通过机器学习来自动调优数据库
| 2017-11-04 23:26 收藏: 1
本文是卡耐基梅隆大学的 Dana Van Aken、Andy Pavlo 和 Geoff Gordon 所写。这个项目展示了学术研究人员如何利用 AWS Cloud Credits for Research Program 来助力他们的科技突破的。
数据库管理系统(DBMS)是任何数据密集应用的关键部分。它们可以处理大量数据和复杂的工作负载,但同时也难以管理,因为有成百上千个“旋钮”(即配置变量)控制着各种要素,比如要使用多少内存做缓存和写入磁盘的频率。组织机构经常要雇佣专家来做调优,而专家对很多组织来说太过昂贵了。卡耐基梅隆大学数据库研究组的学生和研究人员在开发一个新的工具,名为 OtterTune,可以自动为 DBMS 的“旋钮”找到合适的设置。工具的目的是让任何人都可以部署 DBMS,即使没有任何数据库管理专长。
OtterTune 跟其他 DBMS 设置工具不同,因为它是利用对以前的 DBMS 调优知识来调优新的 DBMS,这显著降低了所耗时间和资源。OtterTune 通过维护一个之前调优积累的知识库来实现这一点,这些积累的数据用来构建机器学习(ML)模型,去捕获 DBMS 对不同的设置的反应。OtterTune 利用这些模型指导新的应用程序实验,对提升最终目标(比如降低延迟和增加吞吐量)给出建议的配置。
本文中,我们将讨论 OtterTune 的每一个机器学习流水线组件,以及它们是如何互动以便调优 DBMS 的设置。然后,我们评估 OtterTune 在 MySQL 和 Postgres 上的调优表现,将它的最优配置与 DBA 和其他自动调优工具进行对比。
OtterTune 是卡耐基梅隆大学数据库研究组的学生和研究人员开发的开源工具,所有的代码都托管在 Github 上,以 Apache License 2.0 许可证发布。
OtterTune 工作原理
下图是 OtterTune 组件和工作流程
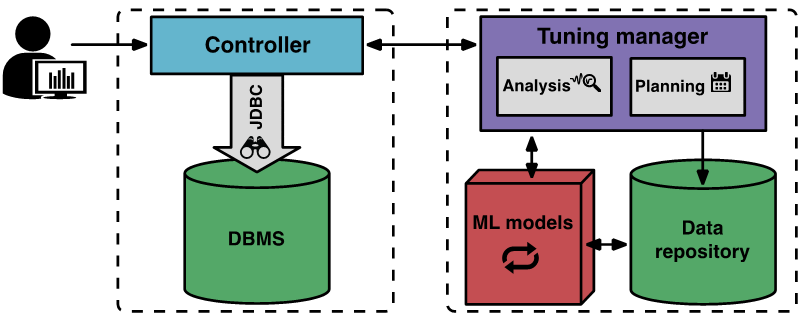
调优过程开始,用户告知 OtterTune 要调优的最终目标(比如,延迟或吞吐量),客户端控制器程序连接目标 DBMS,收集 Amazon EC2 实例类型和当前配置。
然后,控制器启动首次观察期,来观察并记录最终目标。观察结束后,控制器收集 DBMS 的内部指标,比如 MySQL 磁盘页读取和写入的计数。控制器将这些数据返回给调优管理器程序。
OtterTune 的调优管理器将接收到的指标数据保存到知识库。OtterTune 用这些结果计算出目标 DBMS 的下一个配置,连同预估的性能提升,返回给控制器。用户可以决定是否继续或终止调优过程。
注意
OtterTune 对每个支持的 DBMS 版本维护了一份“旋钮”黑名单,包括了对调优无关紧要的部分(比如保存数据文件的路径),或者那些会产生严重或隐性后果(比如丢数据)的部分。调优过程开始时,OtterTune 会向用户提供这份黑名单,用户可以添加他们希望 OtterTune 避开的其它“旋钮”。
OtterTune 有一些预定假设,对某些用户可能会造成一定的限制。比如,它假设用户拥有管理员权限,以便控制器来修改 DBMS 配置。否则,用户必须在其他硬件上部署一份数据库拷贝给 OtterTune 做调优实验。这要求用户或者重现工作负载,或者转发生产 DBMS 的查询。完整的预设和限制请看我们的论文 。
机器学习流水线
下图是 OtterTune ML 流水线处理数据的过程,所有的观察结果都保存在知识库中。
OtterTune 先将观察数据输送到“工作流特征化组件”,这个组件可以识别一小部分 DBMS 指标,这些指标能最有效地捕捉到性能变化和不同工作负载的显著特征。
下一步,“旋钮识别组件”生成一个旋钮排序表,包含哪些对 DBMS 性能影响最大的旋钮。OtterTune 接着把所有这些信息“喂”给自动调优器,后者将目标 DBMS 的工作负载与知识库里最接近的负载进行映射,重新使用这份负载数据来生成更佳的配置。
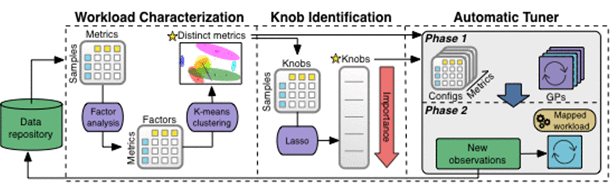
我们来深入挖掘以下机器学习流水线的每个组件。
工作负载特征化: OtterTune 利用 DBMS 的内部运行时指标来特征化某个工作负载的行为,这些指标精确地代表了工作负载,因为它们捕获了负载的多个方面行为。然而,很多指标是冗余的:有些是用不同的单位表示相同的度量值,其他的表示 DBMS 的一些独立组件,但它们的值高度相关。梳理冗余度量值非常重要,可以降低机器学习模型的复杂度。因此,我们基于相关性将 DBMS 的度量值集中起来,然后选出其中最具代表性的一个,具体说就是最接近中间值的。机器学习的后续组件将使用这些度量值。
旋钮识别: DBMS 可以有几百个旋钮,但只有一部分影响性能。OtterTune 使用一种流行的“特性-选择”技术,叫做 Lasso,来判断哪些旋钮对系统的整体性能影响最大。用这个技术处理知识库中的数据,OtterTune 得以确定 DBMS 旋钮的重要性顺序。
接着,OtterTune 必须决定在做出配置建议时使用多少个旋钮,旋钮用的太多会明显增加 OtterTune 的调优时间,而旋钮用的太少则难以找到最好的配置。OtterTune 用了一个增量方法来自动化这个过程,在一次调优过程中,逐步增加使用的旋钮。这个方法让 OtterTune 可以先用少量最重要的旋钮来探索并调优配置,然后再扩大范围考虑其他旋钮。
自动调优器: 自动调优器组件在每次观察阶段后,通过两步分析法来决定推荐哪个配置。
首先,系统使用工作负载特征化组件找到的性能数据来确认与当前的目标 DBMS 工作负载最接近的历史调优过程,比较两者的度量值以确认哪些值对不同的旋钮设置有相似的反应。
然后,OtterTune 尝试另一个旋钮配置,将一个统计模型应用到收集的数据,以及知识库中最贴近的工作负载数据。这个模型让 OtterTune 预测 DBMS 在每个可能的配置下的表现。OtterTune 调优下一个配置,在探索(收集用来改进模型的信息)和利用(贪婪地接近目标度量值)之间交替进行。
实现
OtterTune 用 Python 编写。
对于工作负载特征化和旋钮识别组件,运行时性能不是着重考虑的,所以我们用 scikit-learn实现对应的机器学习算法。这些算法运行在后台进程中,把新生成的数据吸收到知识库里。
对于自动调优组件,机器学习算法就非常关键了。每次观察阶段完成后就需要运行,吸收新数据以便 OtterTune 挑选下一个旋钮来进行测试。由于需要考虑性能,我们用 TensorFlow来实现。
为了收集 DBMS 的硬件、旋钮配置和运行时性能指标,我们把 OLTP-Bench 基准测试框架集成到 OtterTune 的控制器内。
实验设计
我们比较了 OtterTune 对 MySQL 和 Postgres 做出的最佳配置与如下配置方案进行了比较,以便评估:
- 默认: DBMS 初始配置
- 调优脚本: 一个开源调优建议工具做出的配置
- DBA: 人类 DBA 选择的配置
- RDS: 将亚马逊开发人员管理的 DBMS 的定制配置应用到相同的 EC2 实例类型。
我们在亚马逊 EC2 竞价实例上执行了所有的实验。每个实验运行在两个实例上,分别是m4.large 和 m3.xlarge 类型:一个用于 OtterTune 控制器,一个用于目标 DBMS 部署。OtterTune 调优管理器和知识库部署在本地一台 20 核 128G 内存的服务器上。
工作负载用的是 TPC-C,这是评估联机交易系统性能的工业标准。
评估
我们给每个实验中的数据库 —— MySQL 和 Postgres —— 测量了延迟和吞吐量,下面的图表显示了结果。第一个图表显示了“第99百分位延迟”的数量,代表“最差情况下”完成一个事务的时长。第二个图表显示了吞吐量结果,以平均每秒执行的事务数来衡量。
MySQL 实验结果
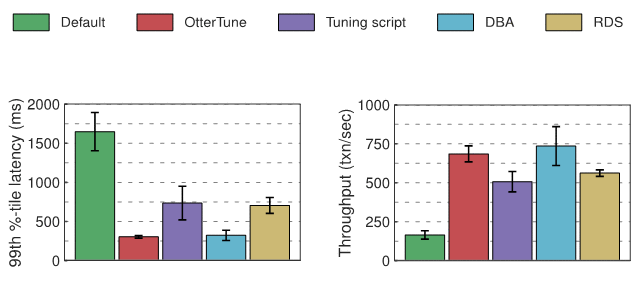
OtterTune 生成的最佳配置与调优脚本和 RDS 的配置相比,OtterTune 让 MySQL 的延迟下降了大约 60%,吞吐量提升了 22% 到 35%。OtterTune 还生成了一份几乎跟 DBA 一样好的配置。
在 TPC-C 负载下,只有几个 MySQL 的旋钮显著影响性能。OtterTune 和 DBA 的配置给这几个旋钮设置了很好的值。RDS 表现略逊一筹,因为给一个旋钮配置了欠佳的值。调优脚本表现最差,因为只修改一个旋钮。
Postgres 实验结果

在延迟方面,相比 Postgres 默认配置,OtterTune、调优工具、DBA 和 RDS 的配置获得了近似的提升。我们大概可以把这归于 OLTP-Bench 客户端和 DBMS 之间的网络开销。吞吐量方面,Postgres 在 OtterTune 的配置下比 DBA 和调优脚本要高 12%,比 RDS 要高 32%。
结束语
OtterTune 将寻找 DBMS 配置旋钮的最优值这一过程自动化了。它通过重用之前的调优过程收集的训练数据,来调优新部署的 DBMS。因为 OtterTune 不需要生成初始化数据集来训练它的机器学习模型,调优时间得以大大减少。
下一步会怎么样? 为了顺应的越来越流行的 DBaaS (远程登录 DBMS 主机是不可能的),OtterTune 会很快能够自动探查目标 DBMS 的硬件能力,而不需要远程登录。
想了解 OtterTune 的详细资料,请查看我们的论文和 GitHub 上的代码。关注这个网站,我们将很快让 OtterTune 成为一个在线调优服务。

 );){kind=link}