如何使用机器学习来分析情感
| 2023-02-03 11:22
本文将帮助你理解 情感分析 的概念,并且学习如何使用机器学习进行情感分析。我们使用了不同的机器学习算法进行情感分析,然后将各个算法的准确率结果进行比较,以确定哪一种算法最适合这个问题。
情感分析是自然语言处理(NLP)中的一个重要的内容。情感指的是我们对某一事件、物品、情况或事物产生的感觉。情感分析是一个从文本中自动提取人类情感的研究领域。它在上世纪 90 年代初才慢慢地开始发展起来。
本文将让你明白如何将机器学习(ML)用于情感分析,并比较不同机器学习算法的结果。本文的目标不在于研究如何提高算法性能。
如今,我们生活在一个快节奏的社会中,所有的商品都能在网上购买到,每个人都可以在网上发表自己的评论。而一些商品的负面网络评论可能会损害公司的声誉,从而影响公司的销售额。因此对公司来说,通过商品评论来了解客户真正想要什么变得非常重要。但是这些评论数据太多了,无法一个个地手动查看所有的评论。这就是情绪分析诞生的缘由。
现在,就让我们看看如何用机器学习开发一个模型,来进行基本的情绪分析吧。
现在就开始吧!
获取数据
第一步是选择一个数据集。你可以从任何公开的评论中进行选择,例如推文或电影评论。数据集中至少要包含两列:标签和实际的文本段。
下图显示了我们选取的部分数据集。

接下来,我们导入所需的库:
import pandas as pd
import numpy as np
from nltk.stem.porter import PorterStemmer
import re
import string
正如你在上面代码看到,我们导入了 NumPy 和 Pandas 库来处理数据。至于其他库,我们会在使用到它们时再说明。
数据集已准备就绪,并且已导入所需的库。接着,我们需要用 Pandas 库将数据集读入到我们的项目中去。我们使用以下的代码将数据集读入 Pandas 数据帧 类型:
sentiment_dataframe = pd.read_csv(“/content/drive/MyDrive/Data/sentiments - sentiments.tsv”,sep = ‘\t’)
数据处理
现在我们的项目中已经导入好数据集了。然后,我们要对数据进行处理,以便算法可以更好地理解数据集的特征。我们首先为数据集中的列命名,通过下面的代码来完成:
sentiment_dataframe.columns = [“label”,”body_text”]
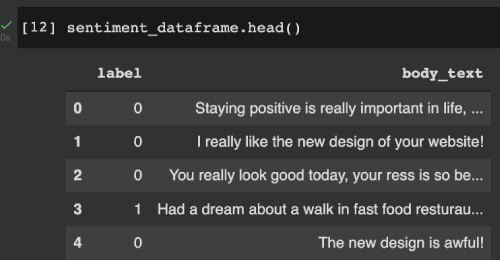
然后,我们对 label 列进行数值化:negative 的评论替换为 1,positive 的评论替换为 0。下图显示了经过基本修改后的 sentiment_dataframe 的值。
准备好特征值、目标值
下一步是数据的预处理。这是非常重要的一步,因为机器学习算法只能理解/处理数值形数据,而不能理解文本,所以此时要进行特征抽取,将字符串/文本转换成数值化的数据。此外,还需要删除冗余和无用的数据,因为这些数据可能会污染我们的训练模型。我们在这一步中去除了噪声数据、缺失值数据和不一致的数据。
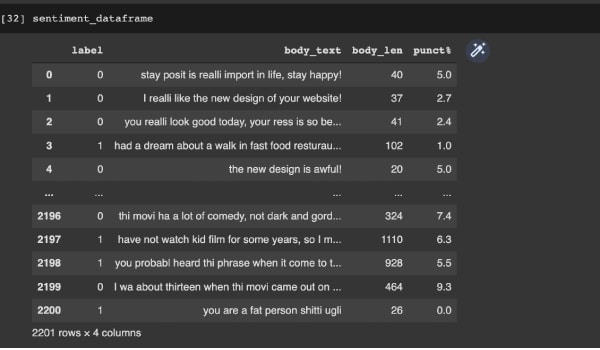
对于情感分析,我们在数据帧中添加特征文本的长度和标点符号计数。我们还要进行词干提取,即将所有相似词(如 “give”、“giving” 等)转换为单一形式。完成后,我们将数据集分为两部分:特征值 X 和 目标值 Y。
上述内容是使用以下代码完成的。下图显示了执行这些步骤后的数据帧。
def count_punct(text):
count = sum([1 for char in text if char in string.punctuation])
return round(count/(len(text) - text.count(“ “)),3)*100
tokenized_tweet = sentiment_dataframe[‘body_text’].apply(lambda x: x.split())
stemmer = PorterStemmer()
tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x])
for i in range(len(tokenized_tweet)):
tokenized_tweet[i] = ‘ ‘.join(tokenized_tweet[i])
sentiment_dataframe[‘body_text’] = tokenized_tweet
sentiment_dataframe[‘body_len’] = sentiment_dataframe[‘body_text’].apply(lambda x:len(x) - x.count(“ “))
sentiment_dataframe[‘punct%’] = sentiment_dataframe[‘body_text’].apply(lambda x:count_punct(x))
X = sentiment_dataframe[‘body_text’]
y = sentiment_dataframe[‘label’]
特征工程:文本特征处理
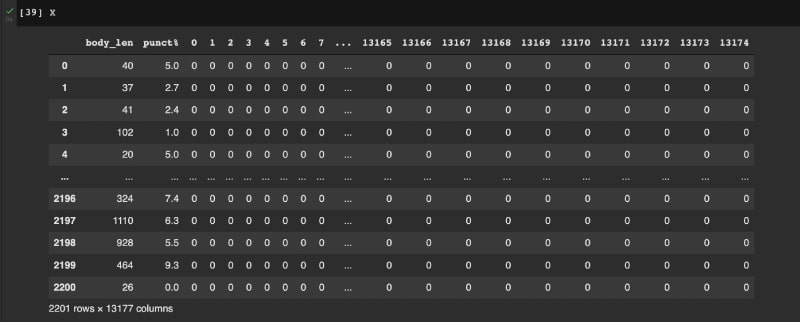
我们接下来进行文本特征抽取,对文本特征进行数值化。为此,我们使用计数向量器,它返回词频矩阵。
在此之后,计算数据帧 X 中的文本长度和标点符号计数等特征。X 的示例如下图所示。
使用的机器学习算法
现在数据已经可以训练了。下一步是确定使用哪些算法来训练模型。如前所述,我们将尝试多种机器学习算法,并确定最适合情感分析的算法。由于我们打算对文本进行二元分类,因此我们使用以下算法:
- K-近邻算法(KNN)
- 逻辑回归算法
- 支持向量机(SVMs)
- 随机梯度下降(SGD)
- 朴素贝叶斯算法
- 决策树算法
- 随机森林算法
划分数据集
首先,将数据集划分为训练集和测试集。使用 sklearn 库,详见以下代码:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.20, random_state = 99)
我们使用 20% 的数据进行测试,80% 的数据用于训练。划分数据的意义在于对一组新数据(即测试集)评估我们训练的模型是否有效。
K-近邻算法
现在,让我们开始训练第一个模型。首先,我们使用 KNN 算法。先训练模型,然后再评估模型的准确率(具体的代码都可以使用 Python 的 sklearn 库来完成)。详见以下代码,KNN 训练模型的准确率大约为 50%。
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
model.score (X_test,y_test)
0.5056689342403629
逻辑回归算法
逻辑回归模型的代码十分类似——首先从库中导入函数,拟合模型,然后对模型进行评估。下面的代码使用逻辑回归算法,准确率大约为 66%。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit (X_train,y_train)
model.score (X_test,y_test)
0.6621315192743764
支持向量机算法
以下代码使用 SVM,准确率大约为 67%。
from sklearn import svm
model = svm.SVC(kernel=’linear’)
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6780045351473923
随机森林算法
以下的代码使用了随机森林算法,随机森林训练模型的准确率大约为 69%。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6938775510204082
决策树算法
接下来,我们使用决策树算法,其准确率约为 61%。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model = model.fit(X_train,y_train)
model.score(X_test,y_test)
0.6190476190476191
随机梯度下降算法
以下的代码使用随机梯度下降算法,其准确率大约为 49%。
from sklearn.linear_model import SGDClassifier
model = SGDClassifier()
model = model.fit(X_train,y_train)
model.score(X_test,y_test)
0.49206349206349204
朴素贝叶斯算法
以下的代码使用朴素贝叶斯算法,朴素贝叶斯训练模型的准确率大约为 60%。
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6009070294784581
情感分析的最佳算法
接下来,我们绘制所有算法的准确率图。如下图所示。
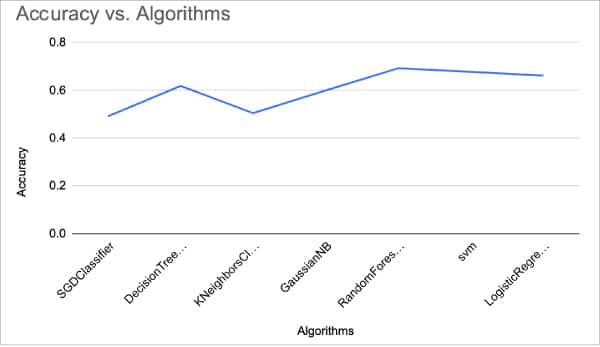
可以看到,对于情感分析这一问题,随机森林算法有最佳的准确率。由此,我们可以得出结论,随机森林算法是所有机器算法中最适合情感分析的算法。我们可以通过处理得到更好的特征、尝试其他矢量化技术、或者使用更好的数据集或更好的分类算法,来进一步提高准确率。
既然,随机森林算法是解决情感分析问题的最佳算法,我将向你展示一个预处理数据的样本。在下图中,你可以看到模型会做出正确的预测!试试这个来改进你的项目吧!
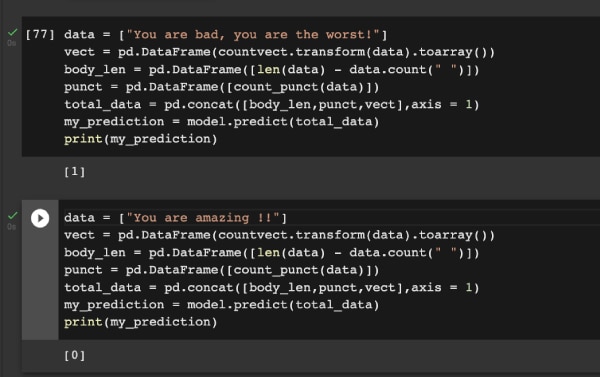
via: https://www.opensourceforu.com/2022/09/how-to-analyse-sentiments-using-machine-learning/
作者:Jishnu Saurav Mittapalli 选题:lkxed 译者:chai001125 校对:wxy


 );){kind=link}