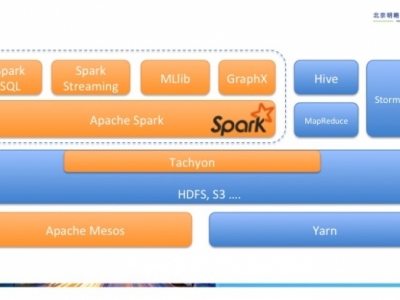
1、Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目。随着Spark在大数据计算领域的暂露头角,越来越多的企业开始关注和使用。2014年11月,Spark在Daytona Gray Sort 100TB Benchmark竞赛中打破了由Hadoop MapReduce保持的排序记录。Spark利用1/10的节点数,把100TB数据的排序时间从72分钟提高到了23分钟。 Spark在架构上包括内核部分和4个官方子模块--Spark SQL、Spark Streaming、机器学习库MLlib和图计算库GraphX。图1所示为Spark在伯克利的数据分析软件栈BDAS
2015-01-29 14:43 明略数据科学家 孟嘉

毋庸置疑,云计算将会在未来数据科学领域扮演至关重要的角色。弹性,可扩展性和按需分配的计算能力作为云计算的重要资源,直接导致云服务提供商集体火拼。其中最大的两股势力正是亚马逊网络服务(AWS) 和谷歌云平台(GCP)。
2016-09-30 08:49 Michael Li, Ariel M'Ndange-Pfupfu, firstadream

本文有两重目的,一是在性能方面快速对比下R语言和Spark,二是想向大家介绍下Spark的机器学习库。 背景介绍 由于R语言本身是单线程的,所以可能从性能方面对比Spark和R并不是很明智的做法。即使这种比较不是很理想,但是对于那些曾经遇到过这些问题的人,下文中的一些数字一定会让你很感兴趣。 你是否曾把一个机器学习的问题丢到R里运行,然后等上好几个小时?而仅仅是因为没有可行的替代方式,你只能耐心地等。所以是时候去看看Spark的机器学习了,它包含R语言大部分的功能,并且在数据转换和性能上优于R语言。 曾经我尝试过利用不同的机
2015-12-08 10:04 Vivek Murugesan, 冷逸

Apache Spark 于 2009 年在加州大学伯克利分校的 AMPLab 由 Matei Zaharia 发起,后来在2013 年贡献给 Apache。它是目前增长最快的数据处理平台之一,由于它能支持流、批量、命令式(RDD)、声明式(SQL)、图数据库和机器学习等用例,而且所有这些都内置在相同的 API 和底层计算引擎中。
2017-06-23 09:55 Sital Kedia, 王硕杰, Avery Ching

Apache Cassandra 数据库近来引起了很多的兴趣,这主要源于现代云端软件对于可用性及性能方面的要求。
2016-07-17 17:35 Jon Haddad, KevinSJ

这些数据分析项目大行其道:Grappa、Apache Drill 和 Apache Kafka
2016-06-23 08:41 SAM DEAN, 布加迪

• 微软宣布 WSL2 对 GPU 的初始支持 • Apache Spark 3.0 发布 • 红帽和 Fedora 社区共同改进模块化,将应用到 RHEL 9
2020-06-22 11:24 硬核老王

在极短的时间内,Apache Spark 迅速成长为大数据分析的技术核心。这就使得保守派担心在这个技术更新如此之快的年代它是否会同样快的被淘汰呢。我反而却坚信,spark仅仅是崭露头角。 在过去的几年时间,随着Hadoop技术爆炸和大数据逐渐占据主流地位,几件事情逐渐明晰: 对所有数据而言,Hadoop分布式文件系统(HDFS)是一个直接存储平台。 YARN(负责资源分配和管理)是大数据环境下一个适用的架构。 或许是最为重要的一点,目前并不存在一个能解决所有问题的框架结构。尽管MapReduce是一项非常了不起的技术,但是它仍不能解决所有问题。
2015-08-27 10:09 Peter Schlampp, 刘崇鑫

Spark是一款Zenithink C71 Android平板,设计简洁、线条流畅,拥有坚固的机身和良好的做工。它配备了1GHz的ARM处理器,512MB的RAM,4GB内置存储以及7英寸的电容式多点触摸液晶显示屏,像素为800x840。 Spark平板电脑 ...
2012-02-21 17:17

Spark SQL 是 Spark 生态系统中处理结构化格式数据的模块。它在内部使用 Spark Core API 进行处理,但对用户的使用进行了抽象。这篇文章深入浅出地告诉你 Spark SQL 3.x 的新内容。
2022-05-24 09:30 Phani Kiran, geekpi
分享到微信
打开微信,点击顶部的“╋”,
使用“扫一扫”将网页分享至微信。
 标签:
标签: