并发服务器(二):线程
| 2017-10-26 08:19 收藏: 3
这是并发网络服务器系列的第二节。第一节 提出了服务端实现的协议,还有简单的顺序服务器的代码,是这整个系列的基础。
这一节里,我们来看看怎么用多线程来实现并发,用 C 实现一个最简单的多线程服务器,和用 Python 实现的线程池。
该系列的所有文章:
多线程的方法设计并发服务器
说起第一节里的顺序服务器的性能,最显而易见的,是在服务器处理客户端连接时,计算机的很多资源都被浪费掉了。尽管假定客户端快速发送完消息,不做任何等待,仍然需要考虑网络通信的开销;网络要比现在的 CPU 慢上百万倍还不止,因此 CPU 运行服务器时会等待接收套接字的流量,而大量的时间都花在完全不必要的等待中。
这里是一份示意图,表明顺序时客户端的运行过程:
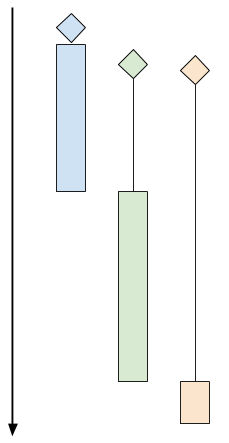
这个图片上有 3 个客户端程序。棱形表示客户端的“到达时间”(即客户端尝试连接服务器的时间)。黑色线条表示“等待时间”(客户端等待服务器真正接受连接所用的时间),有色矩形表示“处理时间”(服务器和客户端使用协议进行交互所用的时间)。有色矩形的末端表示客户端断开连接。
上图中,绿色和橘色的客户端尽管紧跟在蓝色客户端之后到达服务器,也要等到服务器处理完蓝色客户端的请求。这时绿色客户端得到响应,橘色的还要等待一段时间。
多线程服务器会开启多个控制线程,让操作系统管理 CPU 的并发(使用多个 CPU 核心)。当客户端连接的时候,创建一个线程与之交互,而在主线程中,服务器能够接受其他的客户端连接。下图是该模式的时间轴:
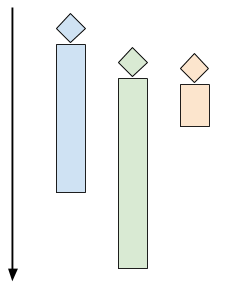
每个客户端一个线程,在 C 语言里要用 pthread
这篇文章的 第一个示例代码 是一个简单的 “每个客户端一个线程” 的服务器,用 C 语言编写,使用了 phtreads API 用于实现多线程。这里是主循环代码:
while (1) {
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd =
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
pthread_t the_thread;
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
if (!config) {
die("OOM");
}
config->sockfd = newsockfd;
pthread_create(&the_thread, NULL, server_thread, config);
// 回收线程 —— 在线程结束的时候,它占用的资源会被回收
// 因为主线程在一直运行,所以它比服务线程存活更久。
pthread_detach(the_thread);
}
这是 server_thread 函数:
void* server_thread(void* arg) {
thread_config_t* config = (thread_config_t*)arg;
int sockfd = config->sockfd;
free(config);
// This cast will work for Linux, but in general casting pthread_id to an 这个类型转换在 Linux 中可以正常运行,但是一般来说将 pthread_id 类型转换成整形不便于移植代码
// integral type isn't portable.
unsigned long id = (unsigned long)pthread_self();
printf("Thread %lu created to handle connection with socket %d\n", id,
sockfd);
serve_connection(sockfd);
printf("Thread %lu done\n", id);
return 0;
}
线程 “configuration” 是作为 thread_config_t 结构体进行传递的:
typedef struct { int sockfd; } thread_config_t;
主循环中调用的 pthread_create 产生一个新线程,然后运行 server_thread 函数。这个线程会在 server_thread 返回的时候结束。而在 serve_connection 返回的时候 server_thread 才会返回。serve_connection 和第一节完全一样。
第一节中我们用脚本生成了多个并发访问的客户端,观察服务器是怎么处理的。现在来看看多线程服务器的处理结果:
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-20 06:31:56,632:conn1 connected...
INFO:2017-09-20 06:31:56,632:conn2 connected...
INFO:2017-09-20 06:31:56,632:conn0 connected...
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
实际上,所有客户端同时连接,它们与服务器的通信是同时发生的。
每个客户端一个线程的难点
尽管在现代操作系统中就资源利用率方面来看,线程相当的高效,但前一节中讲到的方法在高负载时却会出现纰漏。
想象一下这样的情景:很多客户端同时进行连接,某些会话持续的时间长。这意味着某个时刻服务器上有很多活跃的线程。太多的线程会消耗掉大量的内存和 CPU 资源,而仅仅是用于上下文切换注1 。另外其也可视为安全问题:因为这样的设计容易让服务器成为 DoS 攻击 的目标 —— 上百万个客户端同时连接,并且客户端都处于闲置状态,这样耗尽了所有资源就可能让服务器宕机。
当服务器要与每个客户端通信,CPU 进行大量计算时,就会出现更严重的问题。这种情况下,容易想到的方法是减少服务器的响应能力 —— 只有其中一些客户端能得到服务器的响应。
因此,对多线程服务器所能够处理的并发客户端数做一些 速率限制 就是个明智的选择。有很多方法可以实现。最容易想到的是计数当前已经连接上的客户端,把连接数限制在某个范围内(需要通过仔细的测试后决定)。另一种流行的多线程应用设计是使用 线程池。
线程池
线程池 很简单,也很有用。服务器创建几个任务线程,这些线程从某些队列中获取任务。这就是“池”。然后每一个客户端的连接被当成任务分发到池中。只要池中有空闲的线程,它就会去处理任务。如果当前池中所有线程都是繁忙状态,那么服务器就会阻塞,直到线程池可以接受任务(某个繁忙状态的线程处理完当前任务后,变回空闲的状态)。
这里有个 4 线程的线程池处理任务的图。任务(这里就是客户端的连接)要等到线程池中的某个线程可以接受新任务。
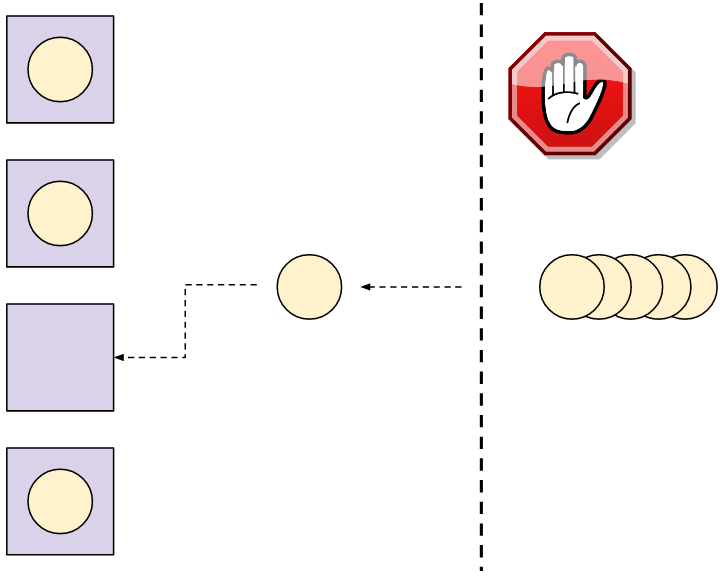
非常明显,线程池的定义就是一种按比例限制的机制。我们可以提前设定服务器所能拥有的线程数。那么这就是并发连接的最多的客户端数 —— 其它的客户端就要等到线程空闲。如果我们的池中有 8 个线程,那么 8 就是服务器可以处理的最多的客户端并发连接数,哪怕上千个客户端想要同时连接。
那么怎么确定池中需要有多少个线程呢?通过对问题范畴进行细致的分析、评估、实验以及根据我们拥有的硬件配置。如果是单核的云服务器,答案只有一个;如果是 100 核心的多套接字的服务器,那么答案就有很多种。也可以在运行时根据负载动态选择池的大小 —— 我会在这个系列之后的文章中谈到这个东西。
使用线程池的服务器在高负载情况下表现出 性能退化 —— 客户端能够以稳定的速率进行连接,可能会比其它时刻得到响应的用时稍微久一点;也就是说,无论多少个客户端同时进行连接,服务器总能保持响应,尽最大能力响应等待的客户端。与之相反,每个客户端一个线程的服务器,会接收多个客户端的连接直到过载,这时它更容易崩溃或者因为要处理所有客户端而变得缓慢,因为资源都被耗尽了(比如虚拟内存的占用)。
在服务器上使用线程池
为了改变服务器的实现,我用了 Python,在 Python 的标准库中带有一个已经实现好的稳定的线程池。(concurrent.futures 模块里的 ThreadPoolExecutor) 注2 。
服务器创建一个线程池,然后进入循环,监听套接字接收客户端的连接。用 submit 把每一个连接的客户端分配到池中:
pool = ThreadPoolExecutor(args.n)
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sockobj.bind(('localhost', args.port))
sockobj.listen(15)
try:
while True:
client_socket, client_address = sockobj.accept()
pool.submit(serve_connection, client_socket, client_address)
except KeyboardInterrupt as e:
print(e)
sockobj.close()
serve_connection 函数和 C 的那部分很像,与一个客户端交互,直到其断开连接,并且遵循我们的协议:
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
def serve_connection(sockobj, client_address):
print('{0} connected'.format(client_address))
sockobj.sendall(b'*')
state = ProcessingState.WAIT_FOR_MSG
while True:
try:
buf = sockobj.recv(1024)
if not buf:
break
except IOError as e:
break
for b in buf:
if state == ProcessingState.WAIT_FOR_MSG:
if b == ord(b'^'):
state = ProcessingState.IN_MSG
elif state == ProcessingState.IN_MSG:
if b == ord(b'$'):
state = ProcessingState.WAIT_FOR_MSG
else:
sockobj.send(bytes([b + 1]))
else:
assert False
print('{0} done'.format(client_address))
sys.stdout.flush()
sockobj.close()
来看看线程池的大小对并行访问的客户端的阻塞行为有什么样的影响。为了演示,我会运行一个池大小为 2 的线程池服务器(只生成两个线程用于响应客户端)。
$ python3.6 threadpool-server.py -n 2
在另外一个终端里,运行客户端模拟器,产生 3 个并发访问的客户端:
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-22 05:58:52,815:conn1 connected...
INFO:2017-09-22 05:58:52,827:conn0 connected...
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
INFO:2017-09-22 05:58:55,032:conn2 connected...
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
回顾之前讨论的服务器行为:
- 在顺序服务器中,所有的连接都是串行的。一个连接结束后,下一个连接才能开始。
- 前面讲到的每个客户端一个线程的服务器中,所有连接都被同时接受并得到服务。
这里可以看到一种可能的情况:两个连接同时得到服务,只有其中一个结束连接后第三个才能连接上。这就是把线程池大小设置成 2 的结果。真实用例中我们会把线程池设置的更大些,取决于机器和实际的协议。线程池的缓冲机制就能很好理解了 —— 我 几个月前 更详细的介绍过这种机制,关于 Clojure 的 core.async 模块。
总结与展望
这篇文章讨论了在服务器中,用多线程作并发的方法。每个客户端一个线程的方法最早提出来,但是实际上却不常用,因为它并不安全。
线程池就常见多了,最受欢迎的几个编程语言有良好的实现(某些编程语言,像 Python,就是在标准库中实现)。这里说的使用线程池的服务器,不会受到每个客户端一个线程的弊端。
然而,线程不是处理多个客户端并行访问的唯一方法。下一节中我们会看看其它的解决方案,可以使用异步处理,或者事件驱动的编程。
- 注1:老实说,现代 Linux 内核可以承受足够多的并发线程 —— 只要这些线程主要在 I/O 上被阻塞。这里有个示例程序,它产生可配置数量的线程,线程在循环体中是休眠的,每 50 ms 唤醒一次。我在 4 核的 Linux 机器上可以轻松的产生 10000 个线程;哪怕这些线程大多数时间都在睡眠,它们仍然消耗一到两个核心,以便实现上下文切换。而且,它们占用了 80 GB 的虚拟内存(Linux 上每个线程的栈大小默认是 8MB)。实际使用中,线程会使用内存并且不会在循环体中休眠,因此它可以非常快的占用完一个机器的内存。
- 注2:自己动手实现一个线程池是个有意思的练习,但我现在还不想做。我曾写过用来练手的 针对特殊任务的线程池。是用 Python 写的;用 C 重写的话有些难度,但对于经验丰富的程序员,几个小时就够了。
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
作者:Eli Bendersky 译者:GitFuture 校对:wxy


 );){kind=link}