一个使用 asyncio 协程的网络爬虫(三)
| 2017-03-06 10:31 收藏: 1
本文作者:
A. Jesse Jiryu Davis 是纽约 MongoDB 的工程师。他编写了异步 MongoDB Python 驱动程序 Motor,也是 MongoDB C 驱动程序的开发领袖和 PyMongo 团队成员。 他也为 asyncio 和 Tornado 做了贡献,在 http://emptysqua.re 上写作。
Guido van Rossum 是主流编程语言 Python 的创造者,Python 社区称他为 BDFL (仁慈的终生大独裁者 (Benevolent Dictator For Life))——这是一个来自 Monty Python 短剧的称号。他的主页是 http://www.python.org/~guido/ 。
使用协程
我们将从描述爬虫如何工作开始。现在是时候用 asynio 去实现它了。
我们的爬虫从获取第一个网页开始,解析出链接并把它们加到队列中。此后它开始傲游整个网站,并发地获取网页。但是由于客户端和服务端的负载限制,我们希望有一个最大数目的运行的 worker,不能再多。任何时候一个 worker 完成一个网页的获取,它应该立即从队列中取出下一个链接。我们会遇到没有那么多事干的时候,所以一些 worker 必须能够暂停。一旦又有 worker 获取一个有很多链接的网页,队列会突增,暂停的 worker 立马被唤醒干活。最后,当任务完成后我们的程序必须马上退出。
假如你的 worker 是线程,怎样去描述你的爬虫算法?我们可以使用 Python 标准库中的同步队列。每次有新的一项加入,队列增加它的 “tasks” 计数器。线程 worker 完成一个任务后调用 task_done。主线程阻塞在 Queue.join,直到“tasks”计数器与 task_done 调用次数相匹配,然后退出。
协程通过 asyncio 队列,使用和线程一样的模式来实现!首先我们导入它:
try:
from asyncio import JoinableQueue as Queue
except ImportError:
# In Python 3.5, asyncio.JoinableQueue is
# merged into Queue.
from asyncio import Queue
我们把 worker 的共享状态收集在一个 crawler 类中,主要的逻辑写在 crawl 方法中。我们在一个协程中启动 crawl,运行 asyncio 的事件循环直到 crawl 完成:
loop = asyncio.get_event_loop()
crawler = crawling.Crawler('http://xkcd.com',
max_redirect=10)
loop.run_until_complete(crawler.crawl())
crawler 用一个根 URL 和最大重定向数 max_redirect 来初始化,它把 (URL, max_redirect) 序对放入队列中。(为什么要这样做,请看下文)
class Crawler:
def __init__(self, root_url, max_redirect):
self.max_tasks = 10
self.max_redirect = max_redirect
self.q = Queue()
self.seen_urls = set()
# aiohttp's ClientSession does connection pooling and
# HTTP keep-alives for us.
self.session = aiohttp.ClientSession(loop=loop)
# Put (URL, max_redirect) in the queue.
self.q.put((root_url, self.max_redirect))
现在队列中未完成的任务数是 1。回到我们的主程序,启动事件循环和 crawl 方法:
loop.run_until_complete(crawler.crawl())
crawl 协程把 worker 们赶起来干活。它像一个主线程:阻塞在 join 上直到所有任务完成,同时 worker 们在后台运行。
@asyncio.coroutine
def crawl(self):
"""Run the crawler until all work is done."""
workers = [asyncio.Task(self.work())
for _ in range(self.max_tasks)]
# When all work is done, exit.
yield from self.q.join()
for w in workers:
w.cancel()
如果 worker 是线程,可能我们不会一次把它们全部创建出来。为了避免创建线程的昂贵代价,通常一个线程池会按需增长。但是协程很廉价,我们可以直接把他们全部创建出来。
怎么关闭这个 crawler 很有趣。当 join 完成,worker 存活但是被暂停:他们等待更多的 URL,所以主协程要在退出之前清除它们。否则 Python 解释器关闭并调用所有对象的析构函数时,活着的 worker 会哭喊到:
ERROR:asyncio:Task was destroyed but it is pending!
cancel 又是如何工作的呢?生成器还有一个我们还没介绍的特点。你可以从外部抛一个异常给它:
>>> gen = gen_fn()
>>> gen.send(None) # Start the generator as usual.
1
>>> gen.throw(Exception('error'))
Traceback (most recent call last):
File "<input>", line 3, in <module>
File "<input>", line 2, in gen_fn
Exception: error
生成器被 throw 恢复,但是它现在抛出一个异常。如过生成器的调用堆栈中没有捕获异常的代码,这个异常被传递到顶层。所以注销一个协程:
# Method of Task class.
def cancel(self):
self.coro.throw(CancelledError)
任何时候生成器暂停,在某些 yield from 语句它恢复并且抛出一个异常。我们在 task 的 step 方法中处理注销。
# Method of Task class.
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration:
return
next_future.add_done_callback(self.step)
现在 task 知道它被注销了,所以当它被销毁时,它不再抱怨。
一旦 crawl 注销了 worker,它就退出。同时事件循环看见这个协程结束了(我们后面会见到的),也就退出。
loop.run_until_complete(crawler.crawl())
crawl 方法包含了所有主协程需要做的事。而 worker 则完成从队列中获取 URL、获取网页、解析它们得到新的链接。每个 worker 独立地运行 work 协程:
@asyncio.coroutine
def work(self):
while True:
url, max_redirect = yield from self.q.get()
# Download page and add new links to self.q.
yield from self.fetch(url, max_redirect)
self.q.task_done()
Python 看见这段代码包含 yield from 语句,就把它编译成生成器函数。所以在 crawl 方法中,我们调用了 10 次 self.work,但并没有真正执行,它仅仅创建了 10 个指向这段代码的生成器对象并把它们包装成 Task 对象。task 接收每个生成器所 yield 的 future,通过调用 send 方法,当 future 解决时,用 future 的结果做为 send 的参数,来驱动它。由于生成器有自己的栈帧,它们可以独立运行,带有独立的局部变量和指令指针。
worker 使用队列来协调其小伙伴。它这样等待新的 URL:
url, max_redirect = yield from self.q.get()
队列的 get 方法自身也是一个协程,它一直暂停到有新的 URL 进入队列,然后恢复并返回该条目。
碰巧,这也是当主协程注销 worker 时,最后 crawl 停止,worker 协程暂停的地方。从协程的角度,yield from 抛出CancelledError 结束了它在循环中的最后旅程。
worker 获取一个网页,解析链接,把新的链接放入队列中,接着调用task_done减小计数器。最终一个worker遇到一个没有新链接的网页,并且队列里也没有任务,这次task_done的调用使计数器减为0,而crawl正阻塞在join方法上,现在它就可以结束了。
我们承诺过要解释为什么队列中要使用序对,像这样:
# URL to fetch, and the number of redirects left.
('http://xkcd.com/353', 10)
新的 URL 的重定向次数是10。获取一个特别的 URL 会重定向一个新的位置。我们减小重定向次数,并把新的 URL 放入队列中。
# URL with a trailing slash. Nine redirects left.
('http://xkcd.com/353/', 9)
我们使用的 aiohttp 默认会跟踪重定向并返回最终结果。但是,我们告诉它不要这样做,爬虫自己来处理重定向,以便它可以合并那些目的相同的重定向路径:如果我们已经在 self.seen_urls 看到一个 URL,说明它已经从其他的地方走过这条路了。
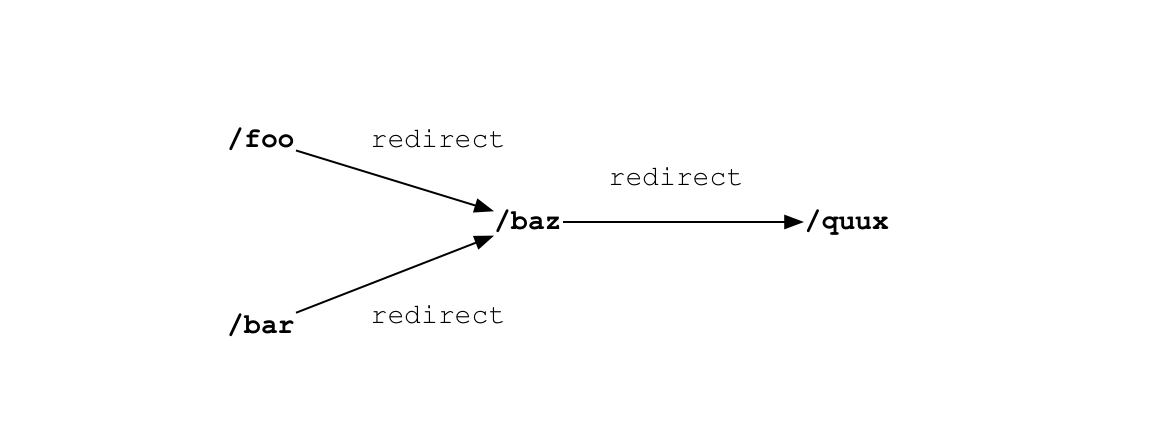
crawler 获取“foo”并发现它重定向到了“baz”,所以它会加“baz”到队列和 seen_urls 中。如果它获取的下一个页面“bar” 也重定向到“baz”,fetcher 不会再次将 “baz”加入到队列中。如果该响应是一个页面,而不是一个重定向,fetch 会解析它的链接,并把新链接放到队列中。
@asyncio.coroutine
def fetch(self, url, max_redirect):
# Handle redirects ourselves.
response = yield from self.session.get(
url, allow_redirects=False)
try:
if is_redirect(response):
if max_redirect > 0:
next_url = response.headers['location']
if next_url in self.seen_urls:
# We have been down this path before.
return
# Remember we have seen this URL.
self.seen_urls.add(next_url)
# Follow the redirect. One less redirect remains.
self.q.put_nowait((next_url, max_redirect - 1))
else:
links = yield from self.parse_links(response)
# Python set-logic:
for link in links.difference(self.seen_urls):
self.q.put_nowait((link, self.max_redirect))
self.seen_urls.update(links)
finally:
# Return connection to pool.
yield from response.release()
如果这是多进程代码,就有可能遇到讨厌的竞争条件。比如,一个 worker 检查一个链接是否在 seen_urls 中,如果没有它就把这个链接加到队列中并把它放到 seen_urls 中。如果它在这两步操作之间被中断,而另一个 worker 解析到相同的链接,发现它并没有出现在 seen_urls 中就把它加入队列中。这(至少)导致同样的链接在队列中出现两次,做了重复的工作和错误的统计。
然而,一个协程只在 yield from 时才会被中断。这是协程比多线程少遇到竞争条件的关键。多线程必须获得锁来明确的进入一个临界区,否则它就是可中断的。而 Python 的协程默认是不会被中断的,只有它明确 yield 时才主动放弃控制权。
我们不再需要在用回调方式时用的 fetcher 类了。这个类只是不高效回调的一个变通方法:在等待 I/O 时,它需要一个存储状态的地方,因为局部变量并不能在函数调用间保留。倒是 fetch 协程可以像普通函数一样用局部变量保存它的状态,所以我们不再需要一个类。
当 fetch 完成对服务器响应的处理,它返回到它的调用者 work。work 方法对队列调用 task_done,接着从队列中取出一个要获取的 URL。
当 fetch 把新的链接放入队列中,它增加未完成的任务计数器,并停留在主协程,主协程在等待 q.join,处于暂停状态。而当没有新的链接并且这是队列中最后一个 URL 时,当 work 调用task_done,任务计数器变为 0,主协程从join` 中退出。
与 worker 和主协程一起工作的队列代码像这样(实际的 asyncio.Queue 实现在 Future 所展示的地方使用 asyncio.Event 。不同之处在于 Event 是可以重置的,而 Future 不能从已解决返回变成待决。)
class Queue:
def __init__(self):
self._join_future = Future()
self._unfinished_tasks = 0
# ... other initialization ...
def put_nowait(self, item):
self._unfinished_tasks += 1
# ... store the item ...
def task_done(self):
self._unfinished_tasks -= 1
if self._unfinished_tasks == 0:
self._join_future.set_result(None)
@asyncio.coroutine
def join(self):
if self._unfinished_tasks > 0:
yield from self._join_future
主协程 crawl yield from join。所以当最后一个 worker 把计数器减为 0,它告诉 crawl 恢复运行并结束。
旅程快要结束了。我们的程序从 crawl 调用开始:
loop.run_until_complete(self.crawler.crawl())
程序如何结束?因为 crawl 是一个生成器函数,调用它返回一个生成器。为了驱动它,asyncio 把它包装成一个 task:
class EventLoop:
def run_until_complete(self, coro):
"""Run until the coroutine is done."""
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
class StopError(BaseException):
"""Raised to stop the event loop."""
def stop_callback(future):
raise StopError当这个任务完成,它抛出 StopError,事件循环把这个异常当作正常退出的信号。
但是,task 的 add_done_callbock 和 result 方法又是什么呢?你可能认为 task 就像一个 future,不错,你的直觉是对的。我们必须承认一个向你隐藏的细节,task 是 future。
class Task(Future):
"""A coroutine wrapped in a Future."""通常,一个 future 被别人调用 set_result 解决。但是 task,当协程结束时,它自己解决自己。记得我们解释过当 Python 生成器返回时,它抛出一个特殊的 StopIteration 异常:
# Method of class Task.
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration as exc:
# Task resolves itself with coro's return
# value.
self.set_result(exc.value)
return
next_future.add_done_callback(self.step)
所以当事件循环调用 task.add_done_callback(stop_callback),它就准备被这个 task 停止。在看一次run_until_complete:
# Method of event loop.
def run_until_complete(self, coro):
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
当 task 捕获 StopIteration 并解决自己,这个回调从循环中抛出 StopError。循环结束,调用栈回到run_until_complete。我们的程序结束。
总结
现代的程序越来越多是 I/O 密集型而不是 CPU 密集型。对于这样的程序,Python 的线程在两个方面不合适:全局解释器锁阻止真正的并行计算,并且抢占切换也导致他们更容易出现竞争。异步通常是正确的选择。但是随着基于回调的异步代码增加,它会变得非常混乱。协程是一个更整洁的替代者。它们自然地重构成子过程,有健全的异常处理和栈追溯。
如果我们换个角度看 yield from 语句,一个协程看起来像一个传统的做阻塞 I/O 的线程。甚至我们可以采用经典的多线程模式编程,不需要重新发明。因此,与回调相比,协程更适合有经验的多线程的编码者。
但是当我们睁开眼睛关注 yield from 语句,我们能看到协程放弃控制权、允许其它人运行的标志点。不像多线程,协程展示出我们的代码哪里可以被中断哪里不能。在 Glyph Lefkowitz 富有启发性的文章“Unyielding”:“线程让局部推理变得困难,然而局部推理可能是软件开发中最重要的事”。然而,明确的 yield,让“通过过程本身而不是整个系统理解它的行为(和因此、正确性)”成为可能。
这章写于 Python 和异步的复兴时期。你刚学到的基于生成器的的协程,在 2014 年发布在 Python 3.4 的 asyncio 模块中。2015 年 9 月,Python 3.5 发布,协程成为语言的一部分。这个原生的协程通过“async def”来声明, 使用“await”而不是“yield from”委托一个协程或者等待 Future。
除了这些优点,核心的思想不变。Python 新的原生协程与生成器只是在语法上不同,工作原理非常相似。事实上,在 Python 解释器中它们共用同一个实现方法。Task、Future 和事件循环在 asynico 中扮演着同样的角色。
你已经知道 asyncio 协程是如何工作的了,现在你可以忘记大部分的细节。这些机制隐藏在一个整洁的接口下。但是你对这基本原理的理解能让你在现代异步环境下正确而高效的编写代码。
(题图素材来自:ruth-tay.deviantart.com)
via: http://aosabook.org/en/500L/pages/a-web-crawler-with-asyncio-coroutines.html
作者:A. Jesse Jiryu Davis , Guido van Rossum 译者:qingyunha 校对:wxy


 );){kind=link}