基于 Go 技术栈的微服务构建
| 2017-11-30 10:14
在大型系统的微服务化构建中,一个系统会被拆分成许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。在这种构建形式中,开发者一般会聚焦于最大程度解耦模块的功能以减少模块间耦合带来的额外开发成本。同时,微服务面临着如何部署这些大量的服务系统、如何运维这些系统等新问题。
本文的素材来源于我们在开发中的一些最佳实践案例,从开发、监控、日志等角度介绍了一些我们基于 Go 技术栈的微服务构建经验。
开发
微服务的开发过程中,不同模块由不同的开发者负责,明确定义的接口有助于确定开发者的工作任务。最终的系统中,一个业务请求可能会涉及到多次接口调用,如何准确清晰的调用远端接口,这也是一大挑战。对于这些问题,我们使用了 gRPC 来负责协议的制订和调用。
传统的微服务通常基于 HTTP 协议来进行模块间的调用,而在我们的微服务构建中,选用了 Google 推出的 gRPC 框架来进行调用。下面这张简表比较了 HTTP RPC 框架与 gRPC 的特性:

gRPC 的接口需要使用 Protobuf 3 定义,通过静态编译后才能成功调用。这一特性减少了由于接口改变带来的沟通成本。如果使用 HTTP RPC ,接口改变就需要先改接口文档,然后周知到调用者,如果调用者没有及时修改,很可能会到服务运行时才能发现错误。而 gRPC 的这种模式,接口变动引起的错误保证在编译时期就能消除。
在性能方面,gRPC 相比传统的 HTTP RPC 协议有非常大的改善(根据这个评测,gRPC 要快 10 倍)。gRPC 使用 HTTP/2 协议进行传输,相比较 HTTP/1.1, HTTP/2 复用 TCP 连接,减少了每次请求建立 TCP 连接的开销。需要指出的是,如果单纯追求性能,之前业界一般会选用构建在 TCP 协议上的 RPC 协议(thrift 等),但四层协议无法方便的做一些传输控制。相比而言,gRPC 可以在 HTTP header 中放入控制字段,配合 nginx 等代理服务器,可以很方便的实现转发/灰度等功能。
接下来着重谈谈我们在实践中如何使用 gRPC 的一些特性来简化相关开发流程。
1. 使用 context 来控制请求的生命周期
在 gRPC 的 go 语言实现中,每个 RPC 请求的第一个参数都是 context。 HTTP/2 协议会将 context 放在 HEADER 中,随着链路传递下去,因此可以为每个请求设置过期时间,一旦遇到超时的情况,发起方就会结束等待,返回错误。
ctx := context.Background() // blank context
ctx, cancel = context.WithTimeout(ctx, 5*time.Second)
defer cancel( )
gRPC.CallServiveX(ctx, arg1)除了能加入超时时间,context 还能加入其他内容,下文我们还会见到 context 的另一个妙用。上述这段代码,发起方设置了大约 5s 的等待时间,只要远端的调用在 5s 内没有返回,发起方就会报错。
2. 使用 TLS 实现访问权限控制
gRPC 集成了 TLS 证书功能,为我们提供了很完善的权限控制方案。在实践中,假设我们的系统中存在服务 A,由于它负责操作用户的敏感内容,因此需要保证 A 不被系统内的其他服务滥用。为了避免滥用,我们设计了一套自签名的二级证书系统,服务 A 掌握了自签名的根证书,同时为每个调用 A 的服务颁发一个二级证书。这样,所有调用 A 的服务必须经过 A 的授权,A 也可以鉴别每个请求的调用方,这样可以很方便的做一些记录日志、流量控制等操作。
3. 使用 trace 在线追踪请求
gRPC 内置了一套追踪请求的 trace 系统,既可以追踪最近 10 个请求的详细日志信息,也可以记录所有请求的统计信息。
当我们为请求加入了 trace 日志后,trace 系统会为我们记录下最近 10 个请求的日志,下图中所示的例子就是在 trace 日志中加入了对业务数据的追踪。

在宏观上,trace 系统为我们记录下请求的统计信息,比如请求数目、按照不同请求时间统计的分布等。

需要说明的是,这套系统暴露了一个 HTTP 服务,我们可以通过 debug 开关在运行时按需打开或者关闭,以减少资源消耗。
监控
1. 确定监控指标
在接到为整个系统搭建监控系统这个任务时,我们面对的第一个问题是要监控什么内容。针对这个问题,Google SRE 这本书提供了很详细的回答,我们可以监控四大黄金指标,分别是延时、流量、错误和饱和度。
- 延时衡量了请求花费的时间。需要注意的,考虑到长尾效应,使用平均延时作为延时方面的单一指标是远远不够的。相应的,我们需要延时的中位数 90%、95%、99% 值来帮助我们了解延时的分布,有一种更好的办法是使用直方图来统计延时分布。
- 流量衡量了服务面临的请求压力。针对每个 API 的流量统计能让我们知道系统的热点路径,帮助优化。
- 错误监控是指对错误的请求结果的统计。同样的,每个请求有不同的错误码,我们需要针对不同的错误码进行统计。配合上告警系统,这类监控能让我们尽早感知错误,进行干预。
- 饱和度主要指对系统 CPU 和内存的负载监控。这类监控能为我们的扩容决策提供依据。
2. 监控选型
选择监控方案时,我们面临的选择主要有两个,一是公司自建的监控系统,二是使用开源 Prometheus 系统搭建。这两个系统的区别列在下表中。
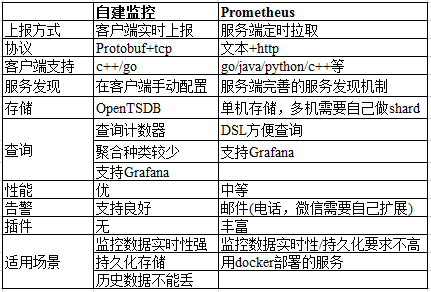
考虑到我们的整个系统大约有 100 个容器分布在 30 台虚拟机上,Prometheus 的单机存储对我们并不是瓶颈。我们不需要完整保留历史数据,自建系统的最大优势也不足以吸引我们使用。相反,由于希望能够统计四大黄金指标延生出的诸多指标, Prometheus 方便的 DSL 能够很大程度上简化我们的指标设计。
最终,我们选择了 Prometheus 搭建监控系统。整个监控系统的框架如下图所示。

各服务将自己的地址注册到 consul 中,Prometheus 会自动从 consul 中拉取需要监控的目标地址,然后从这些服务中拉取监控数据,存放到本地存储中。在 Prometheus 自带的 Web UI 中可以快捷的使用 PromQL 查询语句获取统计信息,同时,还可以将查询语句输入 grafana,固定监控指标用于监控。
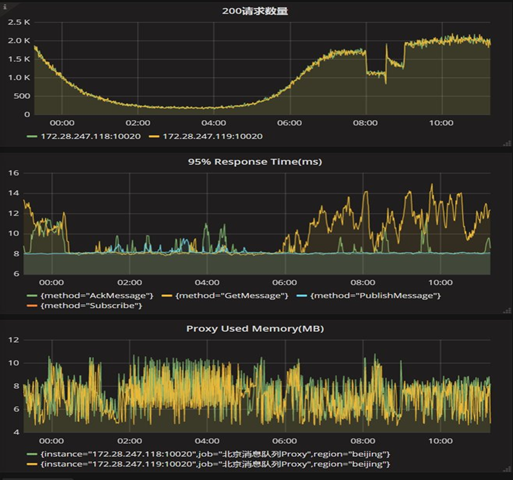
此外,配合插件 AlertManager,我们能够编写告警规则,当系统出现异常时,将告警发送到手机/邮件/信箱。
日志
1. 日志格式
一个经常被忽略的问题是如何选择日志记录的格式。良好的日志格式有利于后续工具对日志内容的切割,便于日志存储的索引。我们使用 logrus 来打印日志到文件,logrus 工具支持的日志格式包裹以空格分隔的单行文本格式、JSON 格式等等。
time=”2015-03-26T01:27:38-04:00″ level=debug g=”Started observing beach” animal=walrus number=8
time=”2015-03-26T01:27:38-04:00″ level=info msg=”A group of walrus emerges from the ocean” animal=walrus size=10Json格式
{“animal”:”walrus”,”level”:”info”,”msg”:”A group of walrus emerges from theocean”,”size”:10,”time”:”2014-03-10 19:57:38.562264131 -0400 EDT”}
{“level”:”warning”,”msg”:”The group’s number increased tremendously!”,”number”:122,”omg”:true,”time”:”2014-03-10 19:57:38.562471297 -0400 EDT”}在微服务架构中,一个业务请求会经历多个服务,收集端到端链路上的日志能够帮助我们判断错误发生的具体位置。在这个系统中,我们在请求入口处,生成了全局 ID,通过 gRPC 中的 context 将 ID 在链路中传递。将不同服务的日志收集到 graylog中,查询时就能通过一个 ID,将整个链路上的日志查询出来。
2. 端到端链路上的调用日志收集
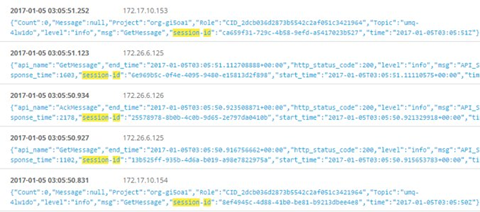
上图中,使用 session-id 来作为整个调用链的 ID 可以进行全链路检索。
小结
微服务构建的系统中,在部署、调度、服务发现、一致性等其他方面都有挑战,Go 技术栈在这些方面都有最佳实践(docker、k8s、consul、etcd 等等)。具体内容在网上已经有很完善的教程,在此不用班门弄斧,有需要的可以自行查阅。

 );){kind=link}