使用 Graylog 和 Prometheus 监视 Kubernetes 集群
| 2018-04-10 18:28 收藏: 2
这篇文章最初发表在 Kevin Monroe 的博客 上。
监视日志和指标状态是集群管理员的重点工作。它的好处很明显:指标能帮你设置一个合理的性能目标,而日志分析可以发现影响你工作负载的问题。然而,困难的是如何找到一个与大量运行的应用程序一起工作的监视解决方案。
在本文中,我将使用 Graylog (用于日志)和 Prometheus (用于指标)去打造一个 Kubernetes 集群的监视解决方案。当然了,这不仅是将三个东西连接起来那么简单,实现上,最终结果看起来应该如题图所示:
正如你所了解的,Kubernetes 不是一件东西 —— 它由主控节点、工作节点、网络连接、配置管理等等组成。同样,Graylog 是一个配角(apache2、mongodb、等等),Prometheus 也一样(telegraf、grafana 等等)。在部署中连接这些点看起来似乎有些让人恐惧,但是使用合适的工具将不会那么困难。
我将使用 conjure-up 和 Canonical 版本的 Kubernetes (CDK) 去探索 Kubernetes。我发现 conjure-up 接口对部署大型软件很有帮助,但是我知道一些人可能不喜欢 GUI、TUI 以及其它用户界面。对于这些人,我将用命令行再去部署一遍。
在开始之前需要注意的一点是,Graylog 和 Prometheus 是部署在 Kubernetes 外侧而不是集群上。像 Kubernetes 仪表盘和 Heapster 是运行的集群的非常好的信息来源,但是我的目标是为日志/指标提供一个分析机制,而不管集群运行与否。
开始探索
如果你的系统上没有 conjure-up,首先要做的第一件事情是,请先安装它,在 Linux 上,这很简单:
sudo snap install conjure-up --classic
对于 macOS 用户也提供了 brew 包:
brew install conjure-up
你需要最新的 2.5.2 版,它的好处是添加了 CDK spell,因此,如果你的系统上已经安装了旧的版本,请使用 sudo snap refresh conjure-up 或者 brew update && brew upgrade conjure-up 去更新它。
安装完成后,运行它:
conjure-up
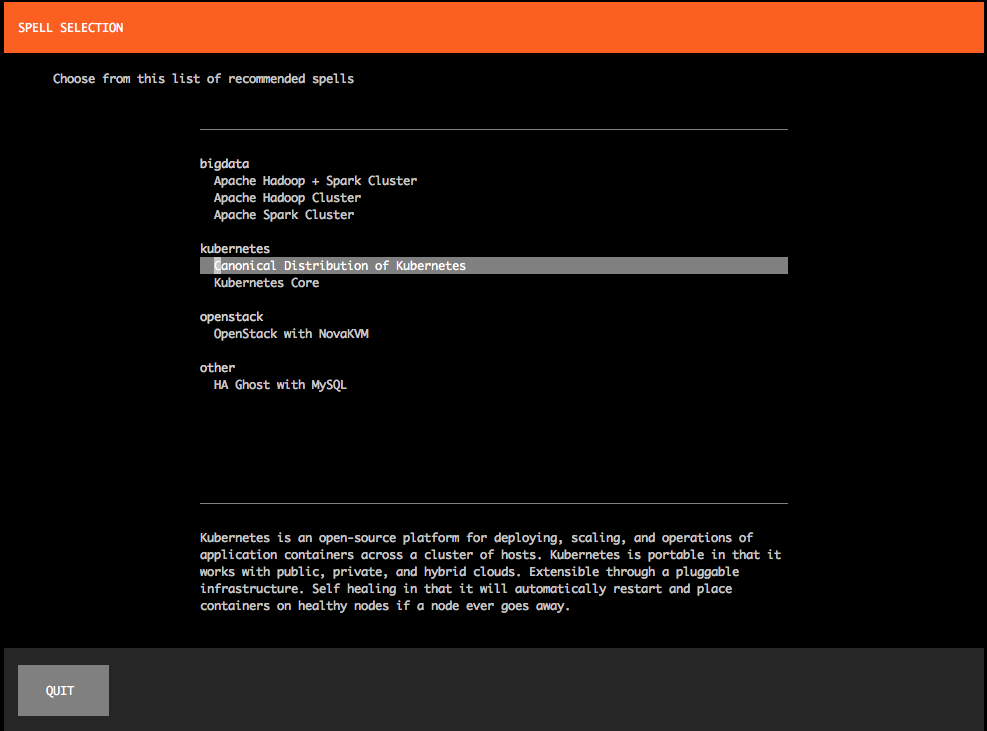
你将发现有一个 spell 列表。选择 CDK 然后按下回车。
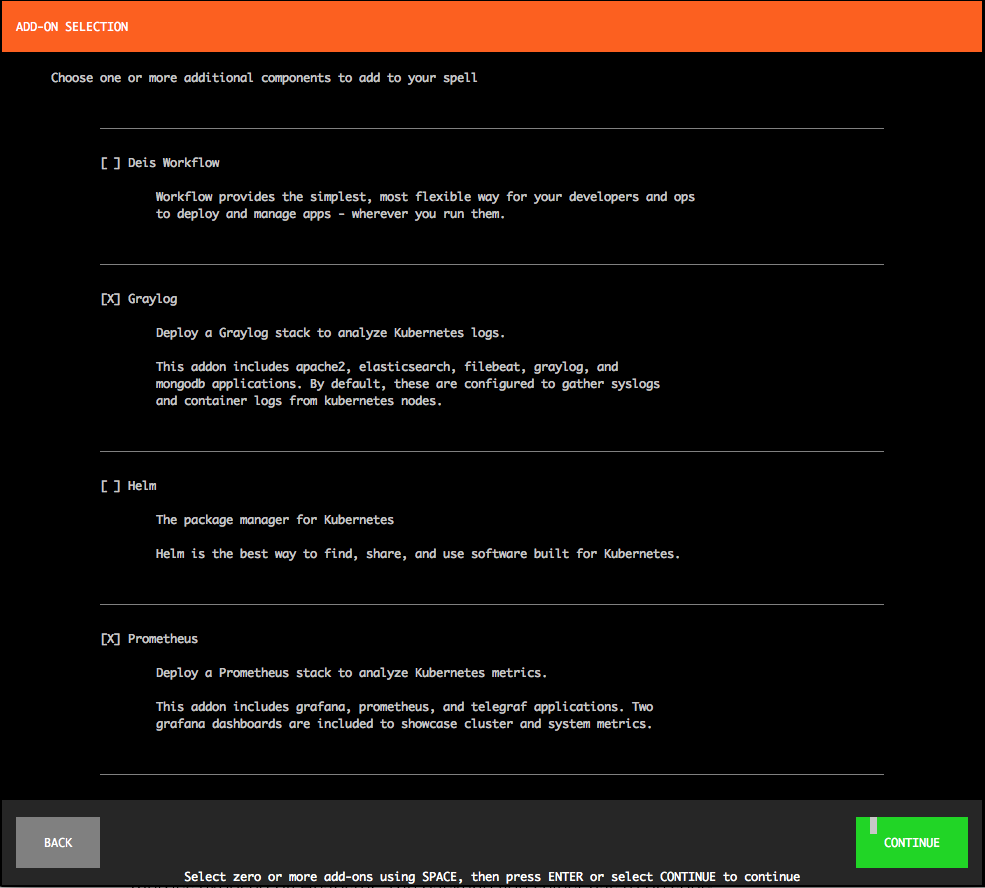
这个时候,你将看到 CDK spell 可用的附加组件。我们感兴趣的是 Graylog 和 Prometheus,因此选择这两个,然后点击 “Continue”。
它将引导你选择各种云,以决定你的集群部署的地方。之后,你将看到一些部署的后续步骤,接下来是回顾屏幕,让你再次确认部署内容:

除了典型的 K8s 相关的应用程序(etcd、flannel、load-balancer、master 以及 workers)之外,你将看到我们选择的日志和指标相关的额外应用程序。
Graylog 栈包含如下:
- apache2:graylog web 界面的反向代理
- elasticsearch:日志使用的文档数据库
- filebeat:从 K8s master/workers 转发日志到 graylog
- graylog:为日志收集器提供一个 api,以及提供一个日志分析界面
- mongodb:保存 graylog 元数据的数据库
Prometheus 栈包含如下:
- grafana:指标相关的仪表板的 web 界面
- prometheus:指标收集器以及时序数据库
- telegraf:发送主机的指标到 prometheus 中
你可以在回顾屏幕上微调部署,但是默认组件是必选 的。点击 “Deploy all Remaining Applications” 继续。
部署工作将花费一些时间,它将部署你的机器和配置你的云。完成后,conjure-up 将展示一个摘要屏幕,它包含一些链接,你可以用你的终端去浏览各种感兴趣的内容:

浏览日志
现在,Graylog 已经部署和配置完成,我们可以看一下采集到的一些数据。默认情况下,filebeat 应用程序将从 Kubernetes 的 master 和 worker 中转发系统日志( /var/log/*.log )和容器日志(/var/log/containers/*.log)到 graylog 中。
记住如下的 apache2 的地址和 graylog 的 admin 密码:
juju status --format yaml apache2/0 | grep public-address
public-address: <your-apache2-ip>
juju run-action --wait graylog/0 show-admin-password
admin-password: <your-graylog-password>
在浏览器中输入 http://<your-apache2-ip> ,然后以管理员用户名(admin)和密码(<your-graylog-password>)登入。
注意: 如果这个界面不可用,请等待大约 5 分钟时间,以便于配置的反向代理生效。
登入后,顶部的 “Sources” 选项卡可以看到从 K8s 的 master 和 workers 中收集日志的概述:

通过点击 “System / Inputs” 选项卡深入这些日志,选择 “Show received messages” 查看 filebeat 的输入:
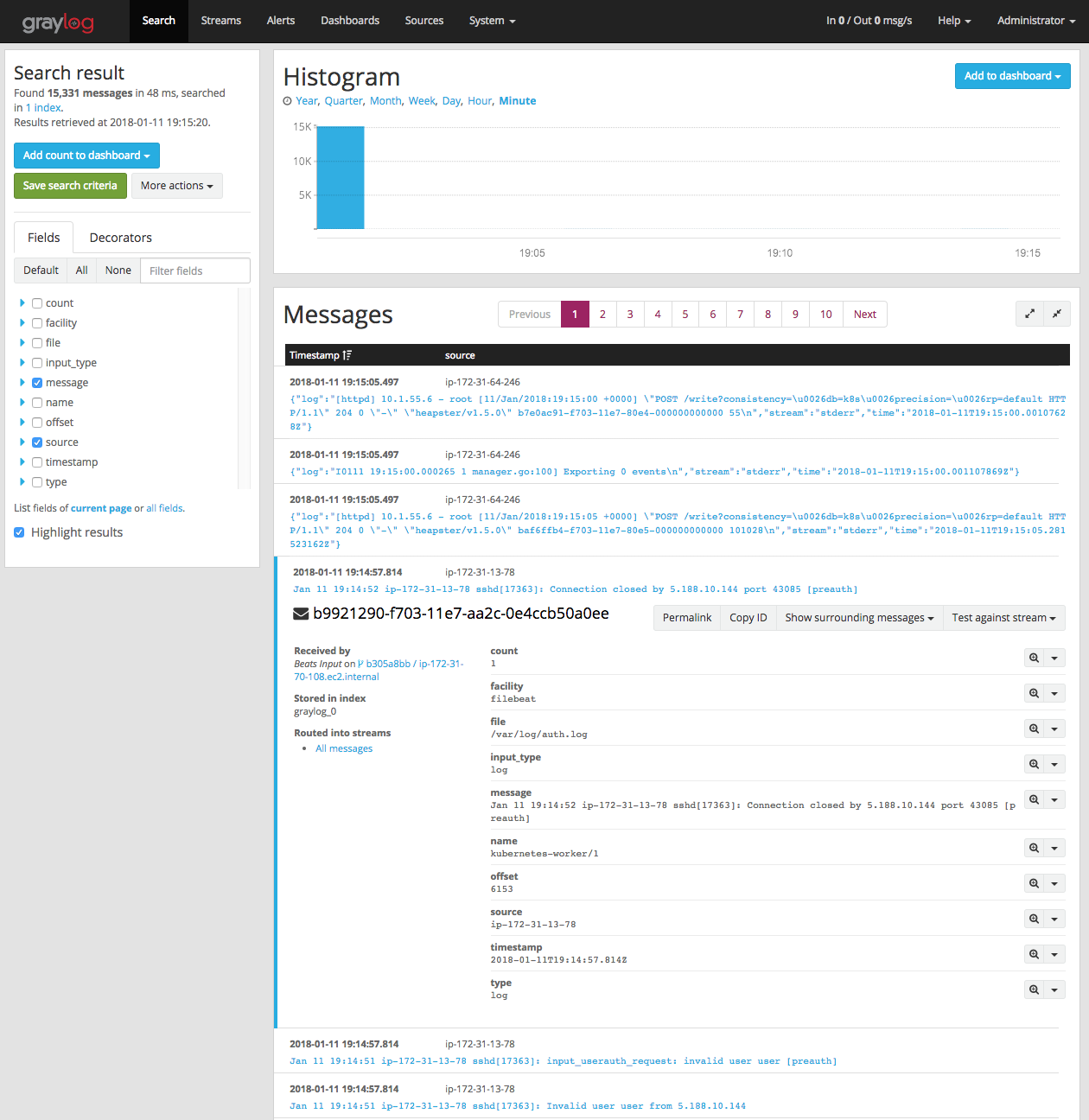
在这里,你可以应用各种过滤或者设置 Graylog 仪表板去帮助识别大多数比较重要的事件。查看 Graylog Dashboard 文档,可以了解如何定制你的视图的详细资料。
浏览指标
我们的部署通过 grafana 仪表板提供了两种类型的指标:系统指标,包括像 K8s master 和 worker 的 CPU /内存/磁盘使用情况,以及集群指标,包括像从 K8s cAdvisor 端点上收集的容器级指标。
记住如下的 grafana 的地址和 admin 密码:
juju status --format yaml grafana/0 | grep public-address
public-address: <your-grafana-ip>
juju run-action --wait grafana/0 get-admin-password
password: <your-grafana-password>
在浏览器中输入 http://<your-grafana-ip>:3000,输入管理员用户(admin)和密码(<your-grafana-password>)登入。成功登入后,点击 “Home” 下拉框,选取 “Kubernetes Metrics (via Prometheus)” 去查看集群指标仪表板:

我们也可以通过下拉框切换到 “Node Metrics (via Telegraf) ” 去查看 K8s 主机的系统指标。

另一种方法
正如在文章开始的介绍中提到的,我喜欢用 conjure-up 的向导去完成像 Kubernetes 这种复杂软件的部署。现在,我们来看一下 conjure-up 的另一种方法,你可能希望去看到实现相同结果的一些命令行的方法。还有其它的可能已经部署了前面的 CDK,并想去扩展使用上述的 Graylog/Prometheus 组件。不管什么原因你既然看到这了,既来之则安之,继续向下看吧。
支持 conjure-up 的工具是 Juju。CDK spell 所做的一切,都可以使用 juju 命令行来完成。我们来看一下,如何一步步完成这些工作。
从 Scratch 中启动
如果你使用的是 Linux,安装 Juju 很简单,命令如下:
sudo snap install juju --classic
对于 macOS,Juju 也可以从 brew 中安装:
brew install juju
现在为你选择的云配置一个控制器。你或许会被提示请求一个凭据(用户名密码):
juju bootstrap
我们接下来需要基于 CDK 捆绑部署:
juju deploy canonical-kubernetes
从 CDK 开始
使用我们部署的 Kubernetes 集群,我们需要去添加 Graylog 和 Prometheus 所需要的全部应用程序:
## deploy graylog-related applications
juju deploy xenial/apache2
juju deploy xenial/elasticsearch
juju deploy xenial/filebeat
juju deploy xenial/graylog
juju deploy xenial/mongodb
## deploy prometheus-related applications
juju deploy xenial/grafana
juju deploy xenial/prometheus
juju deploy xenial/telegraf
现在软件已经部署完毕,将它们连接到一起,以便于它们之间可以相互通讯:
## relate graylog applications
juju relate apache2:reverseproxy graylog:website
juju relate graylog:elasticsearch elasticsearch:client
juju relate graylog:mongodb mongodb:database
juju relate filebeat:beats-host kubernetes-master:juju-info
juju relate filebeat:beats-host kubernetes-worker:jujuu-info
## relate prometheus applications
juju relate prometheus:grafana-source grafana:grafana-source
juju relate telegraf:prometheus-client prometheus:target
juju relate kubernetes-master:juju-info telegraf:juju-info
juju relate kubernetes-worker:juju-info telegraf:juju-info
这个时候,所有的应用程序已经可以相互之间进行通讯了,但是我们还需要多做一点配置(比如,配置 apache2 反向代理、告诉 prometheus 如何从 K8s 中取数、导入到 grafana 仪表板等等):
## configure graylog applications
juju config apache2 enable_modules="headers proxy_html proxy_http"
juju config apache2 vhost_http_template="$(base64 <vhost-tmpl>)"
juju config elasticsearch firewall_enabled="false"
juju config filebeat \
logpath="/var/log/*.log /var/log/containers/*.log"
juju config filebeat logstash_hosts="<graylog-ip>:5044"
juju config graylog elasticsearch_cluster_name="<es-cluster>"
## configure prometheus applications
juju config prometheus scrape-jobs="<scraper-yaml>"
juju run-action --wait grafana/0 import-dashboard \
dashboard="$(base64 <dashboard-json>)"
以上的步骤需要根据你的部署来指定一些值。你可以用与 conjure-up 相同的方法得到这些:
<vhost-tmpl>: 从 github 获取我们的示例 模板<graylog-ip>:juju run --unit graylog/0 'unit-get private-address'<es-cluster>:juju config elasticsearch cluster-name<scraper-yaml>: 从 github 获取我们的示例 scraper ;[K8S_PASSWORD][20]和[K8S_API_ENDPOINT][21]substitute 的正确值<dashboard-json>: 从 github 获取我们的 主机 和 k8s 仪表板
最后,发布 apache2 和 grafana 应用程序,以便于可以通过它们的 web 界面访问:
## expose relevant endpoints
juju expose apache2
juju expose grafana
现在我们已经完成了所有的部署、配置、和发布工作,你可以使用与上面的浏览日志和浏览指标部分相同的方法去查看它们。
总结
我的目标是向你展示如何去部署一个 Kubernetes 集群,很方便地去监视它的日志和指标。无论你是喜欢向导的方式还是命令行的方式,我希望你清楚地看到部署一个监视系统并不复杂。关键是要搞清楚所有部分是如何工作的,并将它们连接到一起工作,通过断开/修复/重复的方式,直到它们每一个都能正常工作。
这里有一些像 conjure-up 和 Juju 一样非常好的工具。充分发挥这个生态系统贡献者的专长让管理大型软件变得更容易。从一套可靠的应用程序开始,按需定制,然后投入到工作中!
大胆去尝试吧,然后告诉我你用的如何。你可以在 Freenode IRC 的 #conjure-up 和 #juju 中找到像我这样的爱好者。感谢阅读!
关于作者
Kevin 在 2014 年加入 Canonical 公司,他专注于复杂软件建模。他在 Juju 大型软件团队中找到了自己的位置,他的任务是将大数据和机器学习应用程序转化成可重复的(可靠的)解决方案。
via: https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/
作者:Kevin Monroe 译者:qhwdw 校对:wxy


 );){kind=link}