Linux 跟踪器之选
| 2018-03-09 12:55 收藏: 5
Linux 跟踪很神奇!
跟踪器是一个高级的性能分析和调试工具,如果你使用过 strace(1) 或者 tcpdump(8),你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
你喜欢使用哪一个呢?
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
对于大多数人
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
1. 使用 perf_events 进行 CPU 剖析
可以使用 perf_events 进行 CPU 剖析。它可以用一个 火焰图 来形象地表示。比如:
git clone --depth 1 https://github.com/brendangregg/FlameGraph
perf record -F 99 -a -g -- sleep 30
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg

Linux 的 perf_events(即 perf,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
perf 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是采样。最难的部分是获得完整的栈和符号,这部分在我的 Linux Profiling at Netflix 中针对 Java 和 Node.js 讨论过。
2. 知道它能干什么
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 ftrace 的文章,也可以去浏览 perf_events 页面,那里有一些跟踪(和剖析)能力的示例。
3. 需要一个前端工具
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 Monitorama 演讲 中描述的那样。
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 perf-tools,跟踪新进程是这样的:
# ./execsnoop
Tracing exec()s. Ctrl-C to end.
PID PPID ARGS
22898 22004 man ls
22905 22898 preconv -e UTF-8
22908 22898 pager -s
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
[...]
在 Netflix 公司,我正在开发 Vector,它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
对于性能或者内核工程师
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
在这里我建议选择如下,要么:
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 源代码 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 sysdig 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
B)按我的 Velocity 教程中 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
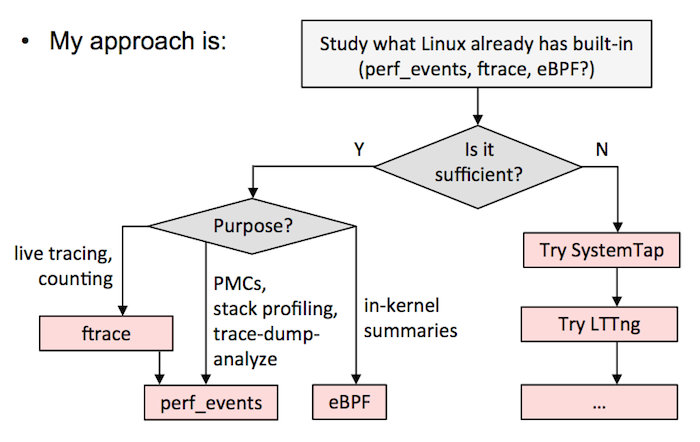
以下是我对各个跟踪器的评价:
1. ftrace
我爱 ftrace,它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;函数流步进。关于它的示例可以查看内核源代码树中的 ftrace.txt。它通过 /sys 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易调校,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是可编程的,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
2. perf_events
perf_events 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 perf,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用调试信息进行行级跟踪。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
3. eBPF
扩展的伯克利包过滤器(eBPF)是一个内核内的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供内核内编程,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的延迟热力图。更多参考资料,请查阅 Alexei 的 BPF 演示,和它的 eBPF 示例。
4. SystemTap
SystemTap 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
5. LTTng
LTTng 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
6. ktap
ktap 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
7. dtrace4linux
dtrace4linux 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些供应器可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
8. OL DTrace
Oracle Linux DTrace 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
9. sysdig
sysdig 是一个很新的跟踪器,它可以使用类似 tcpdump 的语法来处理系统调用事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
深入阅读
我自己的工作中使用到的跟踪器包括:
- ftrace : 我的 perf-tools 集合(查看示例目录);我的 lwn.net 的 ftrace 跟踪器的文章; 一个 LISA14 演讲;以及帖子: 函数计数、 iosnoop、 opensnoop、 execsnoop、 TCP retransmits、 uprobes 和 USDT。
- perf_events : 我的 perf_events 示例 页面;在 SCALE 的一个 Linux Profiling at Netflix 演讲;和帖子:CPU 采样、静态跟踪点、热力图、计数、内核行级跟踪、off-CPU 时间火焰图。
- eBPF : 帖子 eBPF:一个小的进步,和一些 BPF-tools (我需要发布更多)。
- SystemTap : 很久以前,我写了一篇 使用 SystemTap 的文章,它有点过时了。最近我发布了一些 systemtap-lwtools,展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
- LTTng : 我使用它的时间很短,不足以发布什么文章。
- ktap : 我的 ktap 示例 页面包括一行程序和脚本,虽然它是早期的版本。
- dtrace4linux : 在我的 系统性能 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, timestamps。
- OL DTrace : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 我的主页 上搜索)。一旦它更加完美,我可以开发很多专用工具。
- sysdig : 我贡献了 fileslower 和 subsecond offset spectrogram 的 chisel。
- 其它 : 关于 strace,我写了一些告诫文章。
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 从 DTrace 到 Linux 的演讲中有答案,从 第 28 张幻灯片 开始。
感谢 Deirdre Straughan 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
作者:Brendan Gregg 译者:qhwdw 校对:wxy


 );){kind=link}