在 Linux 下使用 RAID(八):当软件 RAID 故障时如何恢复和重建数据
| 2015-10-22 08:03 评论: 1 收藏: 2
在阅读过 RAID 系列 前面的文章后你已经对 RAID 比较熟悉了。回顾前面几个软件 RAID 的配置,我们对每一个都做了详细的解释,使用哪一个取决与你的具体情况。

恢复并重建故障的软件 RAID - 第8部分
在本文中,我们将讨论当一个磁盘发生故障时如何重建软件 RAID 阵列并且不会丢失数据。为方便起见,我们仅考虑RAID 1 的配置 - 但其方法和概念适用于所有情况。
RAID 测试方案
在进一步讨论之前,请确保你已经配置好了 RAID 1 阵列,可以按照本系列第3部分提供的方法:在 Linux 中如何创建 RAID 1(镜像)。
在目前的情况下,仅有的变化是:
- 使用不同版本 CentOS(v7),而不是前面文章中的(v6.5)。
- 磁盘容量发生改变, /dev/sdb 和 /dev/sdc(各8GB)。
此外,如果 SELinux 设置为 enforcing 模式,你需要将相应的标签添加到挂载 RAID 设备的目录中。否则,当你试图挂载时,你会碰到这样的警告信息:
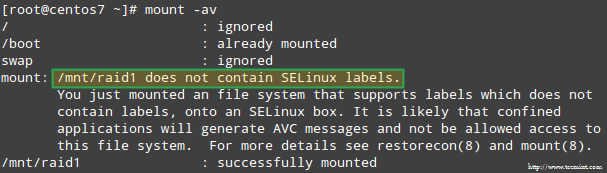
启用 SELinux 时 RAID 挂载错误
通过以下命令来解决:
# restorecon -R /mnt/raid1
配置 RAID 监控
存储设备损坏的原因很多(尽管固态硬盘大大减少了这种情况发生的可能性),但不管是什么原因,可以肯定问题随时可能发生,你需要准备好替换发生故障的部分,并确保数据的可用性和完整性。
首先建议是。虽然你可以查看 /proc/mdstat 来检查 RAID 的状态,但有一个更好的和节省时间的方法,使用监控 + 扫描模式运行 mdadm,它将警报通过电子邮件发送到一个预定义的收件人。
要这样设置,在 /etc/mdadm.conf 添加以下行:
MAILADDR user@<domain or localhost>
我自己的设置如下:
MAILADDR gacanepa@localhost

监控 RAID 并使用电子邮件进行报警
要让 mdadm 运行在监控 + 扫描模式中,以 root 用户添加以下 crontab 条目:
@reboot /sbin/mdadm --monitor --scan --oneshot
默认情况下,mdadm 每隔60秒会检查 RAID 阵列,如果发现问题将发出警报。你可以通过添加 --delay 选项到crontab 条目上面,后面跟上秒数,来修改默认行为(例如,--delay 1800意味着30分钟)。
最后,确保你已经安装了一个邮件用户代理(MUA),如mutt 或 mailx。否则,你将不会收到任何警报。
在一分钟内,我们就会看到 mdadm 发送的警报。
模拟和更换发生故障的 RAID 存储设备
为了给 RAID 阵列中的存储设备模拟一个故障,我们将使用 --manage 和 --set-faulty 选项,如下所示:
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
这将导致 /dev/sdc1 被标记为 faulty,我们可以在 /proc/mdstat 看到:
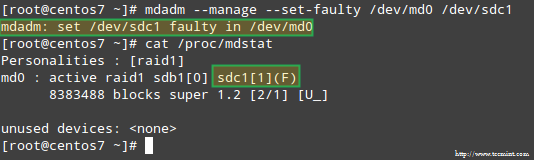
在 RAID 存储设备上模拟问题
更重要的是,让我们看看是不是收到了同样的警报邮件:
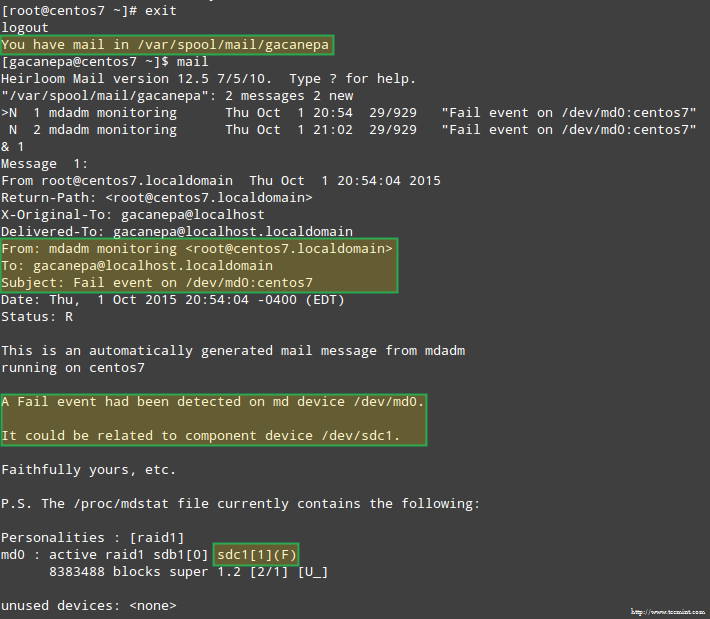
RAID 设备故障时发送邮件警报
在这种情况下,你需要从软件 RAID 阵列中删除该设备:
# mdadm /dev/md0 --remove /dev/sdc1
然后,你可以直接从机器中取出,并将其使用备用设备来取代(/dev/sdd 中类型为 fd 的分区是以前创建的):
# mdadm --manage /dev/md0 --add /dev/sdd1
幸运的是,该系统会使用我们刚才添加的磁盘自动重建阵列。我们可以通过标记 /dev/sdb1 为 faulty 来进行测试,从阵列中取出后,并确认 tecmint.txt 文件仍然在 /mnt/raid1 是可访问的:
# mdadm --detail /dev/md0
# mount | grep raid1
# ls -l /mnt/raid1 | grep tecmint
# cat /mnt/raid1/tecmint.txt
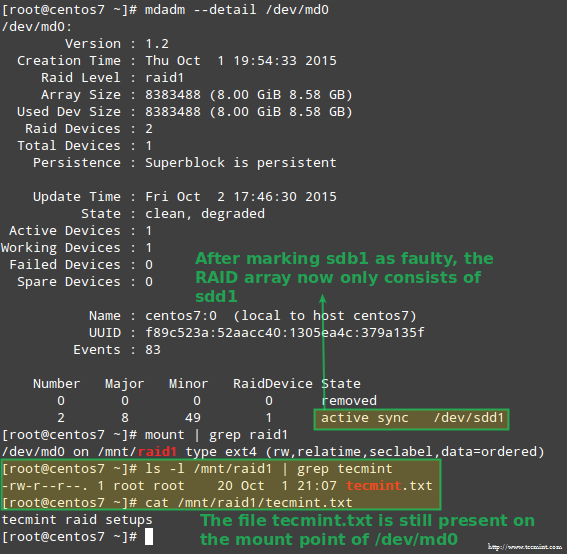
确认 RAID 重建
上面图片清楚的显示,添加 /dev/sdd1 到阵列中来替代 /dev/sdc1,数据的重建是系统自动完成的,不需要干预。
虽然要求不是很严格,有一个备用设备是个好主意,这样更换故障的设备就可以在瞬间完成了。要做到这一点,先让我们重新添加 /dev/sdb1 和 /dev/sdc1:
# mdadm --manage /dev/md0 --add /dev/sdb1
# mdadm --manage /dev/md0 --add /dev/sdc1
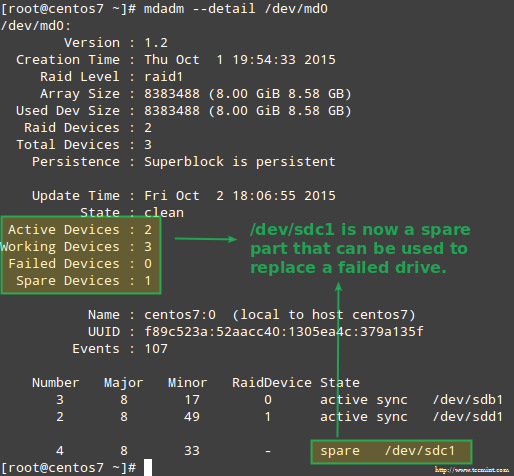
取代故障的 Raid 设备
从冗余丢失中恢复数据
如前所述,当一个磁盘发生故障时, mdadm 将自动重建数据。但是,如果阵列中的2个磁盘都故障时会发生什么?让我们来模拟这种情况,通过标记 /dev/sdb1 和 /dev/sdd1 为 faulty:
# umount /mnt/raid1
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
# mdadm --stop /dev/md0
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
此时尝试以同样的方式重新创建阵列就(或使用 --assume-clean 选项)可能会导致数据丢失,因此不到万不得已不要使用。
让我们试着从 /dev/sdb1 恢复数据,例如,在一个类似的磁盘分区(/dev/sde1 - 注意,这需要你执行前在/dev/sde 上创建一个 fd 类型的分区)上使用 ddrescue:
# ddrescue -r 2 /dev/sdb1 /dev/sde1
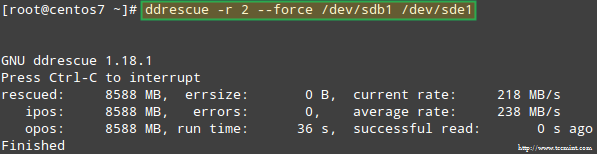
恢复 Raid 阵列
请注意,到现在为止,我们还没有触及 /dev/sdb 和 /dev/sdd,它们的分区是 RAID 阵列的一部分。
现在,让我们使用 /dev/sde1 和 /dev/sdf1 来重建阵列:
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
请注意,在真实的情况下,你需要使用与原来的阵列中相同的设备名称,即设备失效后替换的磁盘的名称应该是 /dev/sdb1 和 /dev/sdc1。
在本文中,我选择了使用额外的设备来重新创建全新的磁盘阵列,是为了避免与原来的故障磁盘混淆。
当被问及是否继续写入阵列时,键入 Y,然后按 Enter。阵列被启动,你也可以查看它的进展:
# watch -n 1 cat /proc/mdstat
当这个过程完成后,你就应该能够访问 RAID 的数据:
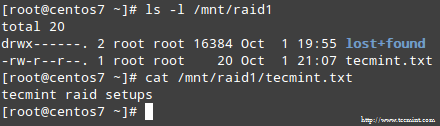
确认 Raid 数据
总结
在本文中,我们回顾了从 RAID 故障和冗余丢失中恢复数据。但是,你要记住,这种技术是一种存储解决方案,不能取代备份。
本文中介绍的方法适用于所有 RAID 中,其中的概念我将在本系列的最后一篇(RAID 管理)中涵盖它。
如果你对本文有任何疑问,随时给我们以评论的形式说明。我们期待倾听阁下的心声!
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
作者:Gabriel Cánepa 译者:strugglingyouth 校对:wxy


 );){kind=link}