中心具有不同的网络延迟,并且预期会在不同的时间对主机崩溃做出反应。
- 能够选择崩溃方式。可以选择干掉主服务器(
kill -9)或网络隔离(比较好的方式:iptables -j REJECT或无响应的方式:iptables -j DROP)方式。
脚本通过选择的方法使主机崩溃,并等待协调器可靠地检测到崩溃然后执行故障转移。虽然我们期望检测和晋升在 30 秒钟内完成,但脚本会稍微放宽这一期望,并在查找故障转移结果之前休眠一段指定的时间。然后它将检查:
- 一个新的(不同的)主服务器是否到位
- 集群中有足够的副本
- 主服务器是可写的
- 对主服务器的写入在副本上可见
- 内部服务发现项已更新(如预期般识别到新的主服务器;移除旧的主服务器)
- 其他内部检查
这些测试可以证实故障转移是成功的,不仅是 MySQL 级别的,而是在更大的基础设施范围内成功的。VIP 被赋予;特定的服务已经启动;信息到达了应该去的地方。
该脚本进一步继续恢复那个失败的服务器:
- 从备份恢复它,从而隐含地测试了我们的备份/恢复过程
- 验证服务器配置是否符合预期(该服务器不再认为其是主服务器)
- 将其加入到复制集群,期望找到在主服务器上写入的数据
看一下以下可视化的计划的故障转移测试:从运行良好的群集,到在某些副本上发现问题,诊断主服务器(7136)是否死机,选择一个服务器(a79d)来晋升,重构该服务器下的拓扑,晋升它(故障切换成功),恢复失败的(原)主服务器并将其放回群集。
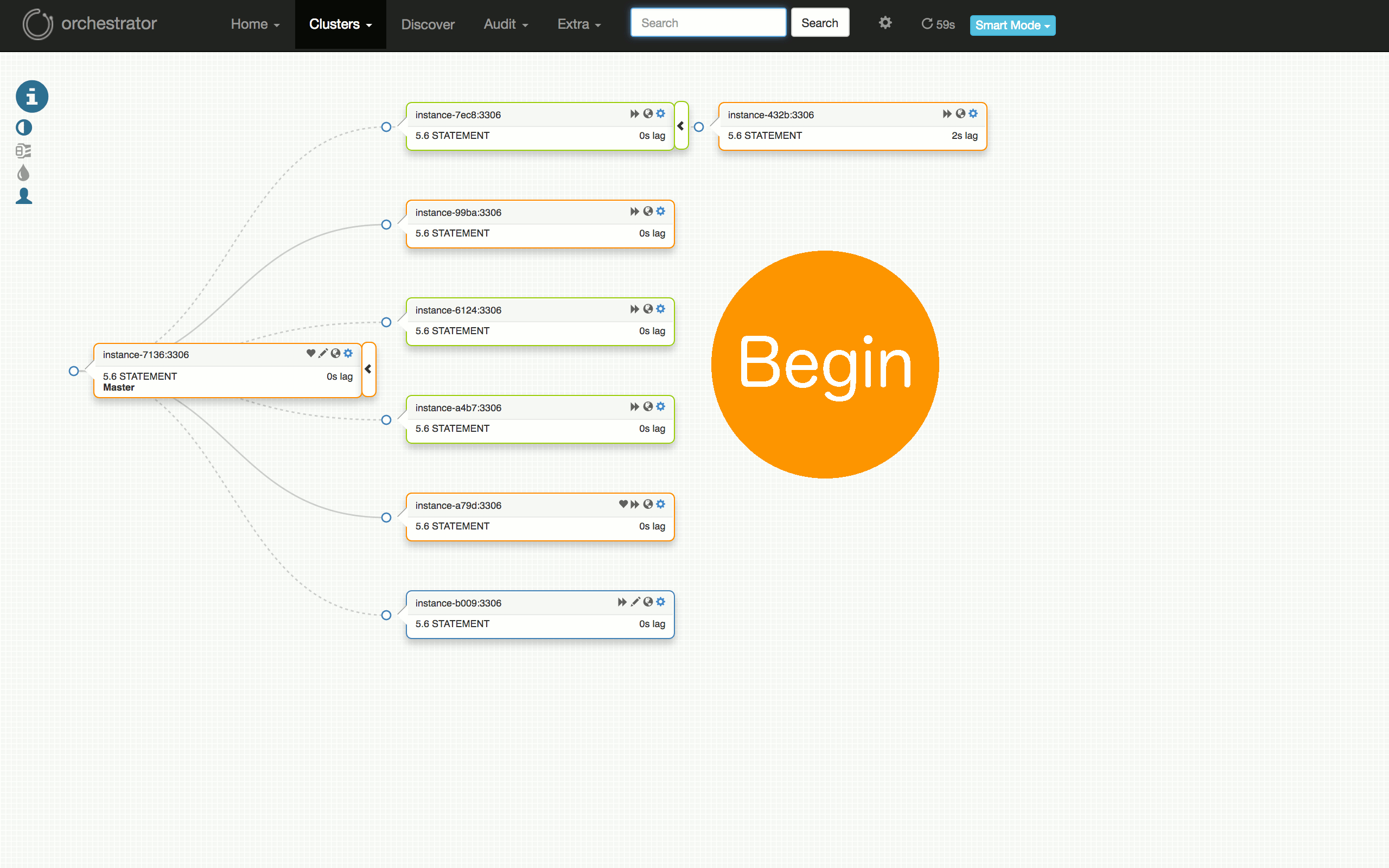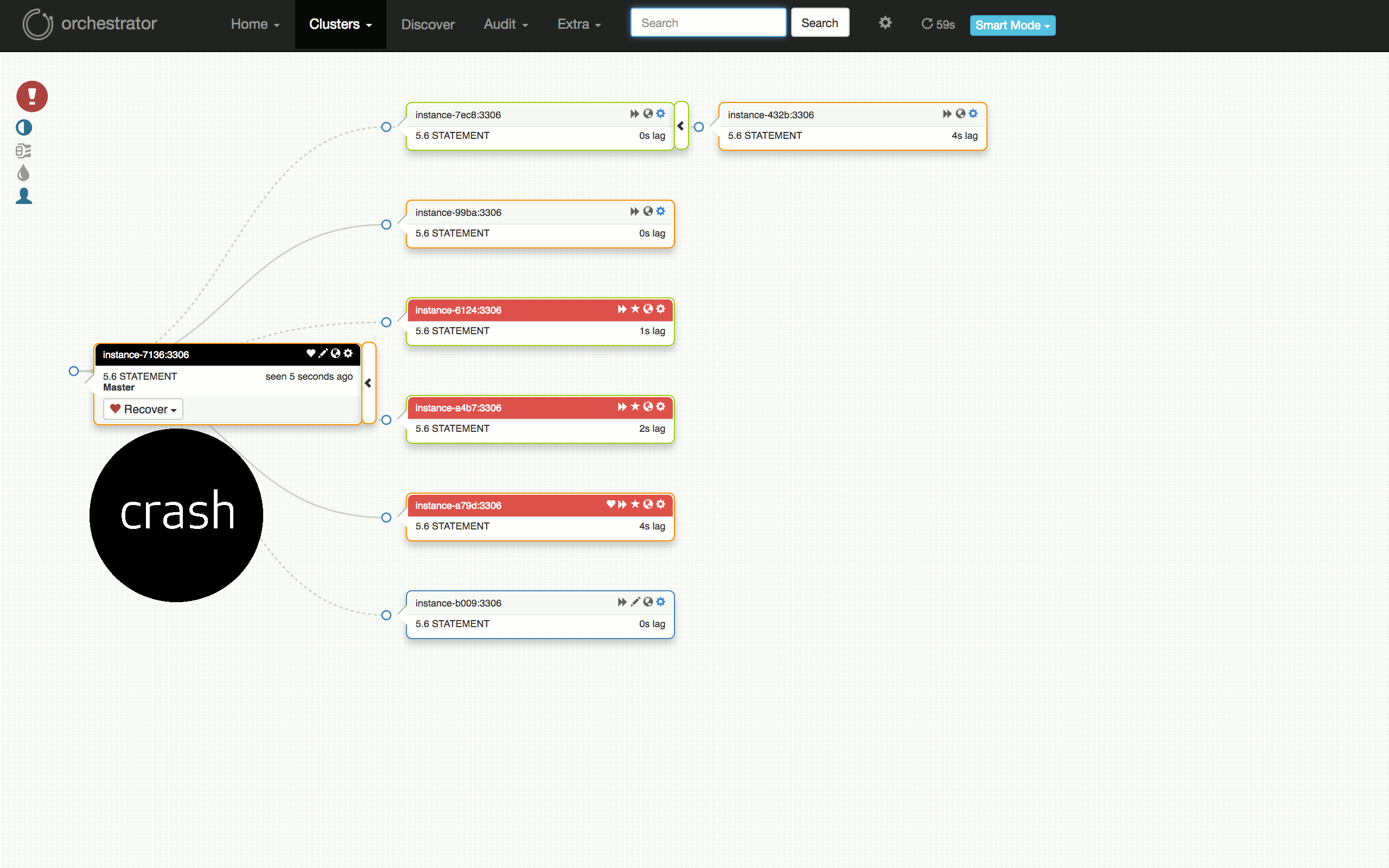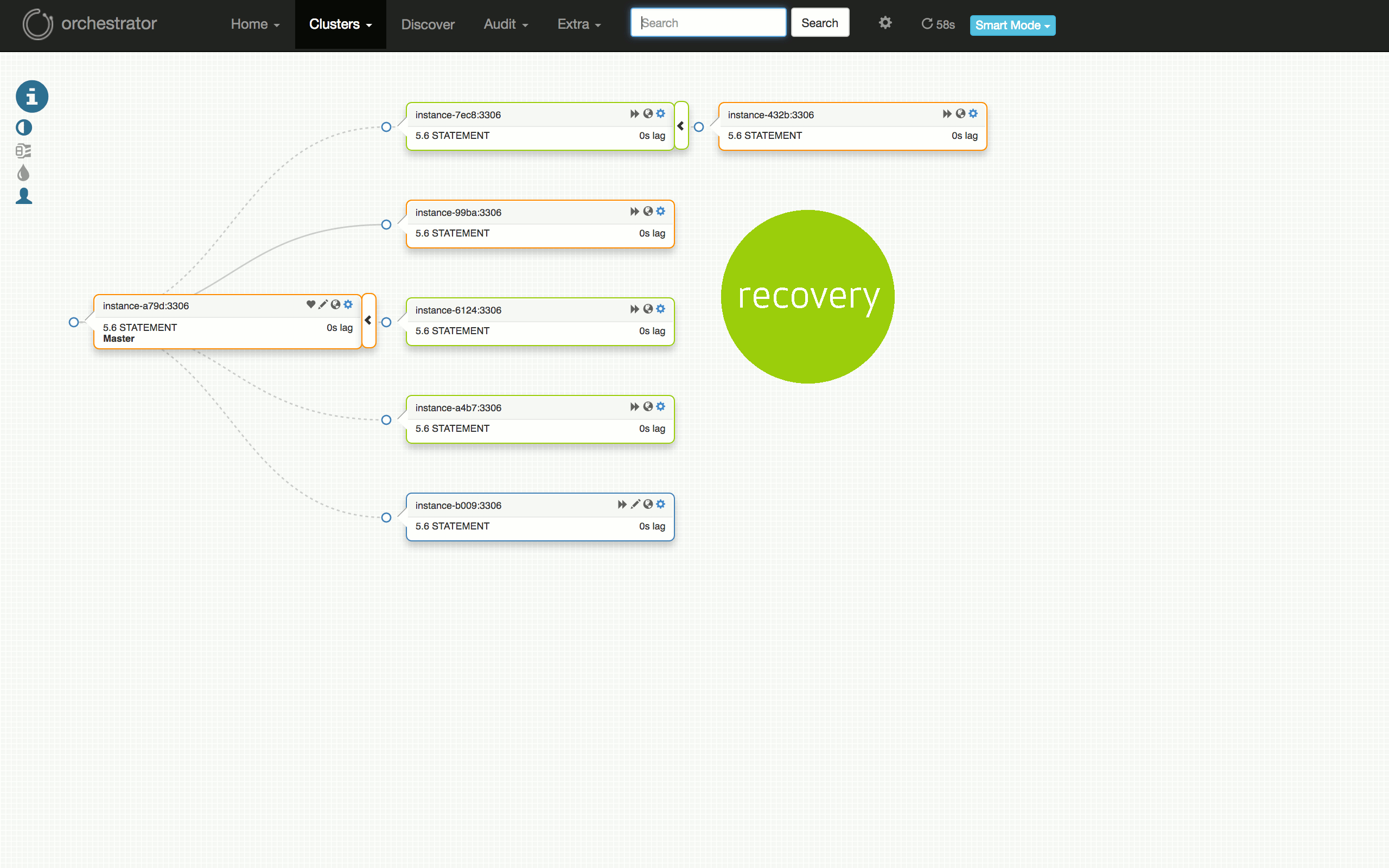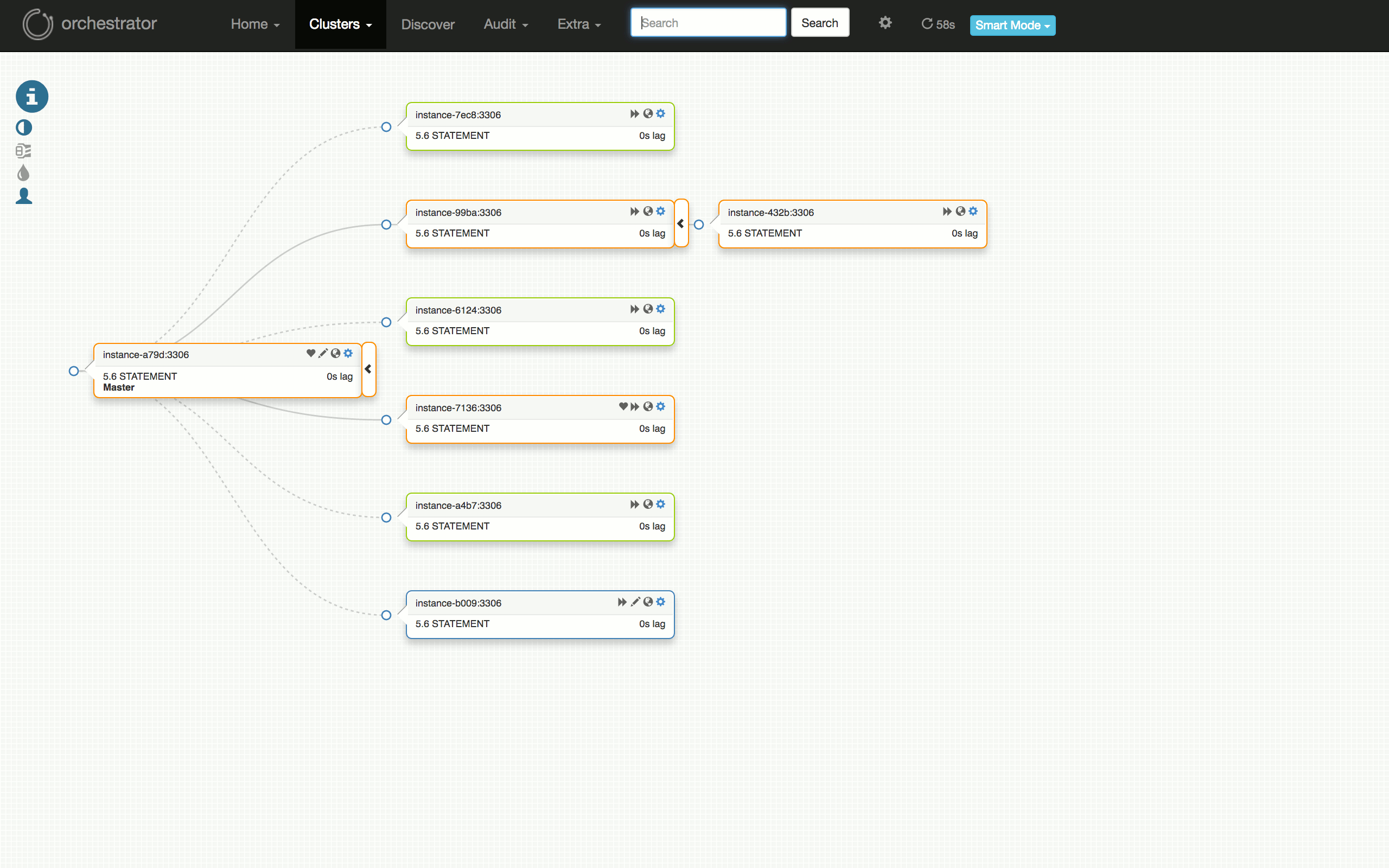
测试失败怎么样?
我们的测试脚本使用了一种“停止世界”的方法。任何故障切换组件中的单个故障都将导致整个测试失败,因此在有人解决该问题之前,无法进行任何进一步的自动化测试。我们会得到警报,并检查状态和日志进行处理。
脚本将各种情况下失败,如不可接受的检测或故障转移时间;备份/还原出现问题;失去太多服务器;在故障切换后的意外配置等等。
我们需要确保协调器正确地连接服务器。这是竞争性写入负载有用的地方:如果设置不正确,复制很容易中断。我们会得到 DUPLICATE KEY 或其他错误提示出错。
这是特别重要的,因此我们改进协调器并引入新的行为,以允许我们在安全的环境中测试这些变化。
出现:混乱测试
上面所示的测试程序将捕获(并已经捕获)我们基础设施许多部分的问题。这些够了吗?
在生产环境中总是有其他的东西。有些特定测试方法不适用于我们的生产集群。它们不具有相同的流量和流量方式,也不具有完全相同的服务器集。故障类型可能有所不同。
我们正在为我们的生产集群设计混乱测试。 混乱测试将会在我们的生产中,但是按照预期的时间表和充分控制的方式来逐个破坏我们的部分生产环境。 混乱测试在恢复机制中引入更高层次的信赖,并影响(因此测试)我们的基础设施和应用程序的更大部分。
这是微妙的工作:当我们承认需要混乱测试时,我们也希望可以避免对我们的服务造成不必要的影响。不同的测试将在风险级别和影响方面有所不同,我们将努力确保我们的服务的可用性。
模式迁移
我们使用 gh-ost来运行实时模式迁移。gh-ost 是稳定的,但也处于活跃开发中,重大新功能正在不断开发和计划中。
gh-ost 通过将数据复制到 ghost 表来迁移,将由二进制日志拦截的进一步更改应用到 ghost 表中,就如其正在写入原始表。然后它将 ghost 表交换代替原始表。迁移完成时,GitHub 继续使用由 gh-ost 生成和填充的表。
在这个时候,几乎所有的 GitHub 的 MySQL 数据都被 gh-ost 重新创建,其中大部分重新创建多次。我们必须高度信赖 gh-ost,让它一遍遍地操弄我们的数据,即使它还处于活跃开发中。下面是我们如何获得这种信赖的。
gh-ost 提供生产环境测试能力。它支持在副本上运行迁移,其方式与在主服务器上运行的方式大致相同: gh-ost 将连接到副本,并将其视为主服务器。它将采用与实际主机迁移相同的方式解析其二进制日志。但是,它将复制行并将二进制日志事件应用于副本,并避免对主服务器进行写入。
我们在生产环境中给 gh-ost 提供专用的副本。这些副本并不为生产环境提供服务。每个这样的副本将检索生产表的当前列表,并以随机顺序对其进行迭代。一个接一个地选择一个表并在该表上执行复制迁移。迁移实际上并不修改表结构,而是运行一个微不足道的 ENGINE=InnoDB 更改。该测试运行迁移时,如果表正在生产环境中使用,会复制实际的生产数据,并接受二进制日志之外的真实的生产环境流量。
这些迁移可以被审计。以下是我们如何从对话中(chatops)检查运行中的测试状态:
ggunson
.migration test-status
Hubot
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
# Migration started at Mon Jan 30 02:13:39 -0800 2017
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# panic-flag-file: /tmp/ghost-test-panic.flag
# Serving on unix socket: /tmp/gh-ost.test.sock
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
当测试迁移完成表数据的复制时,它将停止复制并执行切换,使用 ghost 表替换原始表,然后交换回来。我们对实际替换数据并不感兴趣。相反,我们将留下原始的表和 ghost 表,它们应该是相同的。我们通过校验两个表的整个表数据来验证。
测试能以下列方式完成:
- 成功 :一切顺利,校验和相同。我们期待看到这一结果。
- 失败 :执行问题。这可能偶尔发生,因为迁移进程被杀死、复制问题等,并且通常与 gh-ost 自身无关。
- 校验失败 :表数据不一致。对于被测试的分支,这个需要修复。对于正在进行的 master 分支测试,这意味着立即阻止生产迁移。我们不会遇到后者。
测试结果经过审核,发送到机器人聊天室,作为事件发送到我们的度量系统。下图中的每条垂直线代表成功的迁移测试:
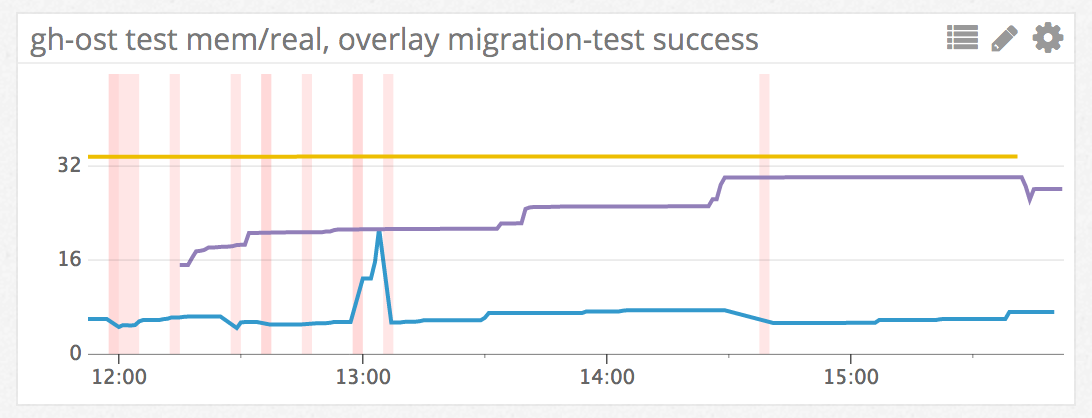
这些测试不断运行。如果发生故障,我们会收到通知。当然,我们可以随时访问机器人聊天室(chatops),了解发生了什么。
测试新版本
我们不断改进 gh-ost。我们的开发流程基于 git 分支,然后我们通过拉取请求(PR)来提供合并。
提交的 gh-ost 拉取请求(PR)通过持续集成(CI)进行基本的编译和单元测试。一旦通过,该 PR 在技术上就有资格合并,但更好的是它有资格通过 Heaven 进行部署。作为我们基础架构中的敏感组件,在其进入 master 分支前,我们会小心部署分支进行密集测试。
shlomi-noach
.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
Hubot
@shlomi-noach is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
@shlomi-noach's production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
@shlomi-noach, make sure you watch for exceptions in haystack
jonahberquist
.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
Hubot
@jonahberquist is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
@jonahberquist's production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
@jonahberquist, make sure you watch for exceptions in haystack
shlomi-noach
.wcid gh-ost
Hubot
shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
Nobody is in the queue.
一些 PR 很小,不影响数据本身。对状态消息,交互式命令等的更改对 gh-ost 应用程序的影响较小。而其他的 PR 对迁移逻辑和操作会造成重大变化,我们将严格测试这些,通过我们的生产表车队运行这些,直到其满足了这些改变不会造成数据损坏威胁的程度。
总结
在整个测试过程中,我们建立对我们的系统的信赖。通过自动化这些测试,在生产环境中,我们得到了一切都按预期工作的反复确认。随着我们继续发展我们的基础设施,我们还通过调整测试来覆盖最新的变化。
产品总会有令你意想不到的未被测试覆盖的场景。我们对生产环境的测试越多,我们对应用程序的期望越多,基础设施的能力就越强。
via: https://githubengineering.com/mysql-testing-automation-at-github/
作者:tomkrouper, Shlomi Noach 译者:MonkeyDEcho 校对:wxy


 );){kind=link}