大数据工具比较:R 语言和 Spark 谁更胜一筹?
| 2015-12-08 10:04 收藏: 2

本文有两重目的,一是在性能方面快速对比下R语言和Spark,二是想向大家介绍下Spark的机器学习库。
背景介绍
由于R语言本身是单线程的,所以可能从性能方面对比Spark和R并不是很明智的做法。即使这种比较不是很理想,但是对于那些曾经遇到过这些问题的人,下文中的一些数字一定会让你很感兴趣。
你是否曾把一个机器学习的问题丢到R里运行,然后等上好几个小时?而仅仅是因为没有可行的替代方式,你只能耐心地等。所以是时候去看看Spark的机器学习了,它包含R语言大部分的功能,并且在数据转换和性能上优于R语言。
曾经我尝试过利用不同的机器学习技术——R语言和Spark的机器学习,去解决同一个特定的问题。为了增加可比性,我甚至让它们运行在同样的硬件环境和操作系统上。并且,在Spark中运行单机模式,不带任何集群的配置。
在我们讨论具体细节之前,关于Revolution R 有个简单的说明。作为R语言的企业版,Revolution R试图弥补R语言单线程的缺陷。但它只能运行在像Revolution Analytics这样的专有软件上,所以可能不是理想的长期方案。如果想获得微软Revolution Analytics软件的扩展,又可能会让事情变得更为复杂,比方说牵扯到许可证的问题。
因此,社区支持的开源工具,像是Spark,可能成为比R语言企业版更好的选择。
数据集和问题
分析采用的是Kaggle网站 [译者注:Kaggle是一个数据分析的竞赛平台,网址: https://www.kaggle.com/ ]上的数字识别器的数据集,其中包含灰度的手写数字的图片,从0到9。
每张图片高28px,宽28px,大小为784px。每个像素都包含关于像素点明暗的值,值越高代表像素点越暗。像素值是0到255之间的整数,包括0和255。整张图片包含第一列在内共有785列数据,称为“标记”,即用户手写的数字。
分析的目标是得到一个可以从像素数值中识别数字是几的模型。
选择这个数据集的论据是,从数据量上来看,实质上这算不上是一个大数据的问题。
对比情况
针对这个问题,机器学习的步骤如下,以得出预测模型结束:
- 在数据集上进行主成分分析和线性判别式分析,得到主要的特征。(特征工程的步骤)[译者注:百度百科传送门,主成分分析、线性判别式分析]。
- 对所有双位数字进行二元逻辑回归,并且根据它们的像素信息和主成分分析以及线性判别式分析得到的特征变量进行分类。
- 在全量数据上运行多元逻辑回归模型来进行多类分类。根据它们的像素信息和主成分分析以及线性判别式分析的特征变量,利用朴素贝叶斯分类模型进行分类。利用决策树分类模型来分类数字。
在上述步骤之前,我已经将标记的数据分成了训练组和测试组,用于训练模型和在精度上验证模型的性能。
大部分的步骤都在R语言和Spark上都运行了。详细的对比情况如下,主要是对比了主成分分析、二元逻辑模型和朴素贝叶斯分类模型的部分。
主成分分析
主成分分析的主要计算复杂度在对成分的打分上,逻辑步骤如下:
- 通过遍历数据以及计算各列的协方差表,得到KxM的权重值。(K代表主成分的个数,M代表数据集的特征变量个数)。
- 当我们对N条数据进行打分,就是矩阵乘法运算。
- 通过NxM个维度数据和MxK个权重数据,最后得到的是NxK个主成分。N条数据中的每一条都有K个主成分。
在我们这个例子中,打分的结果是42000 x 784的维度矩阵与784 x 9的矩阵相乘。坦白说,这个计算过程在R中运行了超过4个小时,而同样的运算Spark只用了10秒多
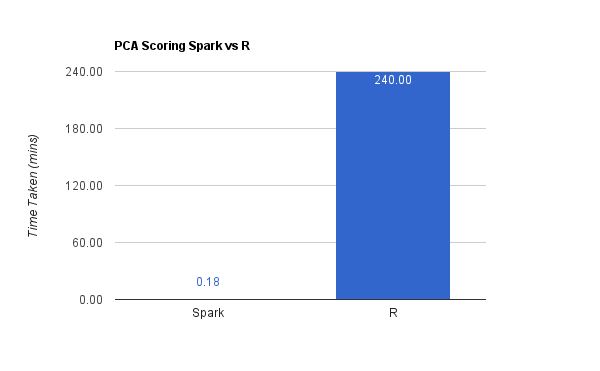
矩阵相乘差不多是3亿次运算或者指令,还有相当多的检索和查找操作,所以Spark的并行计算引擎可以在10秒钟完成还是非常令人惊讶的。
我通过查看前9个主成分的方差,来验证了所产生的主成分的精度。方差和通过R产生的前9个主成分的方差吻合。这一点确保了Spark并没有牺牲精度来换取性能和数据转换上的优势。
逻辑回归模型
与主成分分析不同的是,在逻辑回归模型中,训练和打分的操作都是需要计算的,而且都是极其密集的运算。在这种模型的通用的数据训练方案中包含一些对于整个数据集矩阵的转置和逆运算。
由于计算的复杂性,R在训练和打分都需要过好一会儿才能完成,准确的说是7个小时,而Spark只用了大概5分钟。
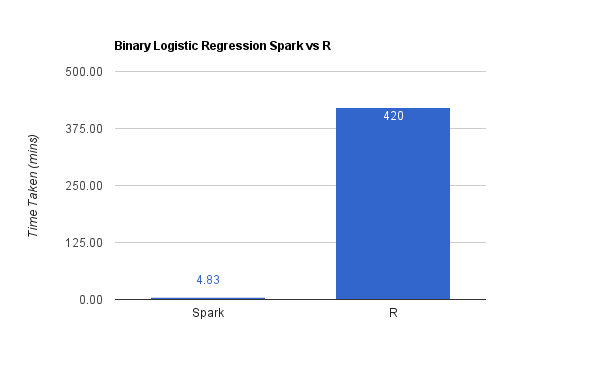
这里我在45个从0到9的双位数字上运行了二元逻辑回归模型,打分/验证也是在这45个测试数据上进行的。
我也并行执行了多元逻辑回归模型,作为多类分类器,大概3分钟就完成了。而这在R上运行不起来,所以我也没办法在数据上进行对比。
对于主成分分析,我采用AUC值 [译者注: AUC的值就是计算出ROC曲线下面的面积,是度量分类模型好坏的一个标准。] 来衡量预测模型在45对数据上的表现,而Spark和R两者运行的模型结果的AUC值差不多。
朴素贝叶斯分类器
与主成分分析和逻辑回归不一样的是,朴素贝叶斯分类器不是密集计算型的。其中需要计算类的先验概率,然后基于可用的附加数据得到后验概率。[译者注:先验概率是指根据以往经验和分析得到的概率,它往往作为”由因求果”问题中的”因”出现的概率;后验概率是指在得到“结果”的信息后重新修正的概率,是“执果寻因”问题中的”果”。]
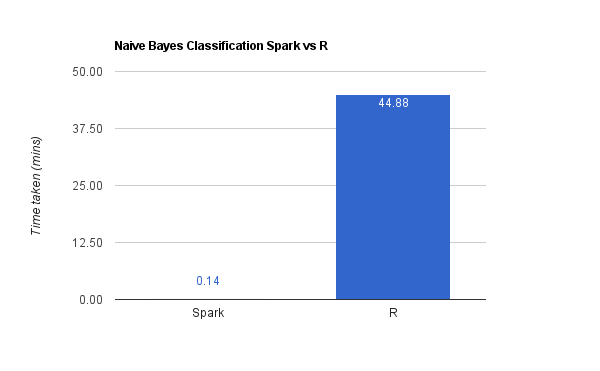
如上图所示,R大概花了45余秒完成,而Spark只用了9秒钟。像之前一样,两者的精确度旗鼓相当。
同时我也试着用Spark机器学习运行了决策树模型,大概花了20秒,而这个在R上完全运行不起来。
Spark机器学习入门指南
对比已经足够,而这也成就了Spark的机器学习。 最好是从编程指南开始学习它。不过,如果你想早点尝试并从实践中学习的话,你可能要痛苦一阵子才能将它运行起来吧。
为搞清楚示例代码并且在数据集上进行试验,你需要先去弄懂Spark的RDD [译者注:RDD,Resilient Distributed Datasets] 支持的基本框架和运算。然后也要弄明白Spark中不同的机器学习程序,并且在上面进行编程。当你的第一个Spark机器学习的程序跑起来的时候,你可能就会意兴阑珊了。
以下两份资料可以帮你避免这些问题,同时理顺学习的思路:
- Spark机器学习所有的源代码,可提供任何人拿来与R语言作对比:
https://github.com/vivekmurugesan/experiments/tree/master/spark-ml
- Docker容器的源代码,Spark和上述项目的包已预置在内,以供快速实施:
https://hub.docker.com/r/vivekmurugesan/spark-hadoop/ Docker容器中已事先安装Apache Hadoop,并且在伪分布式环境下运行。这可以将大容量文件放进分布式文件系统来测试Spark。通过从分布式文件系统加载记录,可以很轻松地来创建RDD实例。
产能和精度
人们会使用不同的指标来衡量这些工具的好坏。对我来说,精准度和产能是决定性的因素。
大家总是喜欢R多过于Spark机器学习,是因为经验学习曲线。他们最终只能选择在R上采用少量的样本数据,是因为R在大数据量的样本上花了太多时间,而这也影响了整个系统的性能。
对我来说,用少量的样本数据是解决不了问题的,因为少量样本根本代表不了整体(至少在大部分情况下是这样)。所以说,如果你使用了少量样本,就是在精度上选择了妥协。
一旦你抛弃了少量样本,就归结到了生产性能的问题。机器学习的问题本质上就是迭代的问题。如果每次迭代都花费很久的话,那么完工时间就会延长。可是,如果每次迭代只用一点时间的话,那么留给你敲代码的时间就会多一些了。
结论
R语言包含了统计计算的库和像ggplot2这样可视化分析的库,所以它不可能被完全废弃,而且它所带来的挖掘数据和统计汇总的能力是毋庸置疑的。
但是,当遇到在大数据集上构建模型的问题时,我们应该去挖掘一些像Spark ML的工具。Spark也提供R的包,SparkR可以在分布式数据集上应用R。
最好在你的“数据军营”中多放点工具,因为你不知道在“打仗”的时候会遇到什么。因此,是时候从过去的R时代迈入Spark ML的新时代了。

 );){kind=link}